Download to read offline














![M L F L O W A U T O L O G G I N G
• PyTorch auto logging with Lightning training
loop
• Model hyper-parameters like LR, model
summary, optimizer name, Min delta, Best
Score
• Early stopping and other callbacks
• Log every N iterations
• User defined metrics like F1 score, test
accuracy
• ….
from mlflow.pytorch.pytorch_autolog import autolog
parser =
LightningMNISTClassifier.add_model_specific_args(parent_par
ser=parser)
autolog() #just add this and your autologging should work!
mlflow.set_tracking_uri(dict_args['tracking_uri'])
model = LightningMNISTClassifier(**dict_args)
early_stopping = EarlyStopping(monitor="val_loss",
mode="min", verbose=True)
checkpoint_callback = ModelCheckpoint(
filepath=os.getcwd(), save_top_k=1, verbose=True,
monitor="val_loss", mode="min", prefix="",
)
lr_logger = LearningRateLogger()
trainer = pl.Trainer.from_argparse_args(
args,
callbacks=[lr_logger],
early_stop_callback=early_stopping,
checkpoint_callback=checkpoint_callback,
train_percent_check=0.1,
)
trainer.fit(model)
trainer.test()](https://image.slidesharecdn.com/66geetachauhan-201129182113/85/Reproducible-AI-Using-PyTorch-and-MLflow-16-320.jpg)

![S A V E A R T I F A C T S • Additional artifacts for model reproducibility
• For Example: vocabulary files for NLP models,
requirements.txt and other extra files for torchserve deployment
mlflow.pytorch.save_model(
model,
path=args.model_save_path,
requirements_file="requirements.txt",
extra_files=["class_mapping.json", "bert_base_uncased_vocab.txt"],
)
:param requirements_file: An (optional) string containing the path to requirements file.
If ``None``, no requirements file is added to the model.
:param extra_files: An (optional) list containing the paths to corresponding extra files.
For example, consider the following ``extra_files`` list::
extra_files = ["s3://my-bucket/path/to/my_file1",
"s3://my-bucket/path/to/my_file2"]
In this case, the ``"my_file1 & my_file2"`` extra file is downloaded from S3.
If ``None``, no extra files are added to the model.](https://image.slidesharecdn.com/66geetachauhan-201129182113/85/Reproducible-AI-Using-PyTorch-and-MLflow-18-320.jpg)
![T O R C H S C R I P T E D M O D E L
• Log TorchScripted model
• Serialize and Optimize models for python-free
process
• Recommended for production inference
mlflow.set_tracking_uri(dict_args["tracking_uri"])
model = LightningMNISTClassifier(**dict_args)
# Convert to TorchScripted model
scripted_model = torch.jit.script(model)
mlflow.start_run()
# Log the scripted model using log_model
mlflow.pytorch.log_model(scripted_model, "scripted_model")
# If you need to reload the model just call load_model
uri_path = mlflow.get_artifact_uri()
scripted_loaded_model =
mlflow.pytorch.load_model(os.path.join(uri_path,
"scripted_model"))
mlflow.end_run()](https://image.slidesharecdn.com/66geetachauhan-201129182113/85/Reproducible-AI-Using-PyTorch-and-MLflow-19-320.jpg)

![D E P L O Y M E N T P L U G I N
New TorchServe Deployment Plugin
Test models during development cycle, pull
models from MLflow Model repository and run
• CLI
• Run with Local vs remote TorchServe
• Python API
mlflow deployments predict --name mnist_test --target
torchserve --input_path sample.json --output_path
output.json
import os
import matplotlib.pyplot as plt
from torchvision import transforms
from mlflow.deployments import get_deploy_client
img = plt.imread(os.path.join(os.getcwd(), "test_data/one.png"))
mnist_transforms = transforms.Compose([
transforms.ToTensor()
])
image = mnist_transforms(img)
plugin = get_deploy_client("torchserve")
config = {
'MODEL_FILE': "mnist_model.py",
'HANDLER_FILE': 'mnist_handler.py'
}
plugin.create_deployment(name="mnist_test",
model_uri="mnist_cnn.pt", config=config)
prediction = plugin.predict("mnist_test", image)](https://image.slidesharecdn.com/66geetachauhan-201129182113/85/Reproducible-AI-Using-PyTorch-and-MLflow-21-320.jpg)









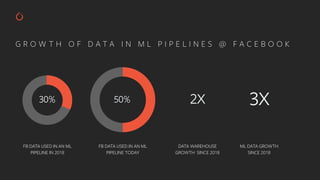
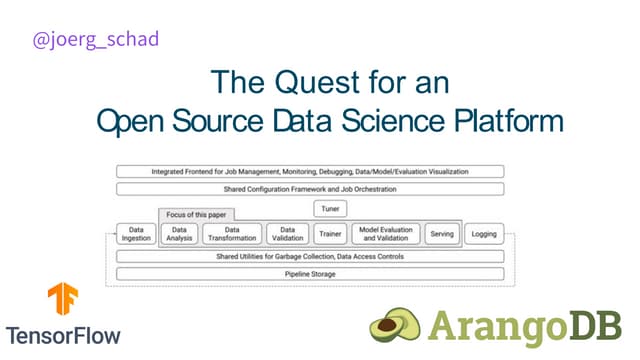
The document discusses the integration of PyTorch and MLflow for reproducible AI, highlighting the growth of the PyTorch community and challenges in maintaining reproducibility in machine learning research. It outlines solutions offered by MLflow, including model management, experiment tracking, and deployment capabilities for machine learning models. Additionally, it emphasizes the need for comprehensive repositories that contain necessary dependencies, training scripts, and evaluation methods to ensure reproducibility in AI workflows.















![[AI] ML Operationalization with Microsoft Azure](https://cdn.slidesharecdn.com/ss_thumbnails/wds-mlops-trainer-kyle-akepanidtaworn-v03-190924094657-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)

