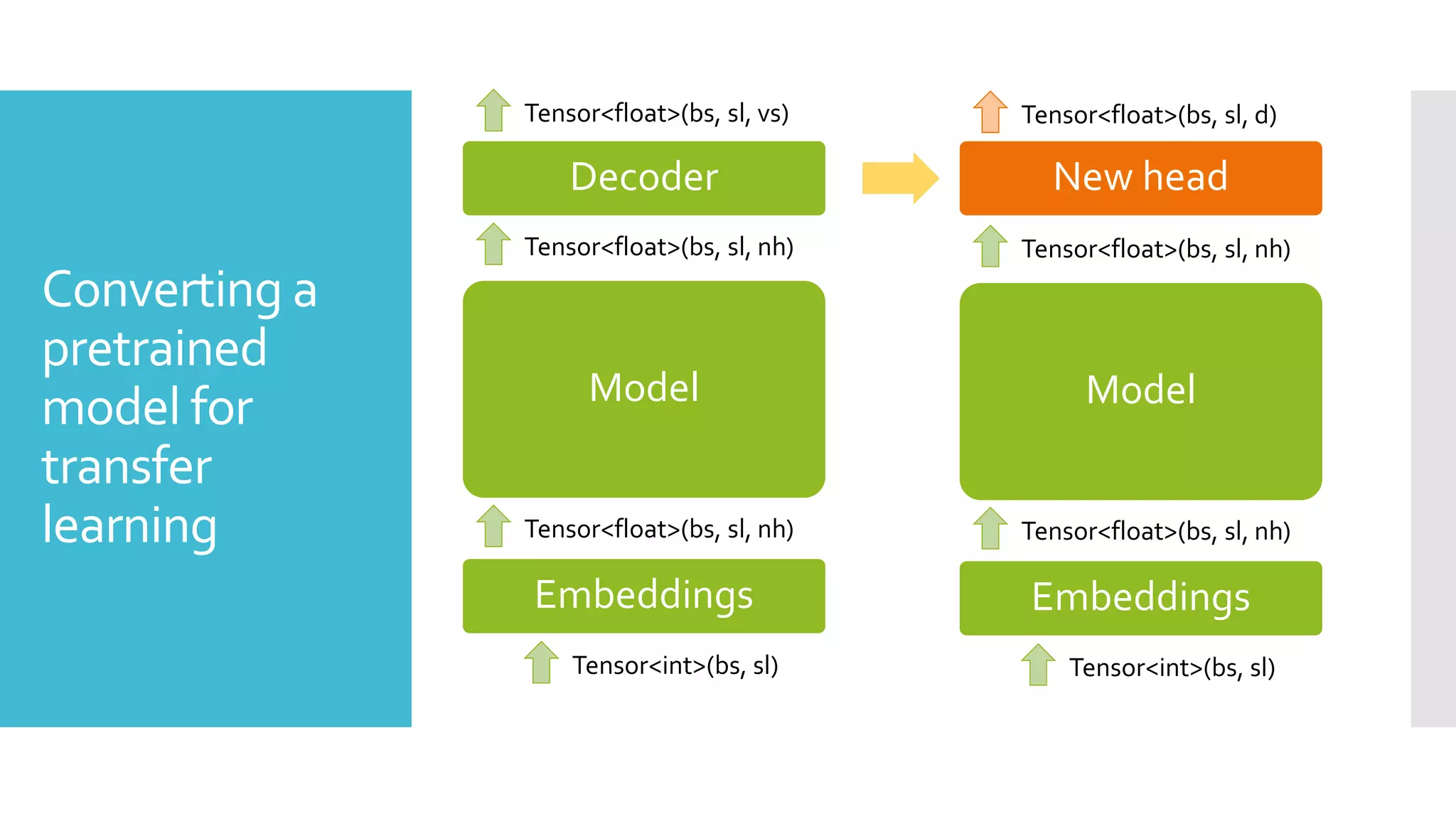
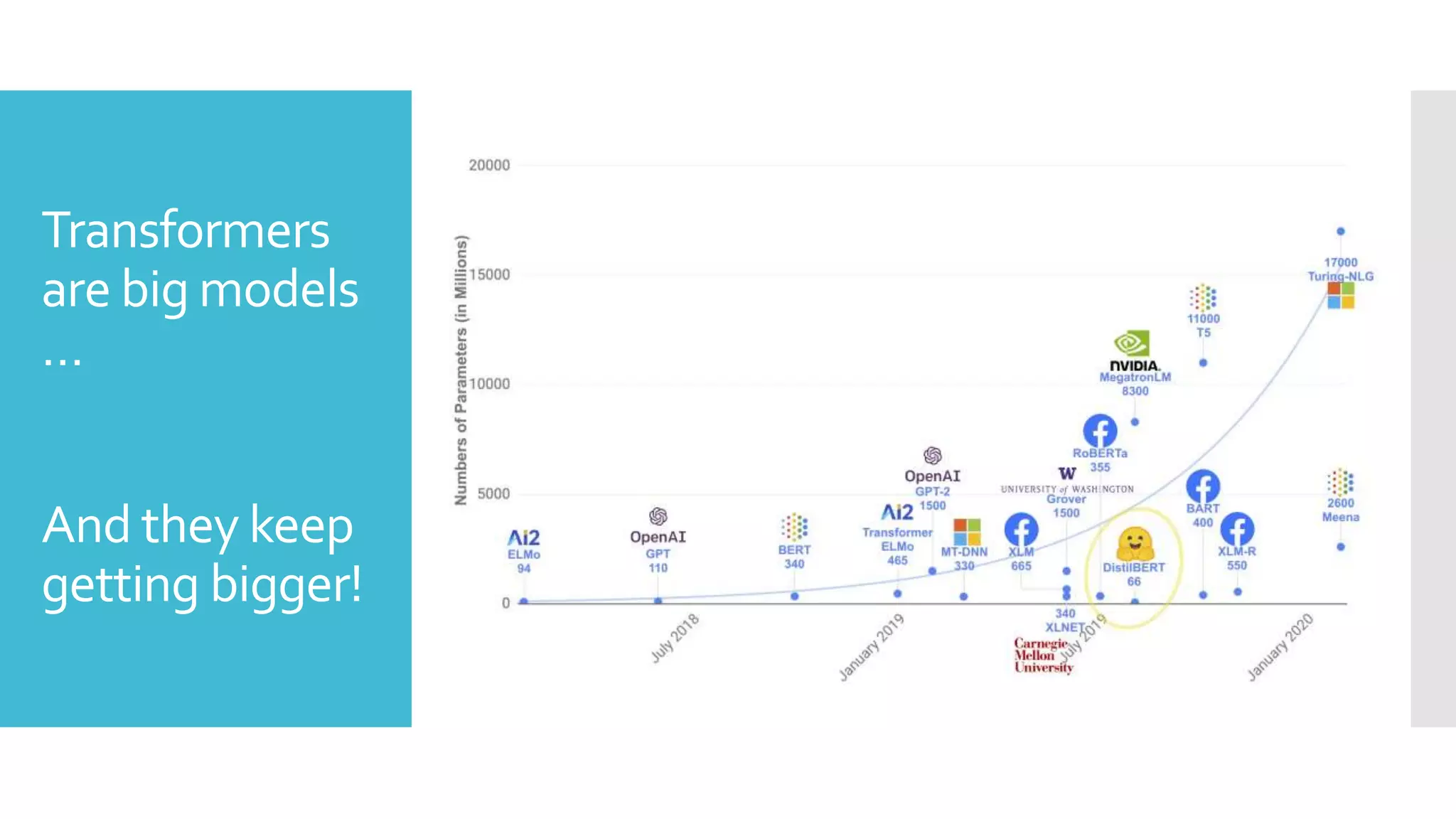
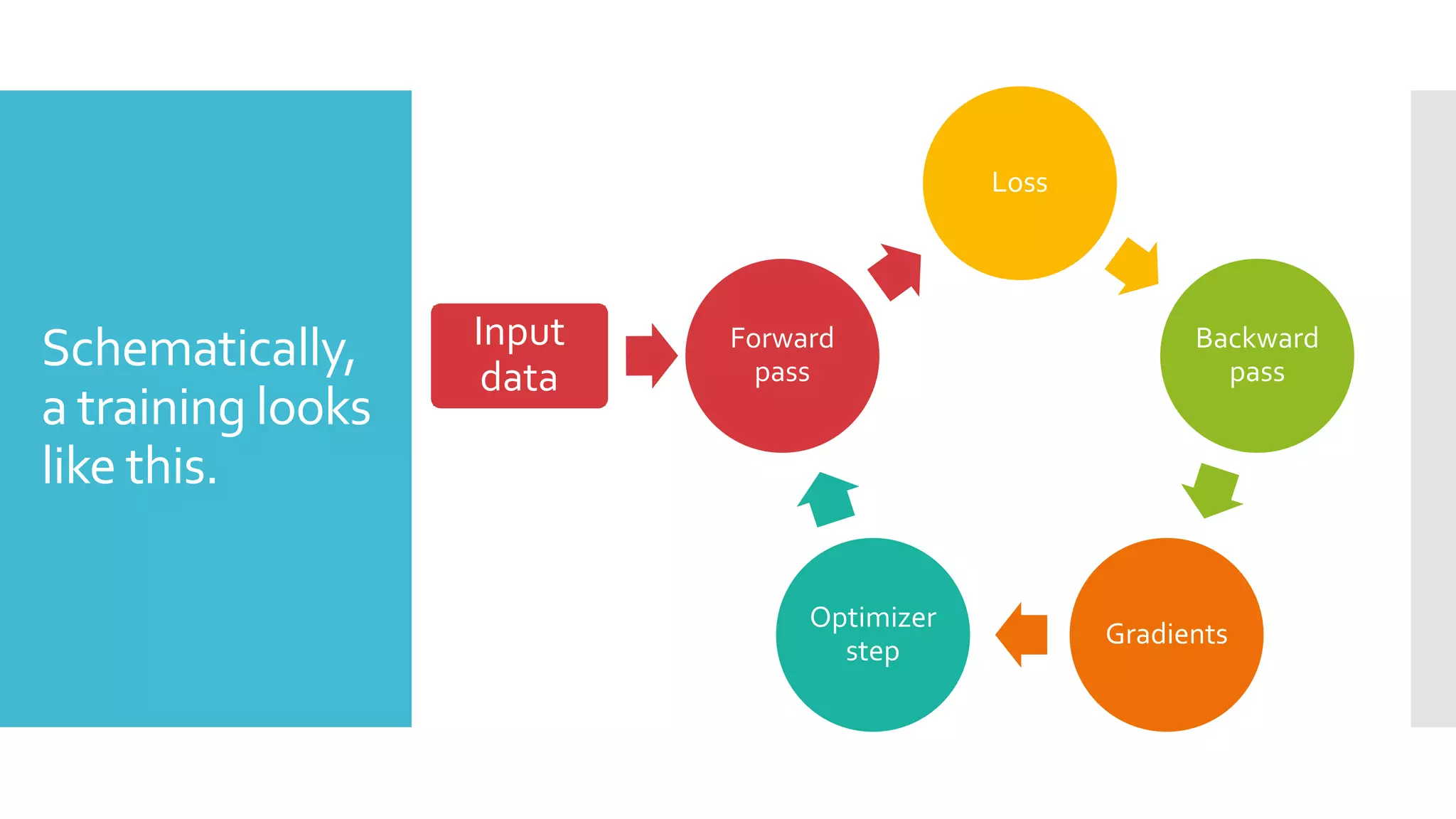
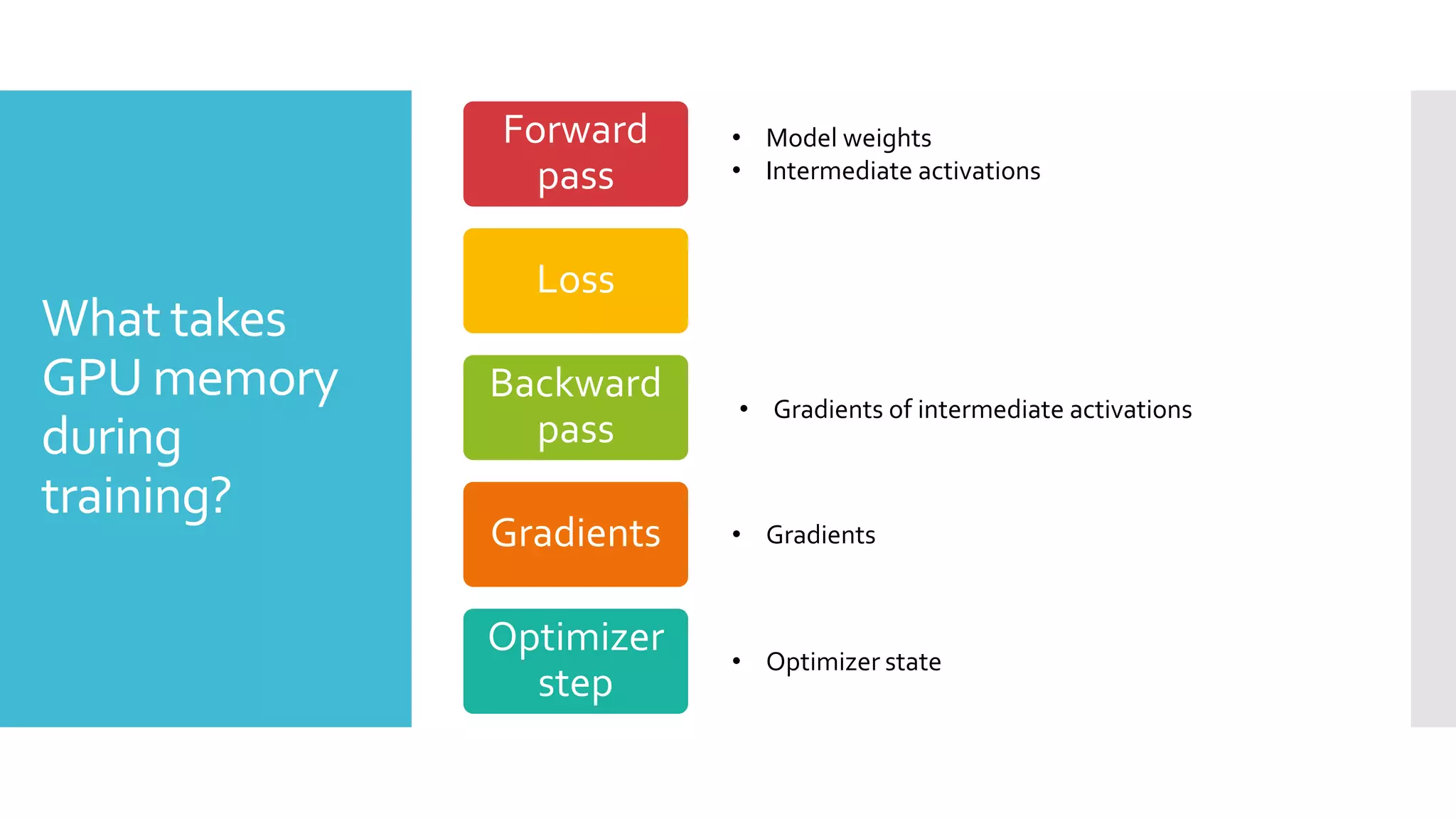
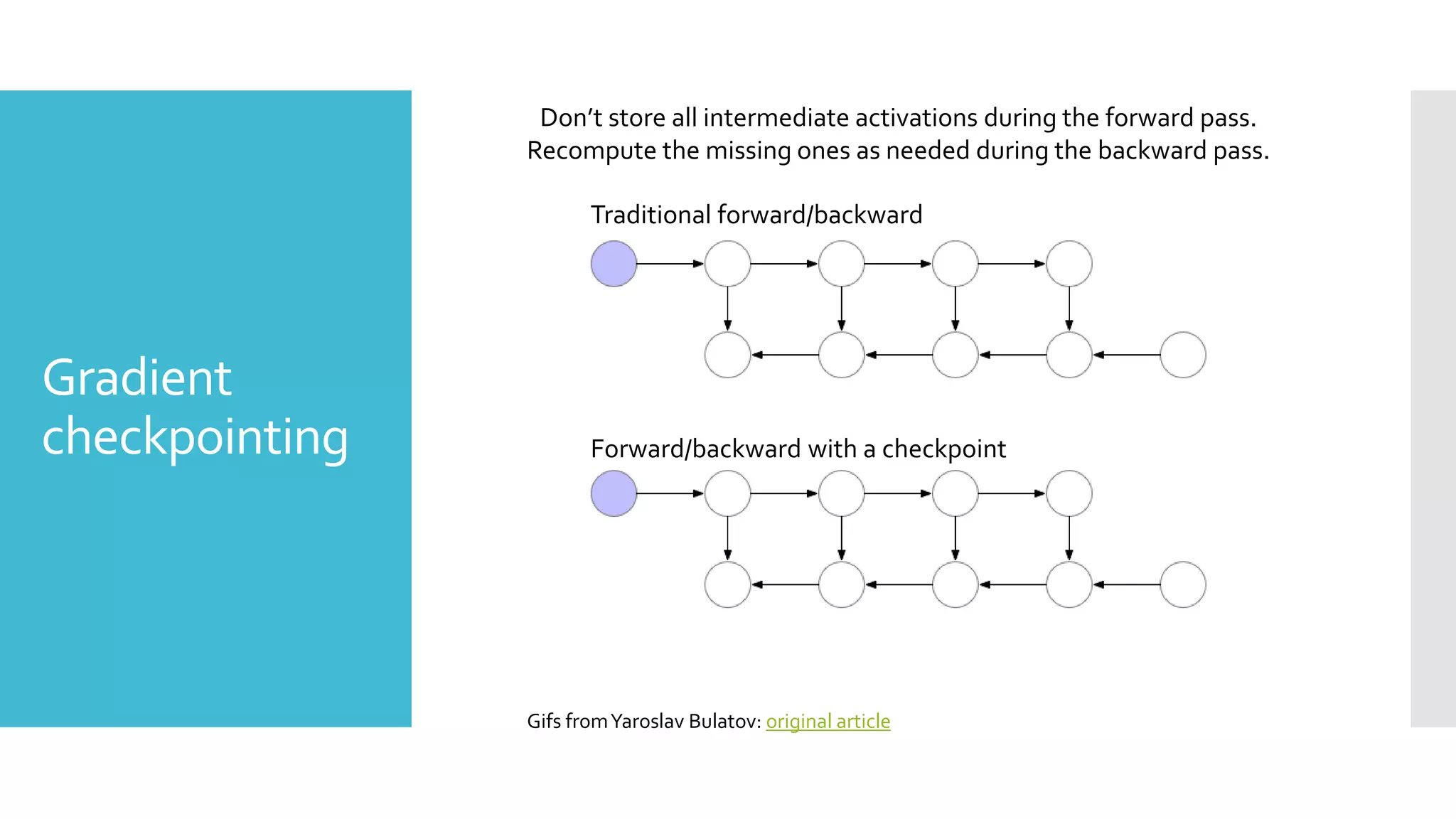
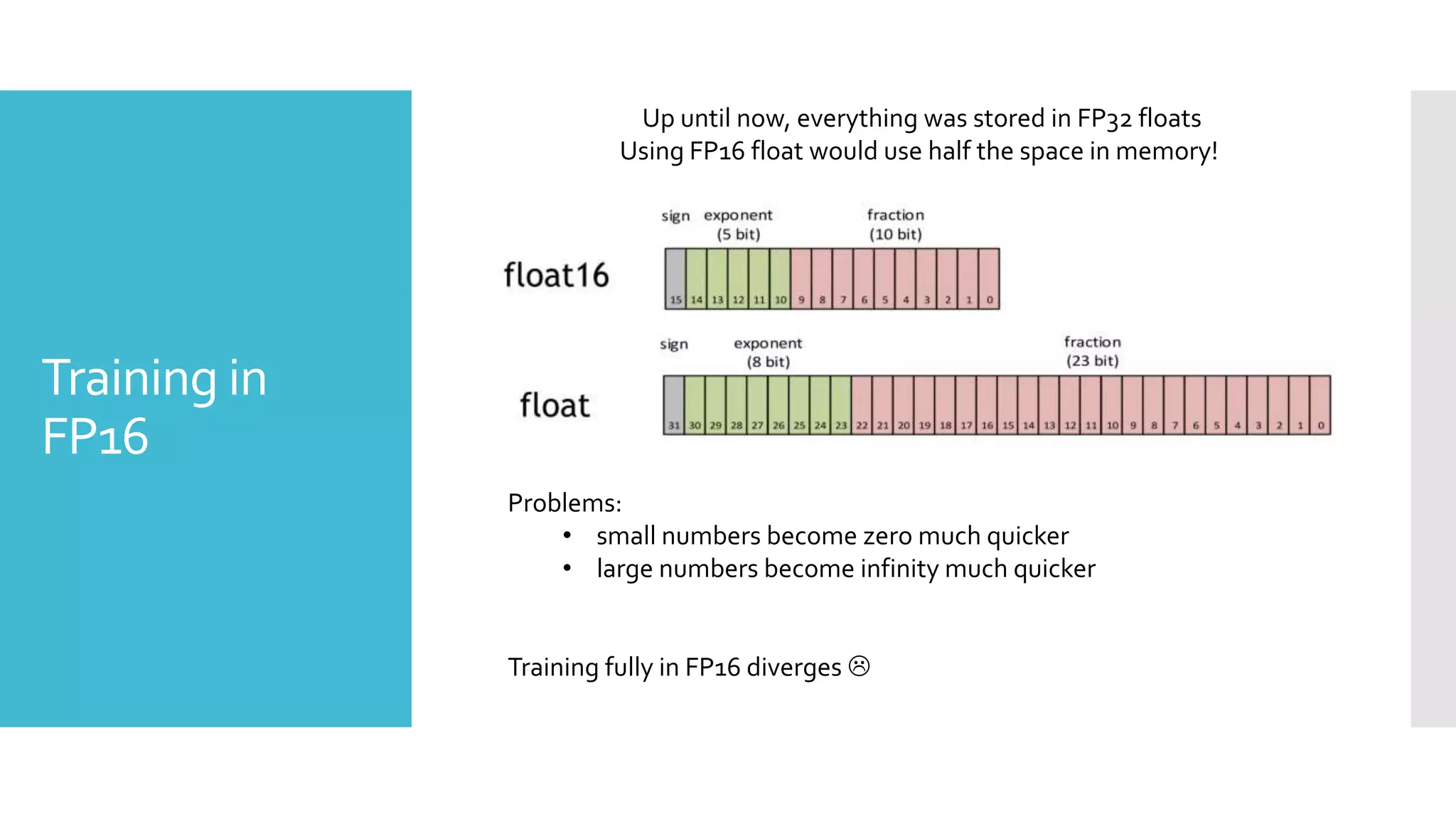
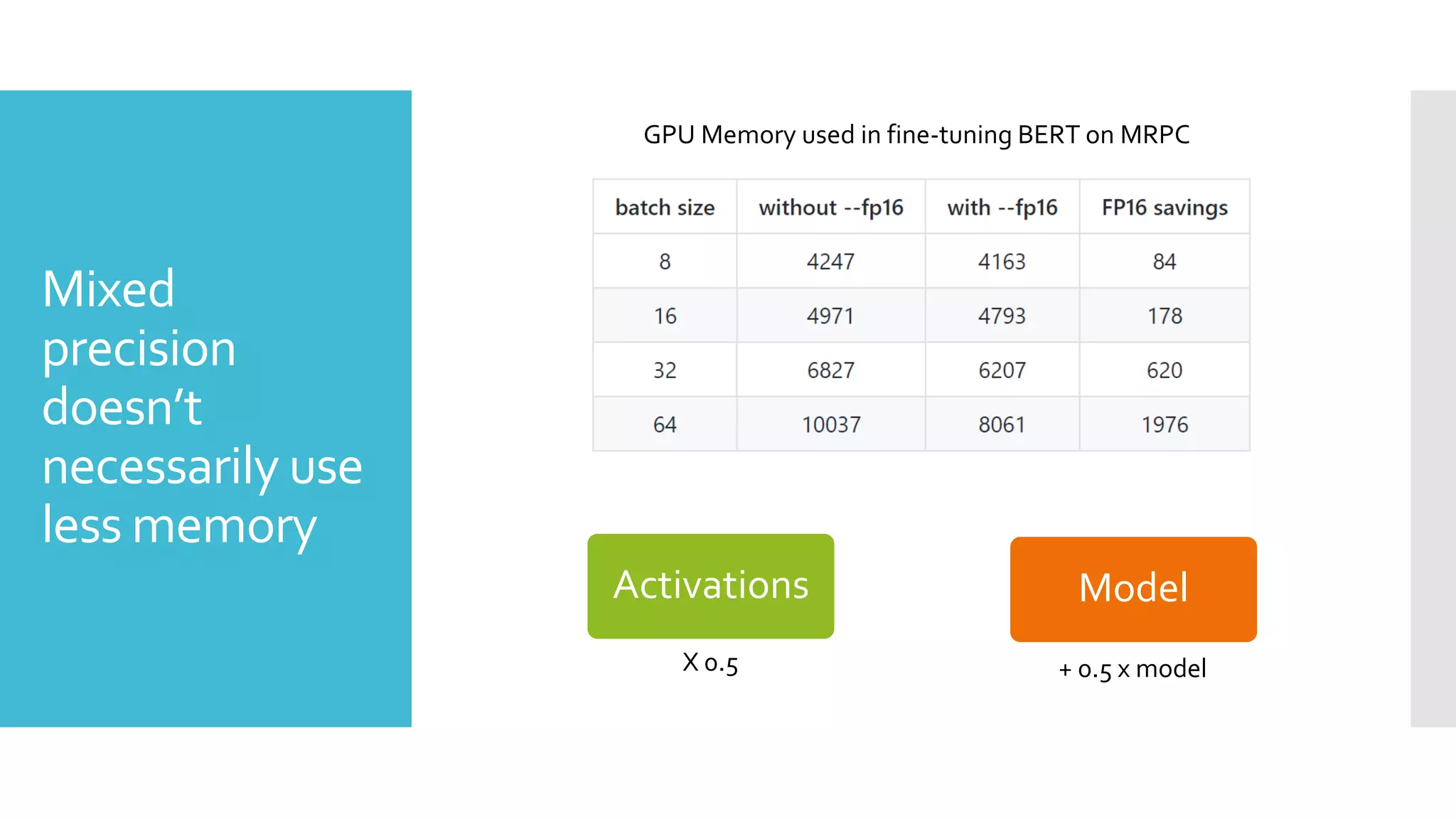
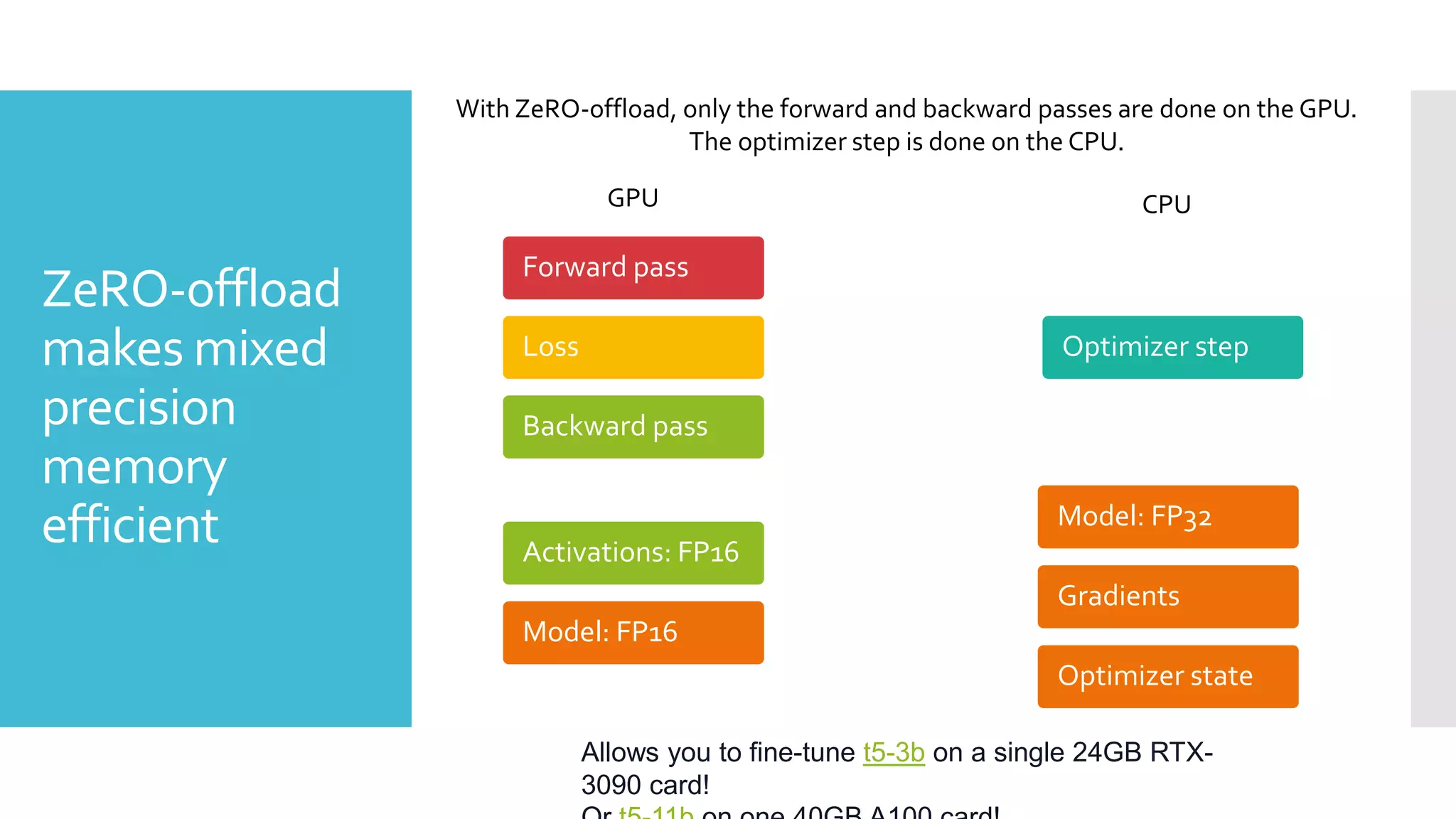
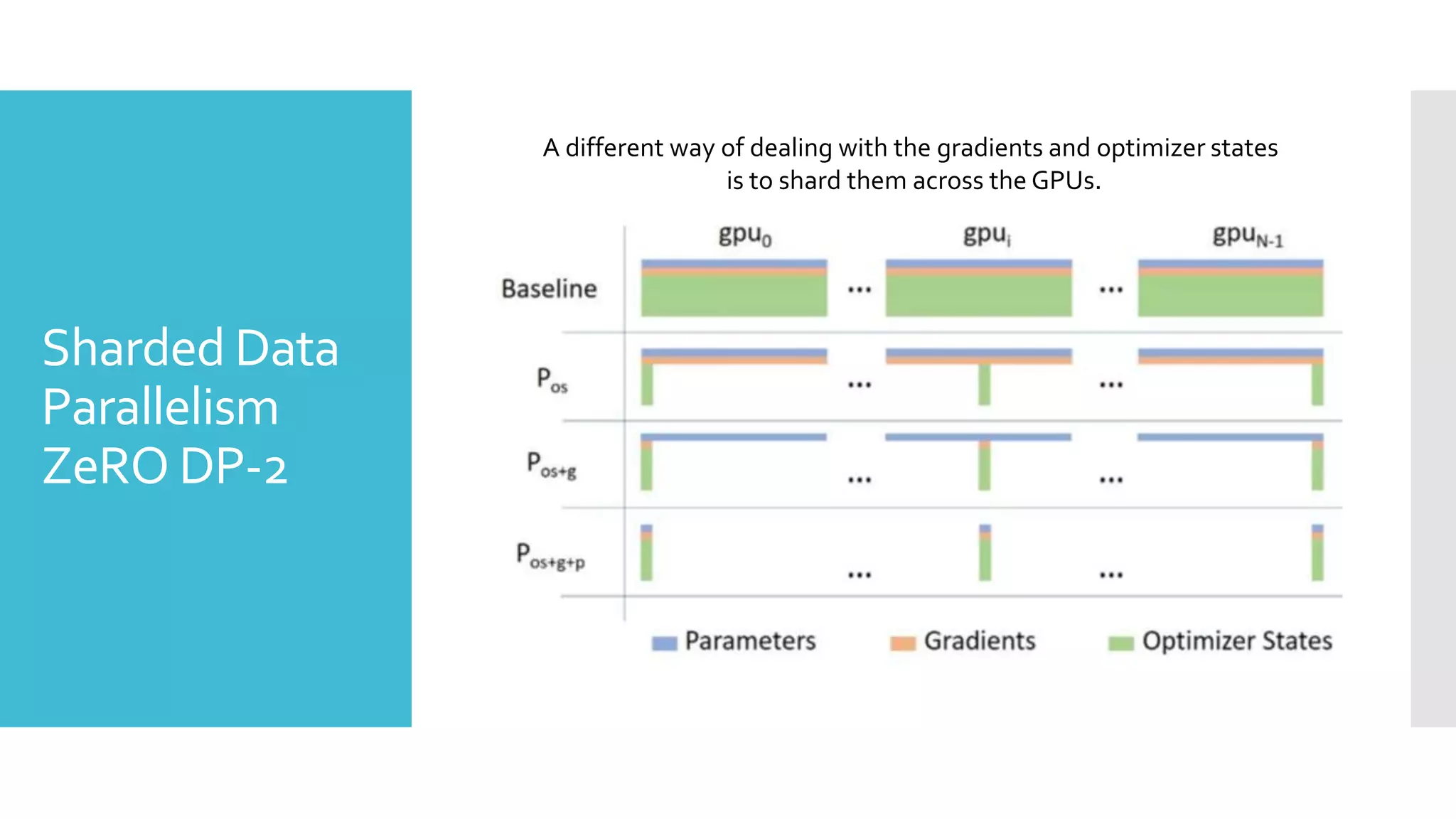
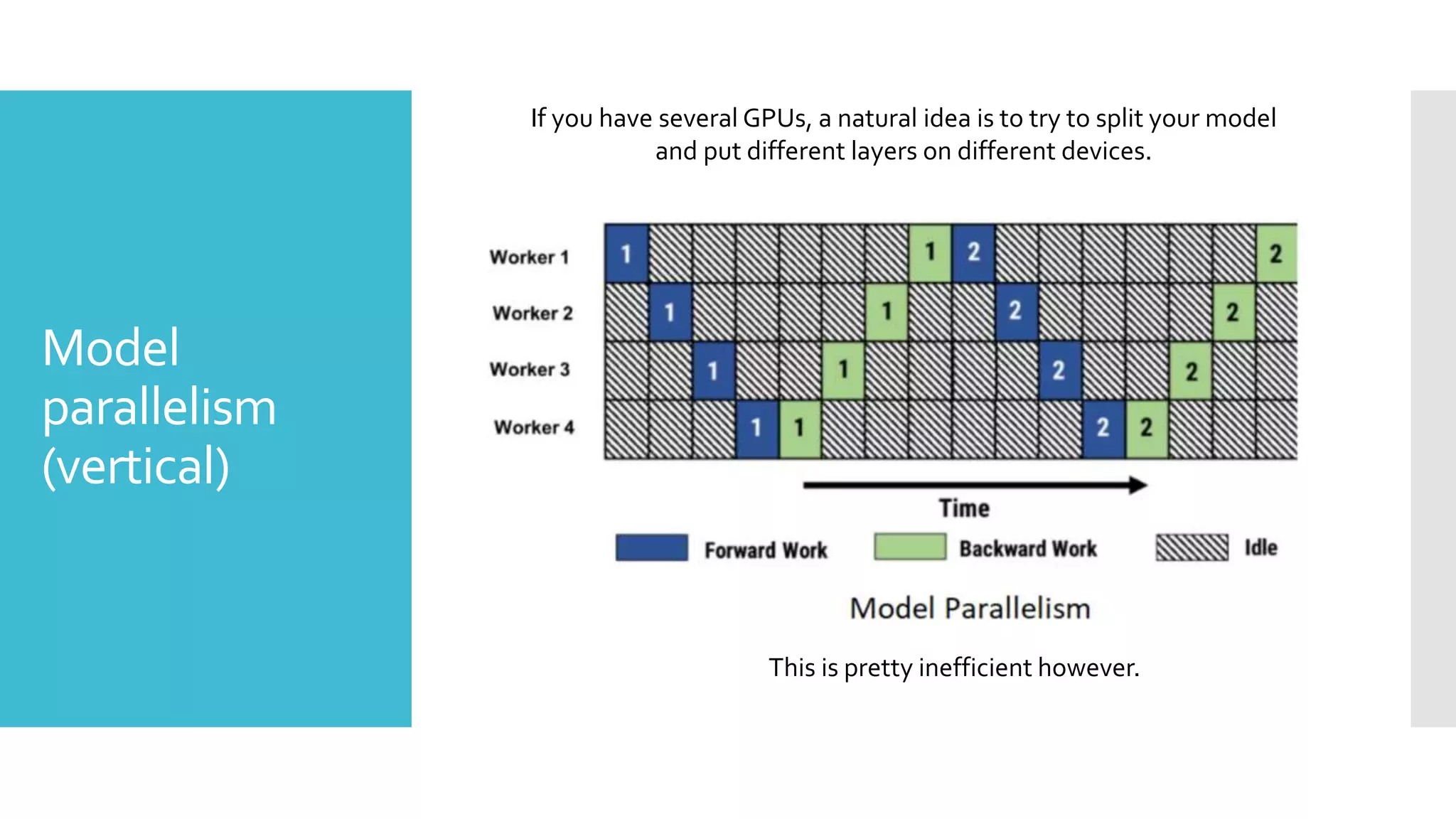
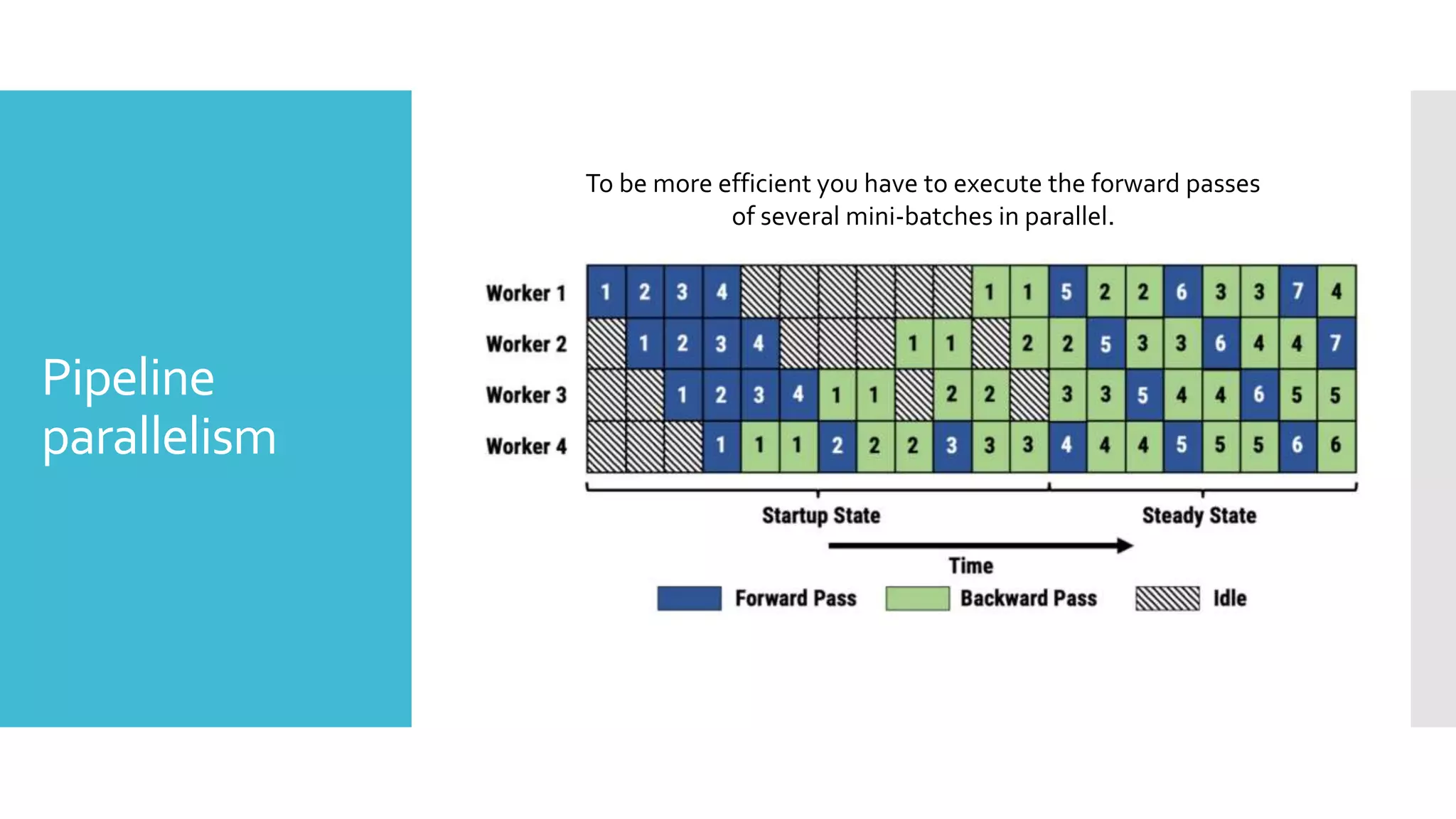
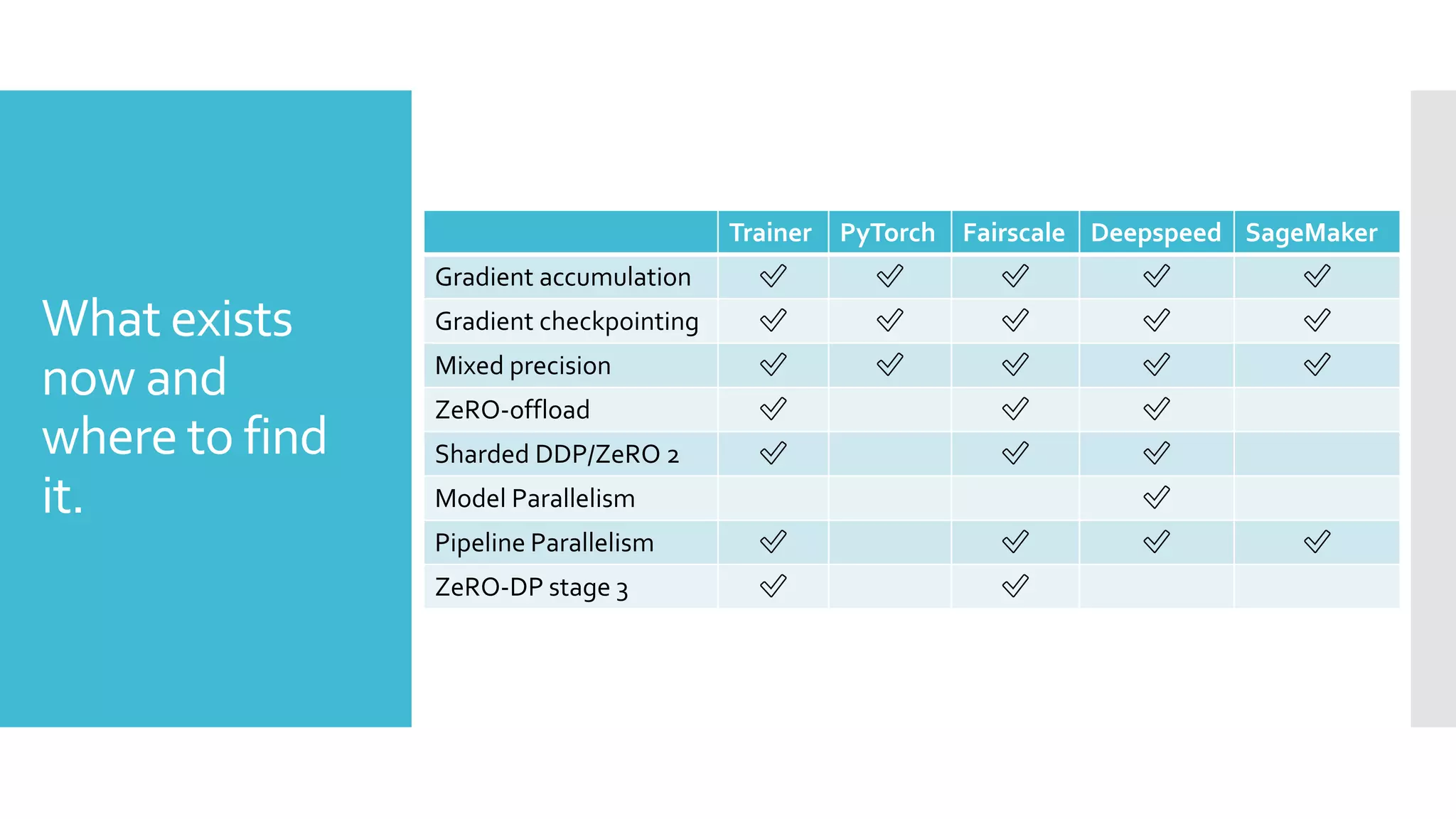
This document discusses techniques for fine-tuning large pre-trained language models without access to a supercomputer. It describes the history of transformer models and how transfer learning works. It then outlines several techniques for reducing memory usage during fine-tuning, including reducing batch size, gradient accumulation, gradient checkpointing, mixed precision training, and distributed data parallelism approaches like ZeRO and pipelined parallelism. Resources for implementing these techniques are also provided.



![Examples of
language
models
pretraining
objectives
My
My
My
My
name
name
name
is
is Sylvain
name
is
Sylvain
.
Guess the next word in the sentence (GPT)
My [mask] is Sylvain .
name
Guess some masked words in the sentence (BERT)](https://image.slidesharecdn.com/fine-tuninglarge-210225220455/75/Fine-tuning-large-LMs-6-2048.jpg)