Downloaded 13 times




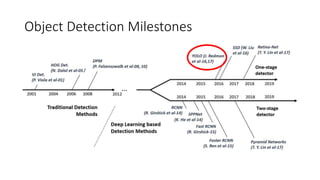

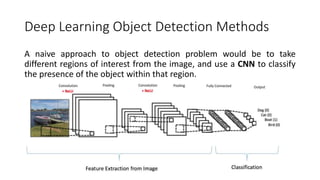

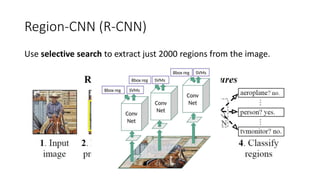
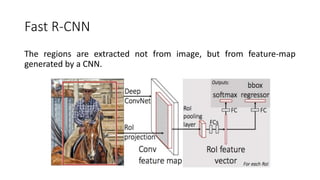



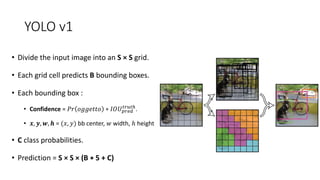
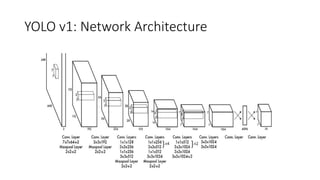




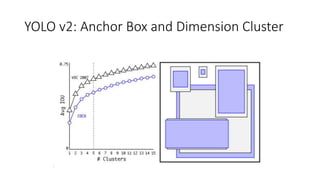

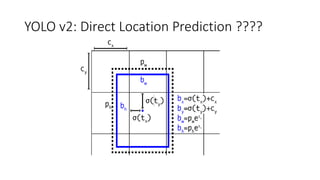


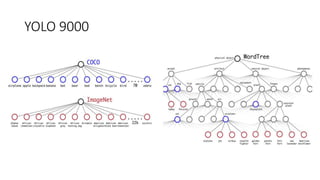
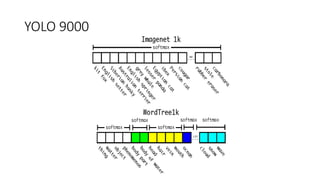


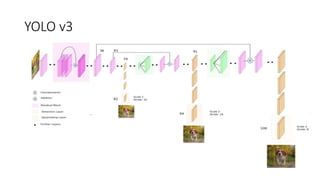

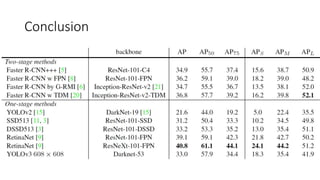


YOLO releases are one-stage object detection models that predict bounding boxes and class probabilities in an image using a single neural network. YOLO v1 divides the image into a grid and predicts bounding boxes and confidence scores for each grid cell. YOLO v2 improves on v1 with anchor boxes, batch normalization, and a Darknet-19 backbone network. YOLO v3 uses a Darknet-53 backbone, multi-scale feature maps, and a logistic classifier to achieve better accuracy. The YOLO models aim to perform real-time object detection with high accuracy while remaining fast and unified end-to-end models.

![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)





































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)













