







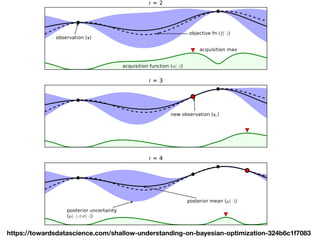
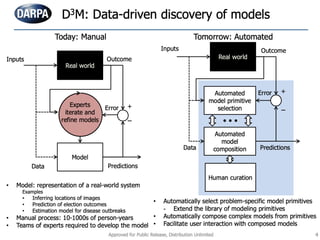

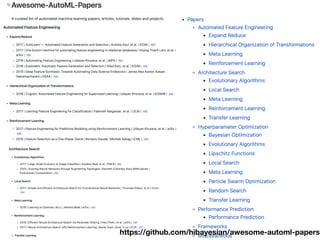








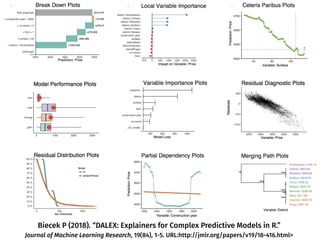
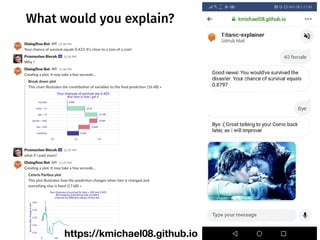
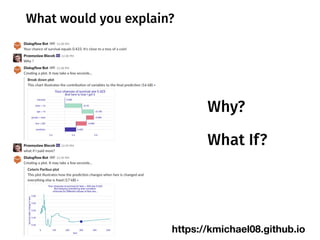



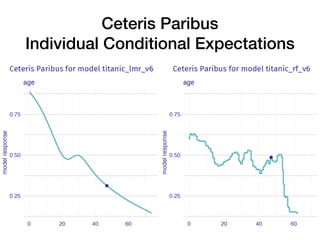
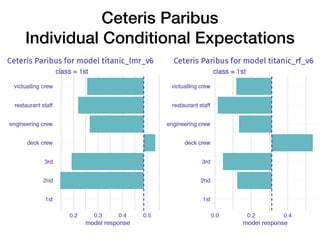
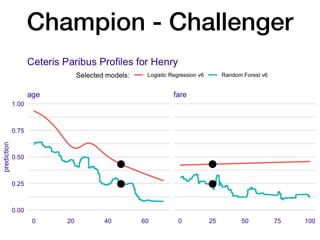
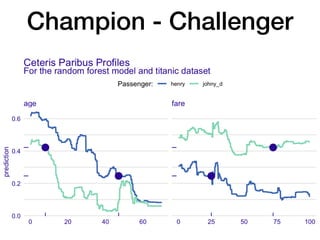
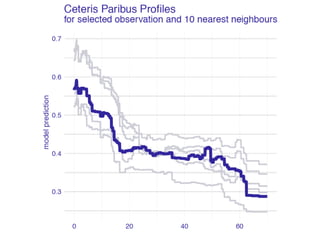
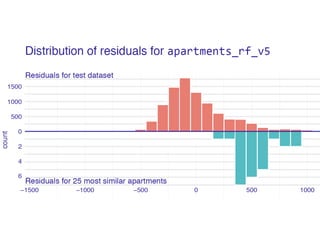

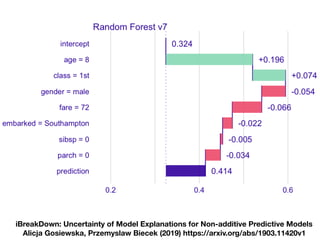
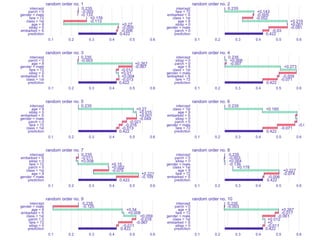
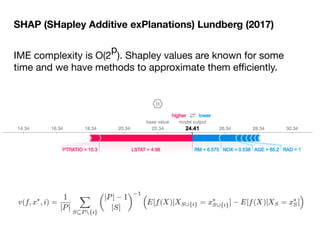
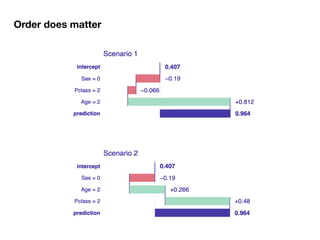
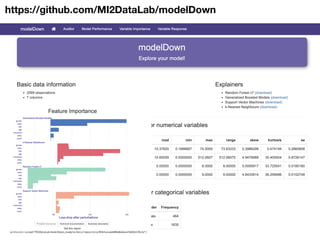
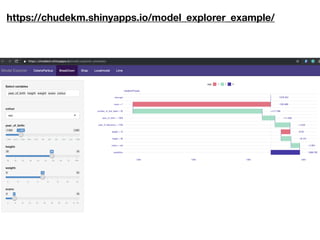
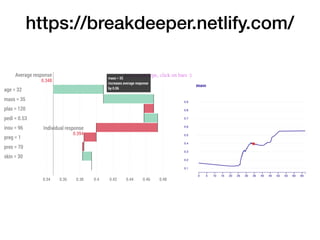
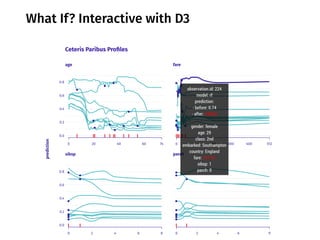
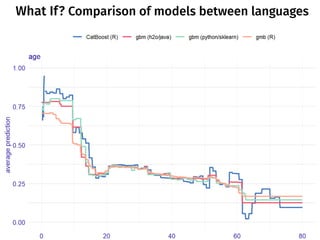


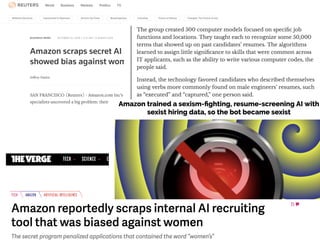

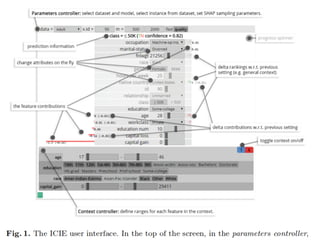
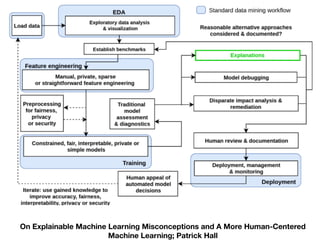
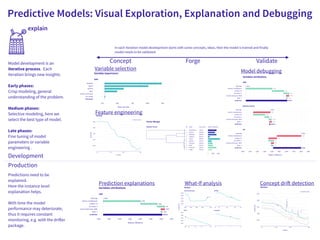

The document discusses a workshop focused on training machine learning models using automated machine learning (AutoML) techniques, specifically highlighting methodologies like sequential model-based optimization and ensemble learning. It emphasizes the importance of explainable AI, advocating for model transparency through approaches like local model approximations and Shapley value explanations. Additionally, it touches on the iterative nature of model development, including validation, interpretation of predictions, and the need to monitor model performance over time.



































































