Download as PDF, PPTX


![Data Modeling
Algorithmic Modeling
Principles
Experiences
Conclusions
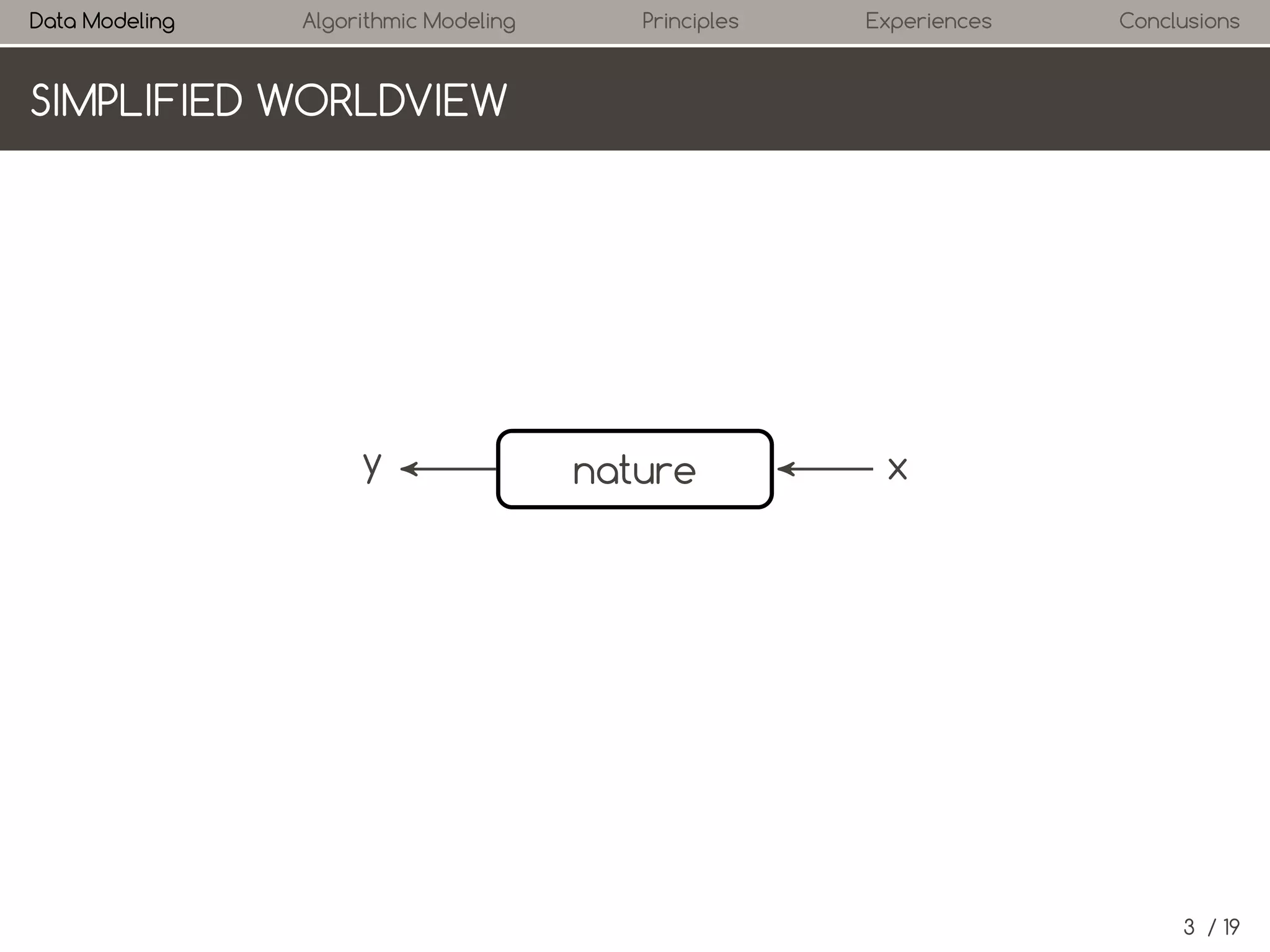
OUTLINE
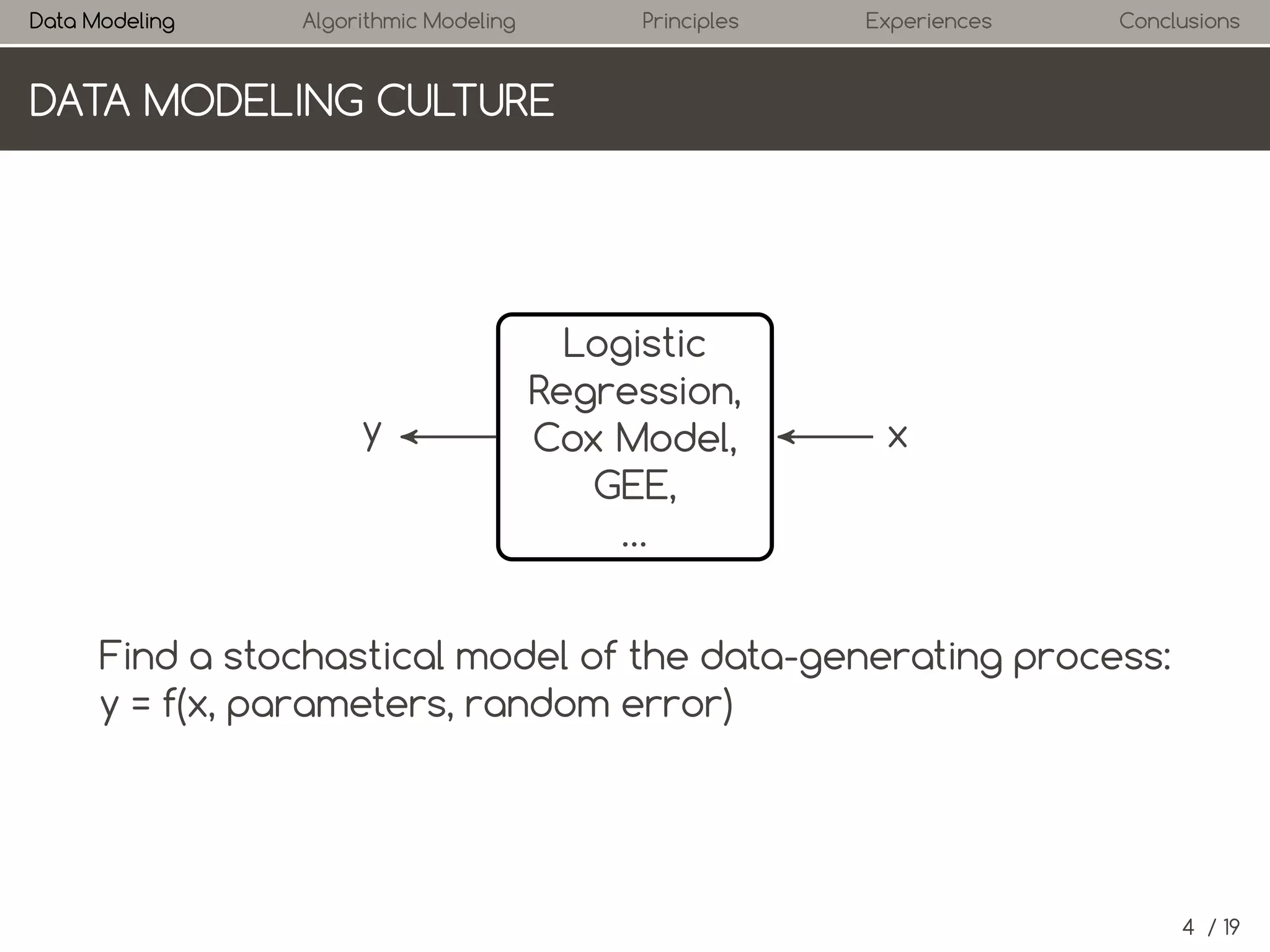
1. Statistics: Data Modeling Culture
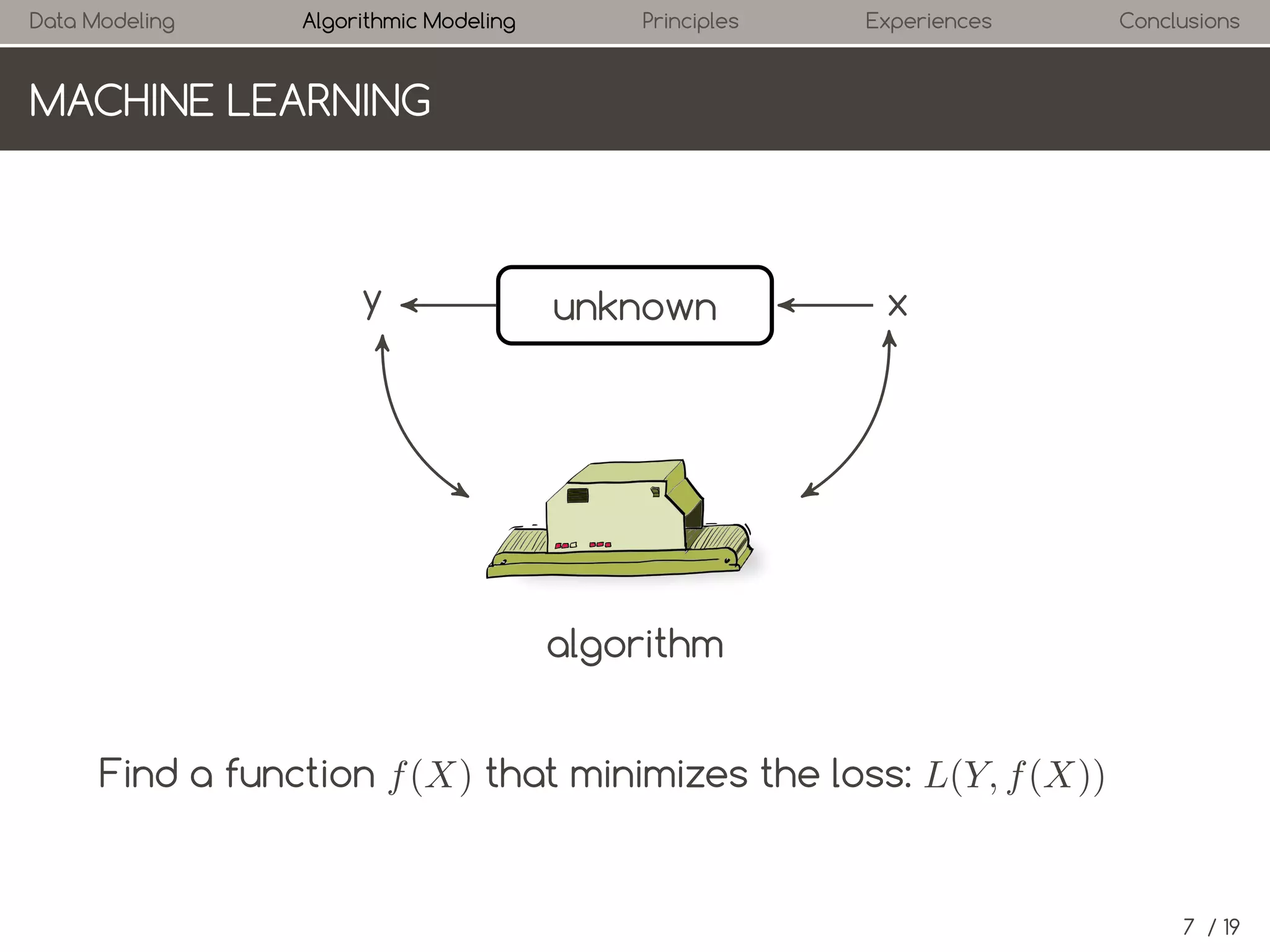
2. Machine Learning: Algorithmic Modeling Culture
3. Statistical Learning Principles
4. Personal Experience
5. Summary
Content heavily based on: ``Statistical Modeling: The two cultures''
from Leo Breiman [1]
1 / 19](https://image.slidesharecdn.com/presentation-140120075829-phpapp02/75/Statistical-Modeling-The-Two-Cultures-3-2048.jpg)
![2014-01-20
.
.
Statistical Modeling: The Two Cultures
OUTLINE
1. Statistics: Data Modeling Culture
2. Machine Learning: Algorithmic Modeling Culture
3. Statistical Learning Principles
4. Personal Experience
Outline
5. Summary
.
Content heavily based on: ``Statistical Modeling: The two cultures''
from Leo Breiman [1]
.
This presentation is based on ``Statistical Modeling: The two
cultures'' from Leo Breiman [1].
The first segment introduces the data modeling culture and
analogously the second segment explains the algorithmic
modeling culture together with the presentation of three
algorithms. The part about statistical learning principals
presents aspects which help to compare both of cultures.
Personal experiences in both cultures are addressed. The
conclusion summarizes the message of the paper [1].](https://image.slidesharecdn.com/presentation-140120075829-phpapp02/75/Statistical-Modeling-The-Two-Cultures-4-2048.jpg)









![Data Modeling
Algorithmic Modeling
Principles
Experiences
Conclusions
ALGORITHM IN MACHINE LEARNING
→ Boosting
→ Support Vector Machines
→ Artificial neural networks
→ Random Forests
→ Hidden Markov
→ Bayes-Nets
→ …1
1
Details and more algorithms in ``Elements of statistical learning''[2]
8 / 19](https://image.slidesharecdn.com/presentation-140120075829-phpapp02/75/Statistical-Modeling-The-Two-Cultures-17-2048.jpg)
![2014-01-20
.
.
Statistical Modeling: The Two Cultures
ALGORITHM IN MACHINE LEARNING
→ Boosting
Algorithmic Modeling
→ Support Vector Machines
→ Artificial neural networks
→ Random Forests
→ Hidden Markov
→ Bayes-Nets
Algorithm in Machine Learning
→ …1
.
1
Details and more algorithms in ``Elements of statistical learning''[2]
.
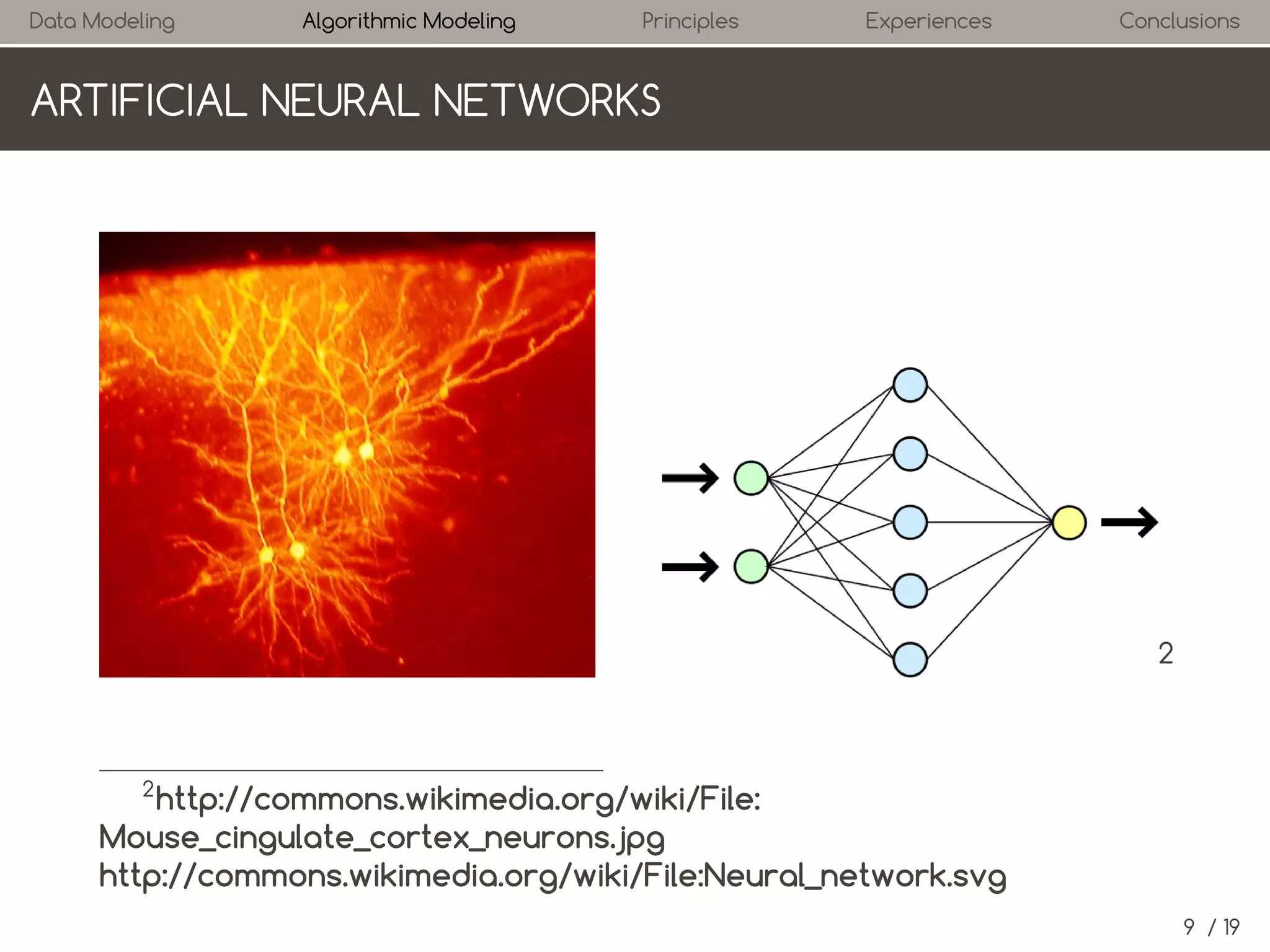
The algorithms used in machine learning are motivated
differently. Three algorithms are presented in short.](https://image.slidesharecdn.com/presentation-140120075829-phpapp02/75/Statistical-Modeling-The-Two-Cultures-18-2048.jpg)










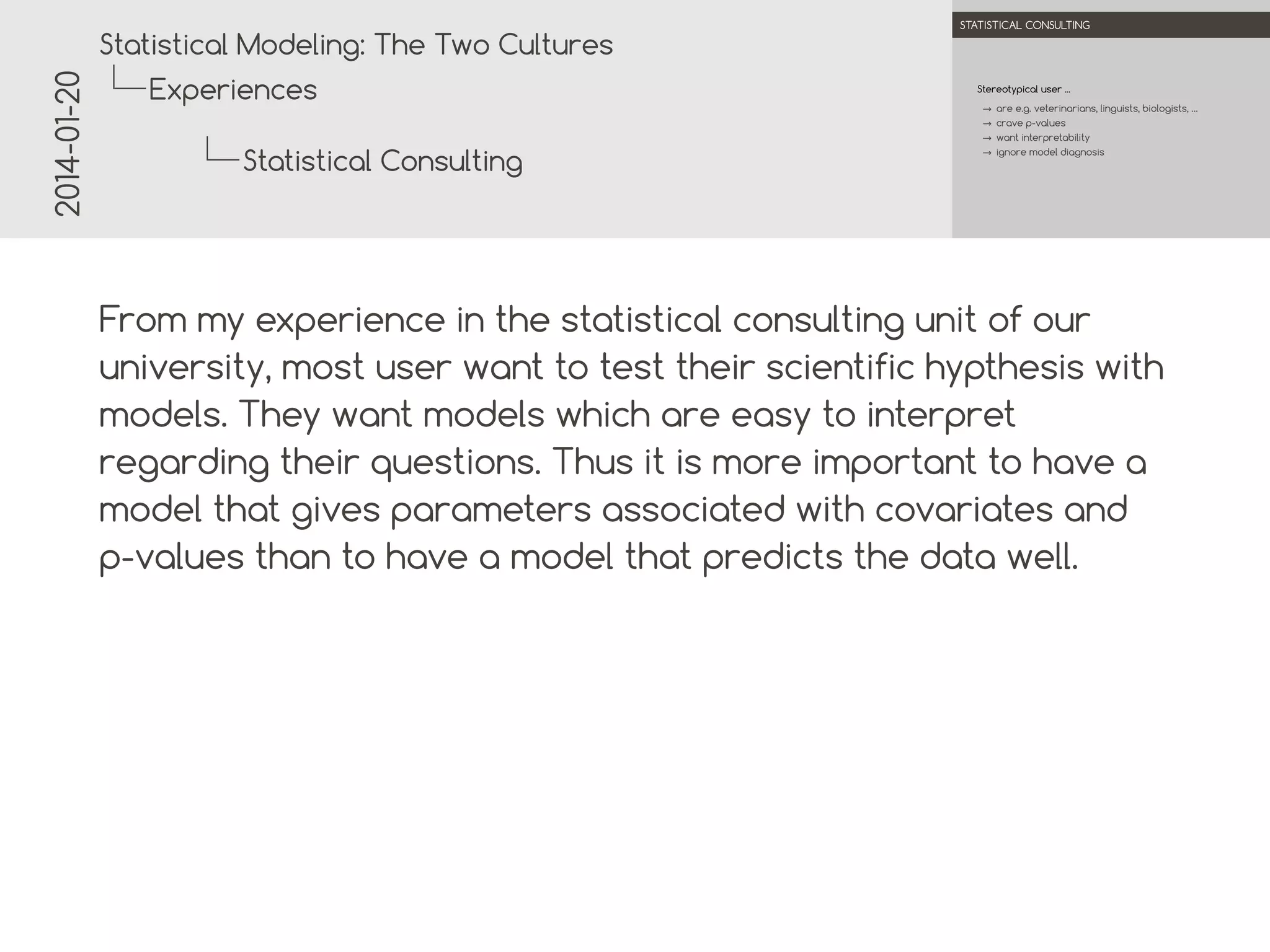


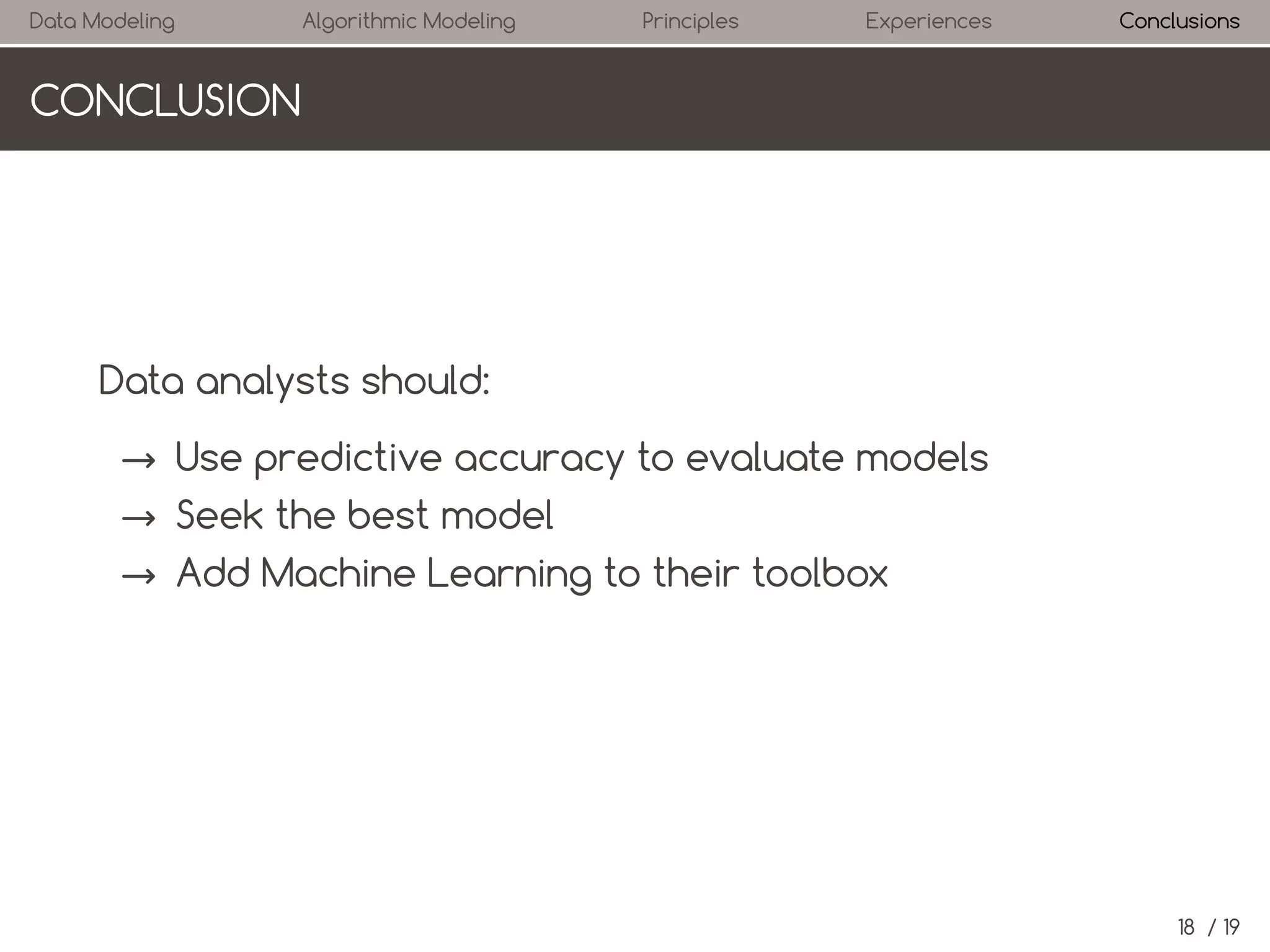



This document discusses two cultures of statistical modeling: data modeling, focused on understanding the underlying data-generating mechanisms, and algorithmic modeling, which emphasizes optimization and predictive accuracy. It highlights the limitations of traditional data modeling and advocates for the increased use of algorithmic methods in statistics, particularly in machine learning. The conclusion suggests that data analysts should prioritize predictive accuracy and incorporate machine learning techniques into their practices.























































































