Download as PDF, PPTX



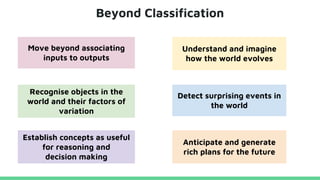
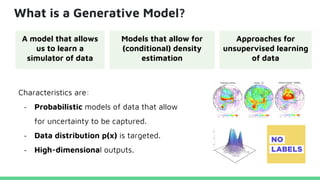

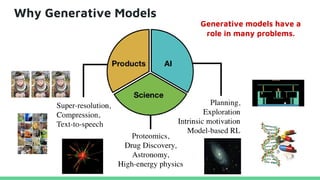



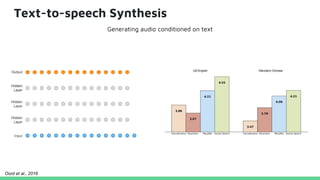



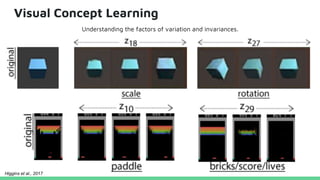

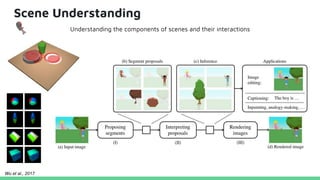

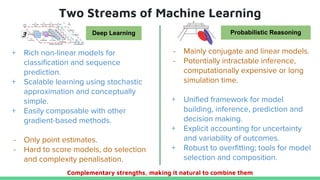

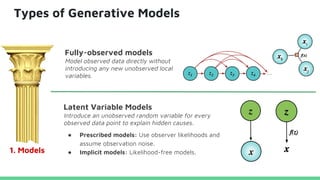
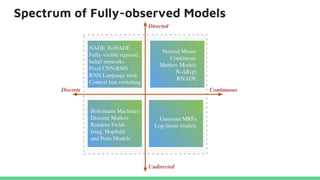
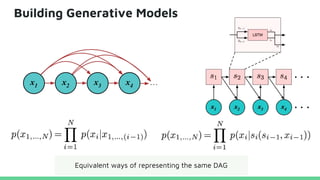
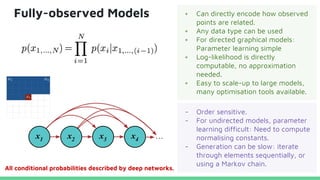
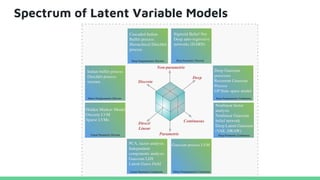




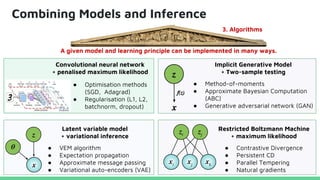




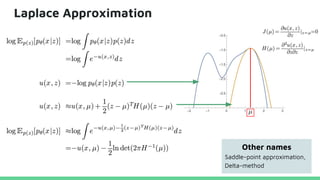

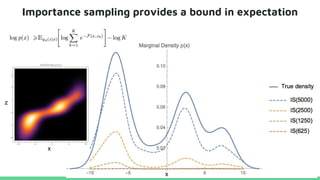



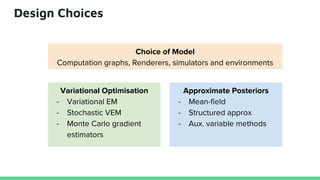
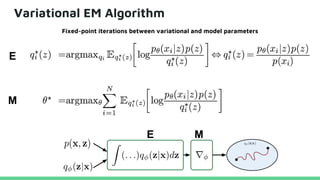

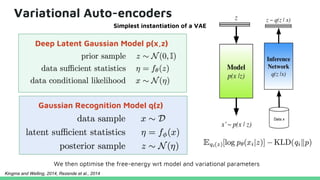
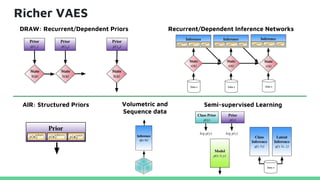
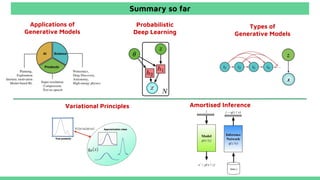


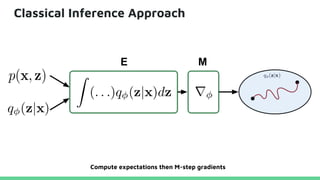
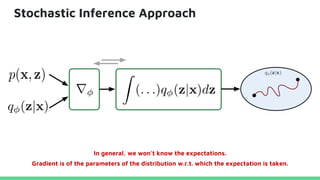
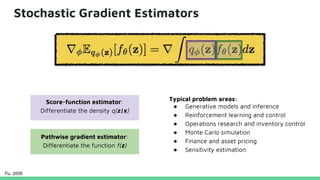





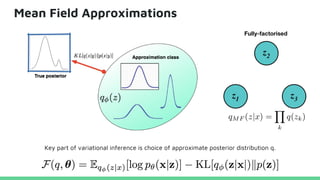
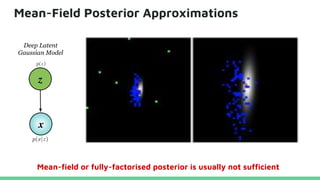

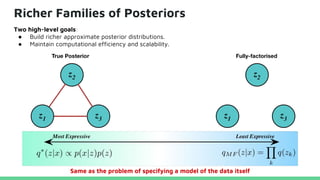
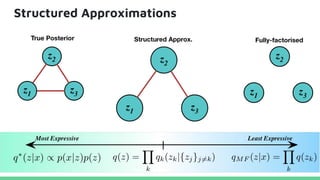
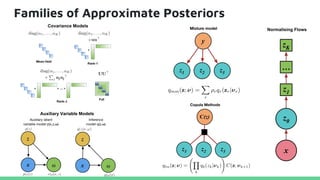
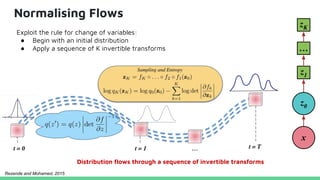
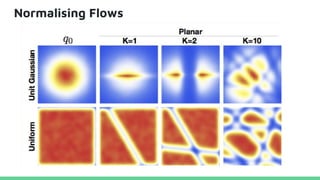
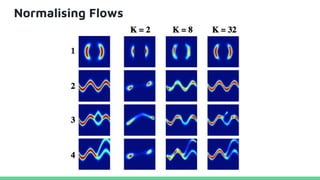
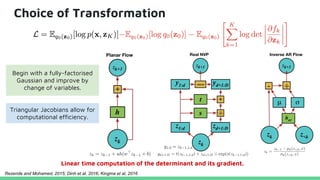
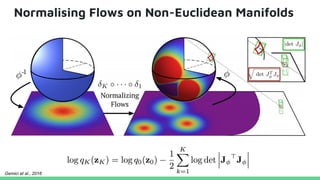

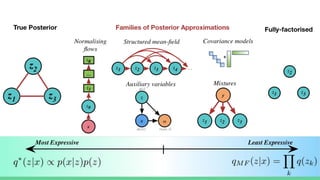

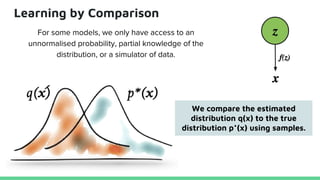
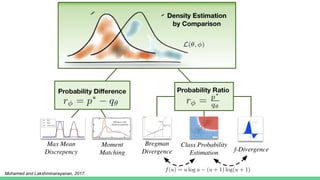
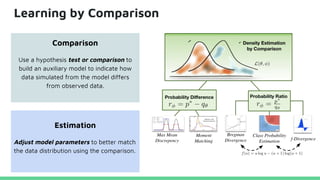
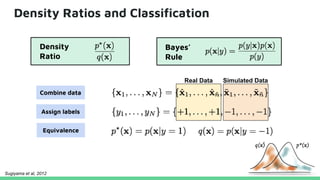



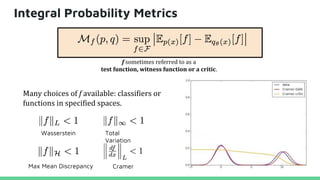



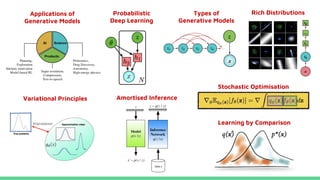
















This tutorial provides an overview of recent advances in deep generative models. It will cover three types of generative models: Markov models, latent variable models, and implicit models. The tutorial aims to give attendees a full understanding of the latest developments in generative modeling and how these models can be applied to high-dimensional data. Several challenges and open questions in the field will also be discussed. The tutorial is intended for the 2017 conference of the International Society for Bayesian Analysis.





























































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)














![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)

