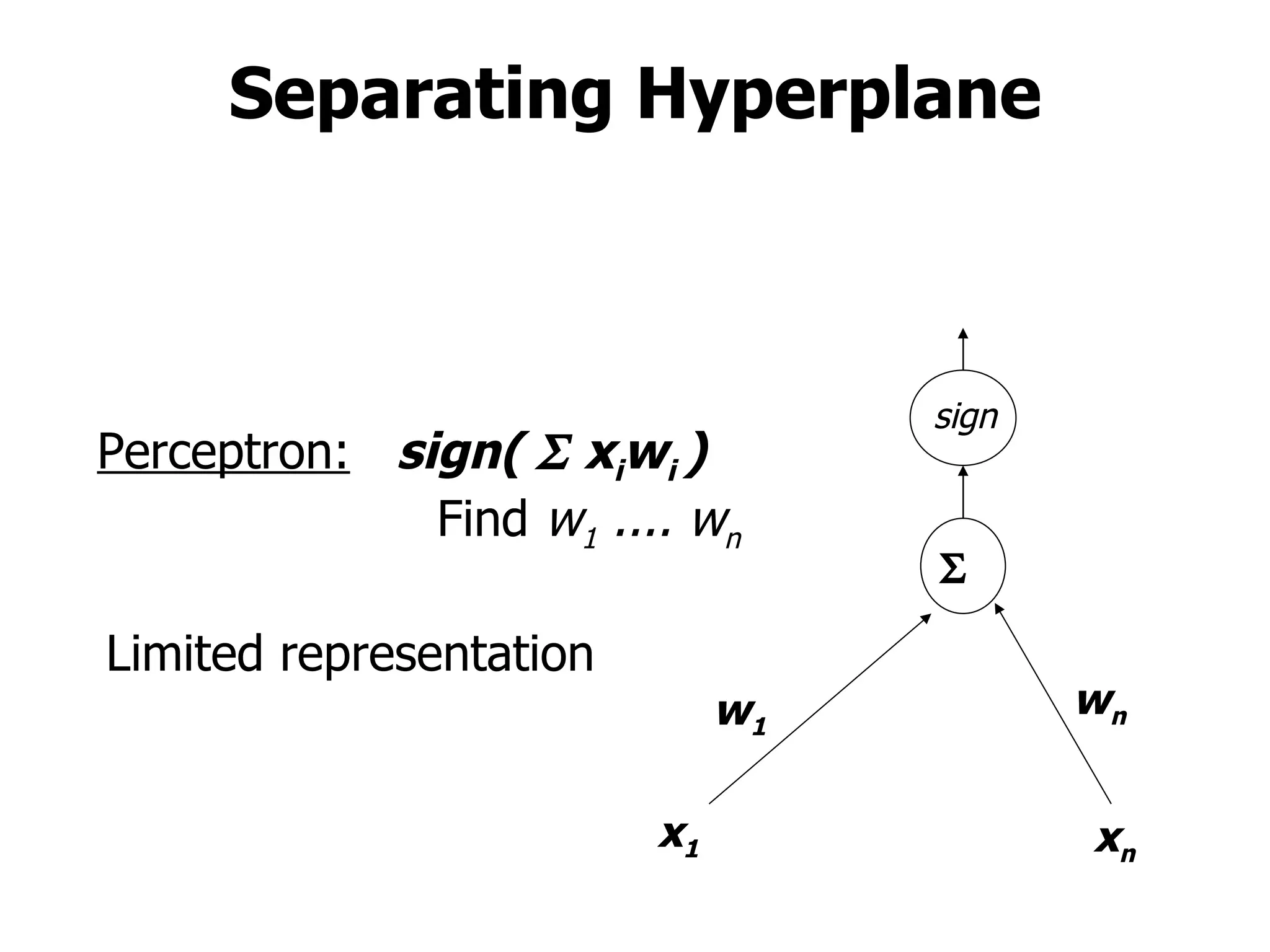
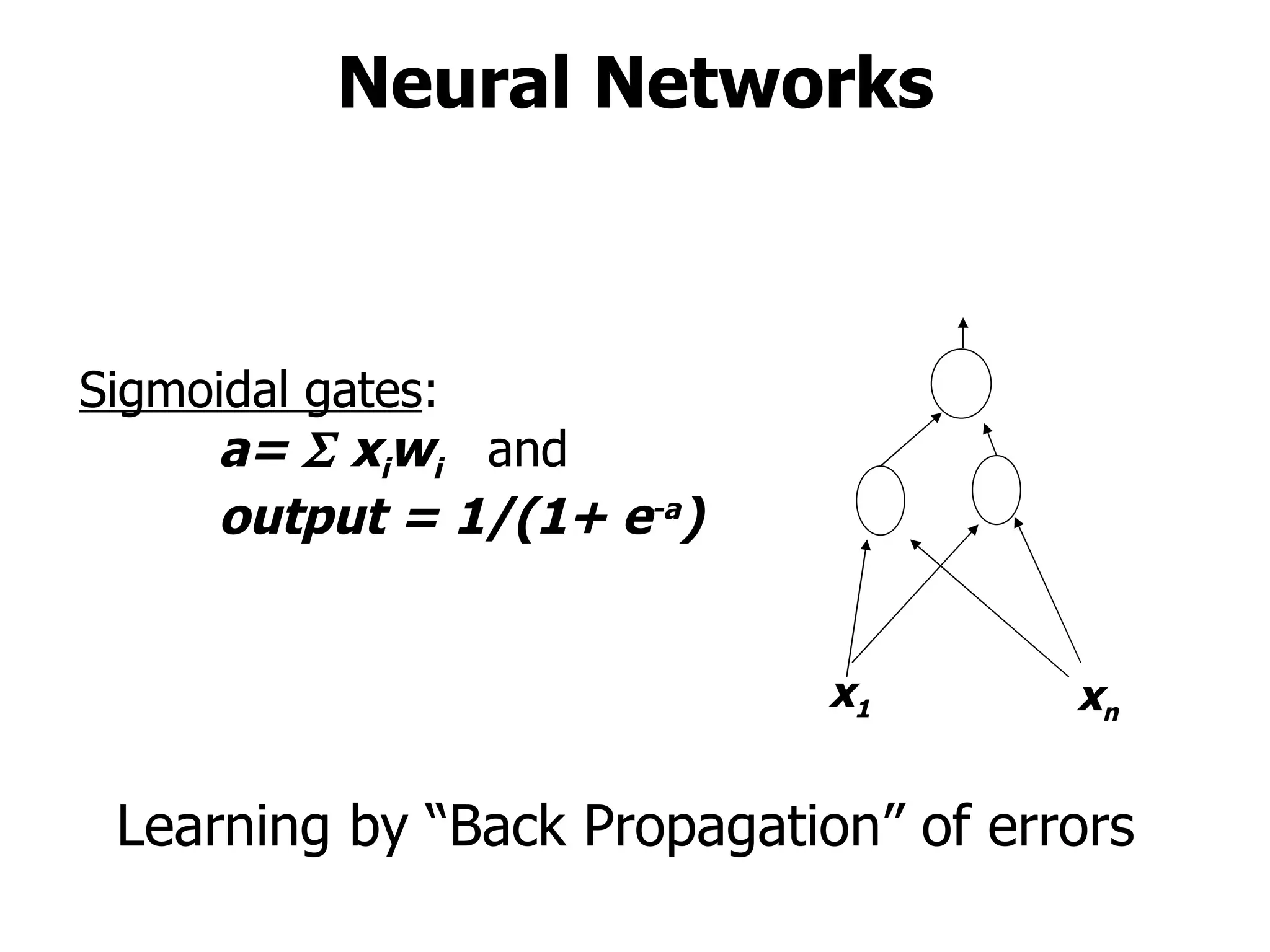
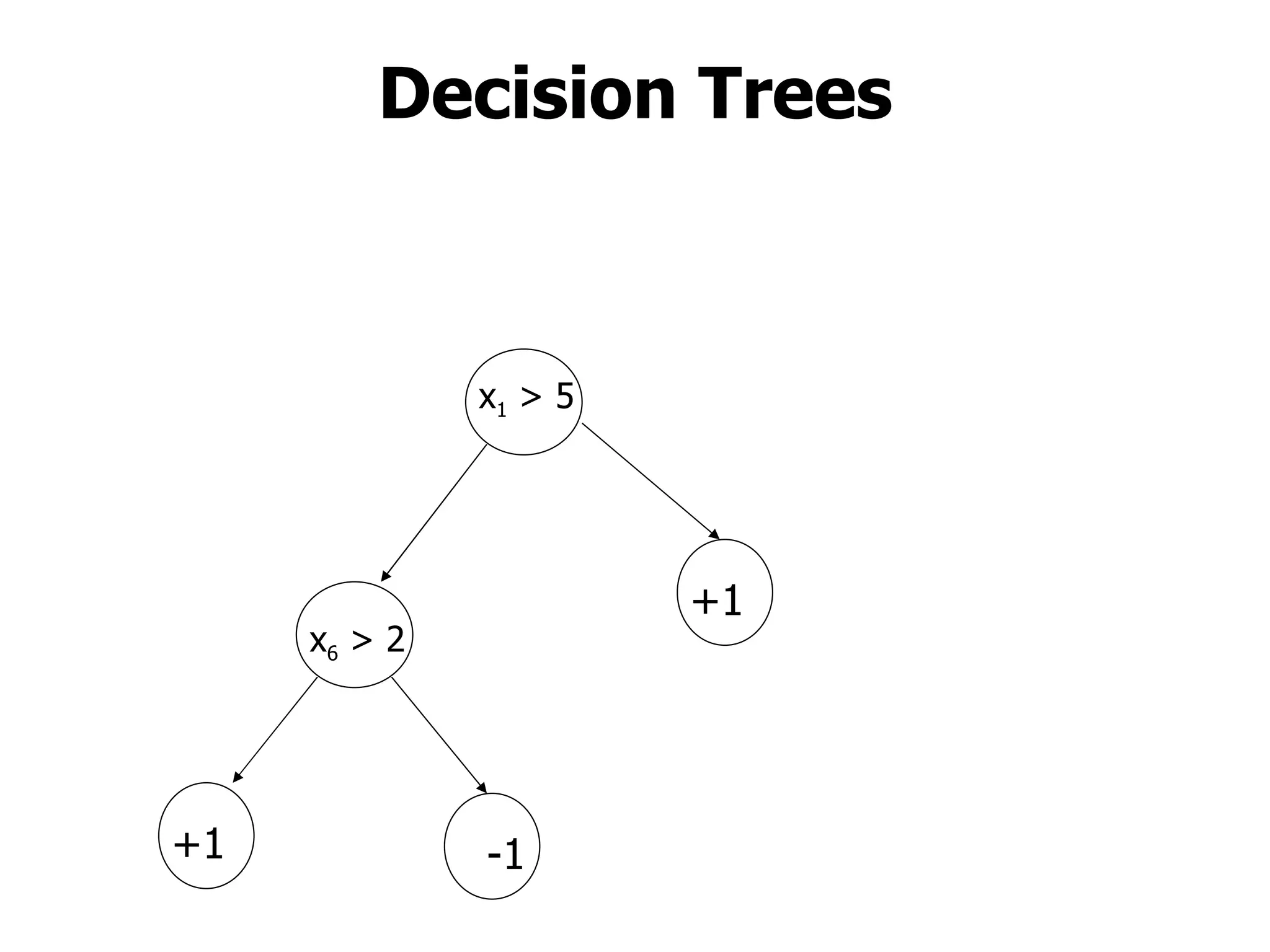
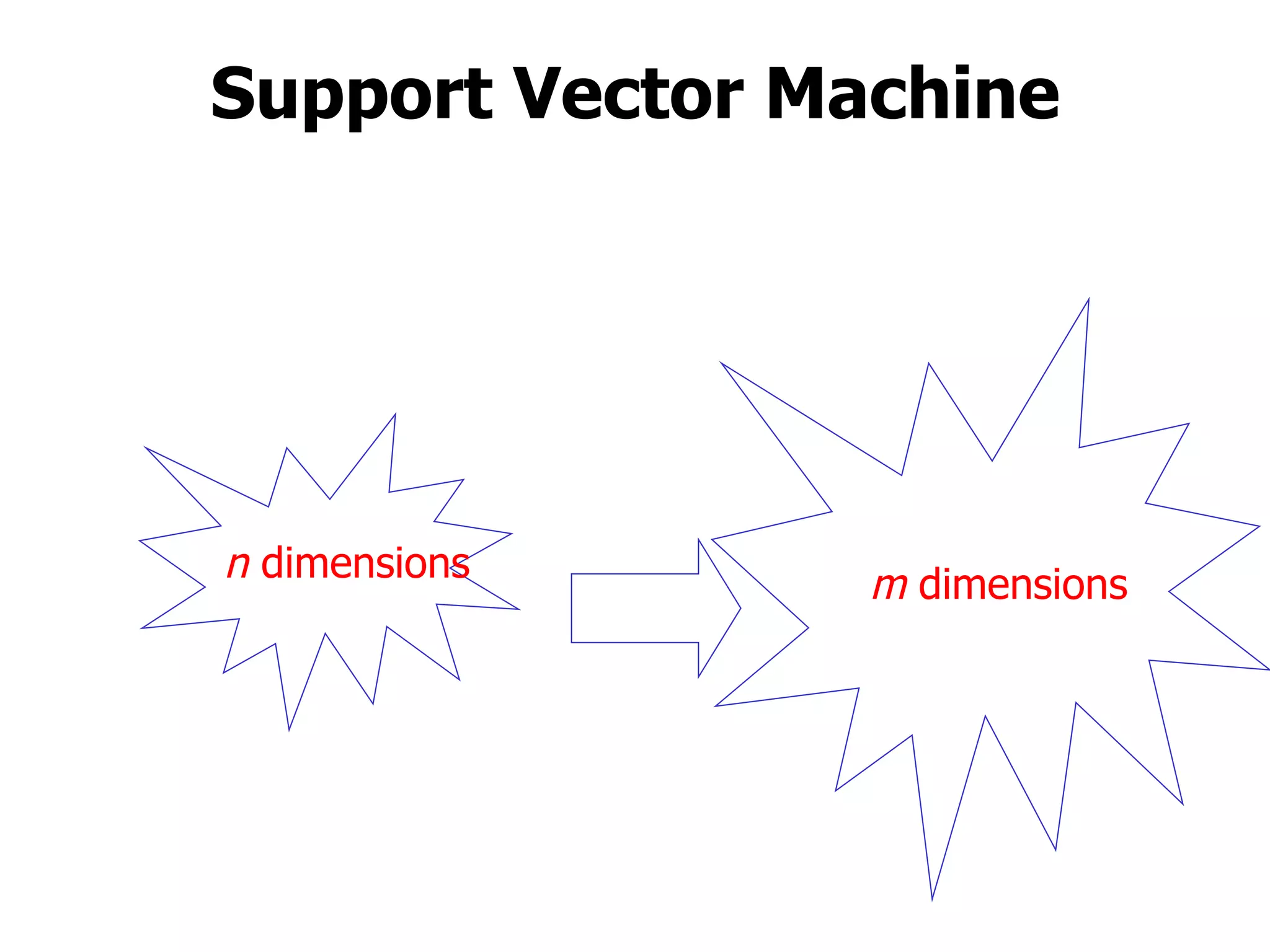
This machine learning course will cover theoretical and practical machine learning concepts. It will include 4 homework assignments and programming in Matlab. Lectures will be supplemented by student-submitted class notes in LaTeX. Topics will include learning approaches like storage and retrieval, rule learning, and flexible model estimation, as well as applications in areas like control, medical diagnosis, and web search. A final exam format has not been determined yet.
























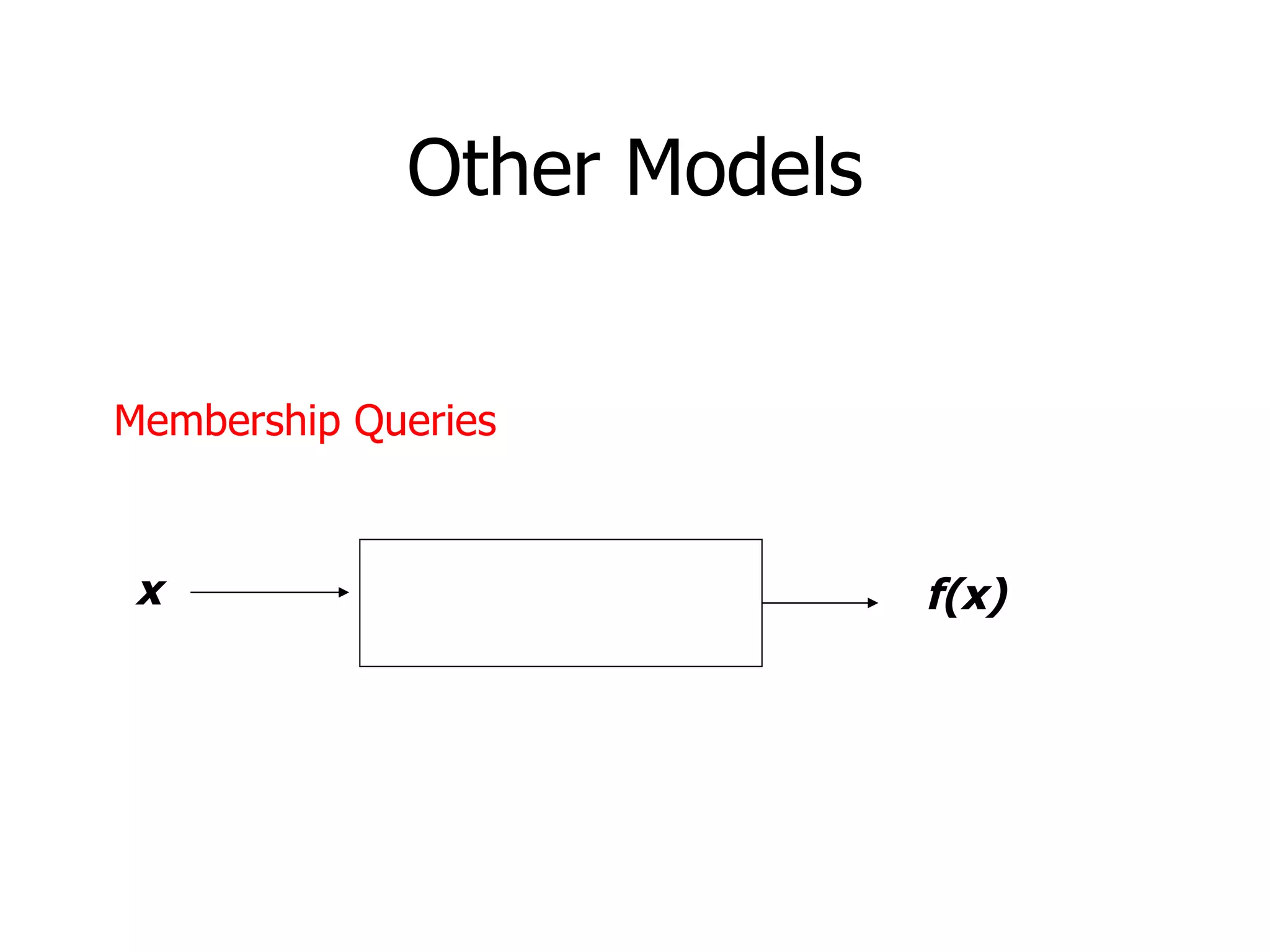
![Other Loss Models Quadratic loss Predict a “real number” q for outcome 1. Loss (q-p) 2 for outcome 1 Loss ([1-q]-[1-p]) 2 for outcome 0 Expected loss: (p-q) 2 Minimized for p=q (Optimal prediction) Recovers the probabilities Needs to know p to compute loss!](https://image.slidesharecdn.com/machine-learning-foundations-course-number-0368403401895/75/Machine-Learning-Foundations-Course-Number-0368403401-28-2048.jpg)
![The basic PAC Model A batch learning model, i.e., the algorithm is trained over some fixed data set Assumption: Fixed (Unknown distribution D of x in a domain X) The error of a hypothesis h w.r.t. a target concept f is e(h)= Pr D [h(x)≠f(x)] Goal: Given a collection of hypotheses H , find h in H that minimizes e(h).](https://image.slidesharecdn.com/machine-learning-foundations-course-number-0368403401895/75/Machine-Learning-Foundations-Course-Number-0368403401-29-2048.jpg)

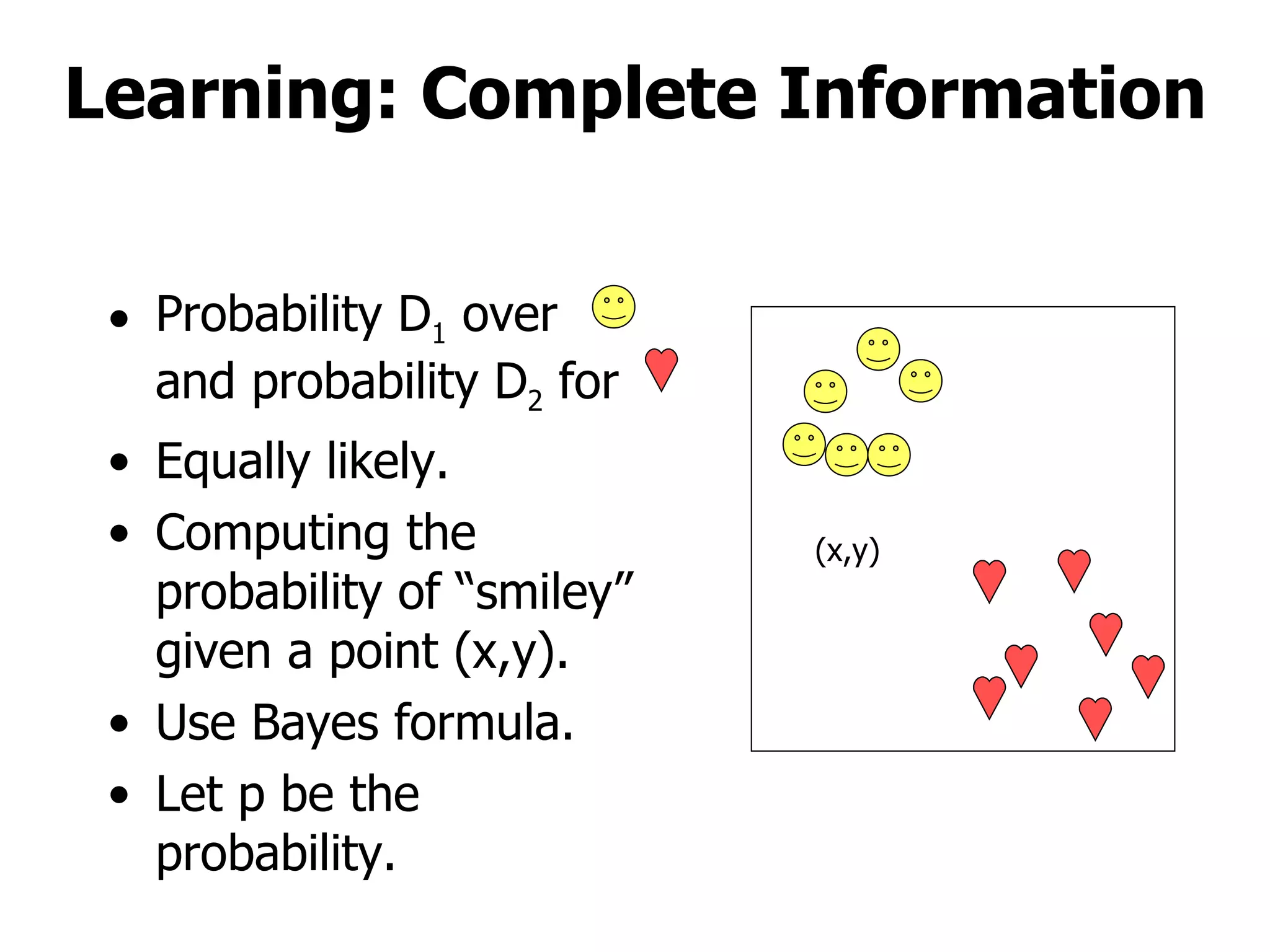
![Bayesian Theory Prior distribution over H Given a sample S compute a posterior distribution: Maximum Likelihood (ML) Pr[S|h] Maximum A Posteriori (MAP) Pr[h|S] Bayesian Predictor h(x) Pr[h|S].](https://image.slidesharecdn.com/machine-learning-foundations-course-number-0368403401895/75/Machine-Learning-Foundations-Course-Number-0368403401-31-2048.jpg)