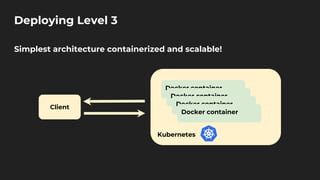
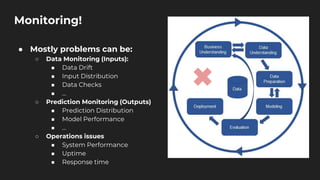
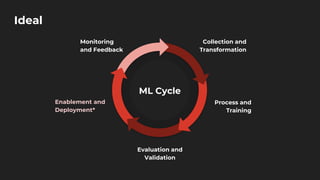
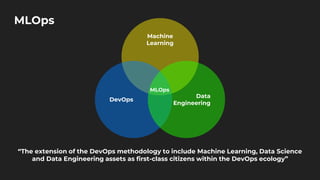
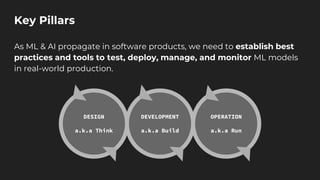
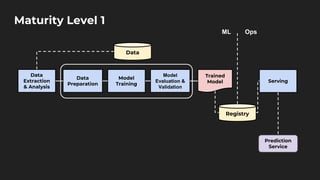
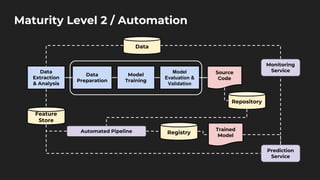
The document discusses moving from data science to MLOps. It defines MLOps as extending DevOps methodology to include machine learning, data science, and data engineering assets. Key concepts of MLOps include iterative development, automation, continuous integration and delivery, versioning, testing, reproducibility, monitoring, source control, and model/feature stores. MLOps helps address challenges of moving models to production like the deployment gap by establishing best practices and tools for testing, deploying, managing, and monitoring models.









![The MLOps Tech Stack
MLOps Setup Components Tools
Data Analysis Python, Pandas
Source Control Git
Test & Build Services PyTest & Make
Deployment Services Git, DVC
Model & Dataset Registry DVC[aws s3]
Feature Store Feast
ML Metadata Store DVC
ML Pipeline Orchestrator Airflow](https://image.slidesharecdn.com/fromdsctomlops-210513143852/85/From-Data-Science-to-MLOps-15-320.jpg)