Download as PDF, PPTX











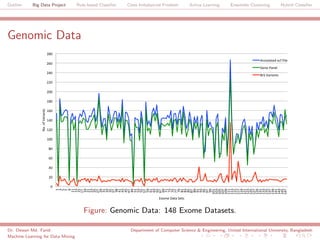



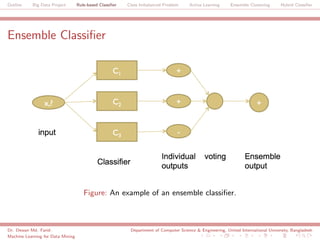









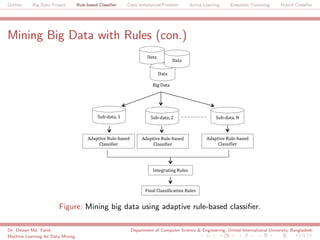




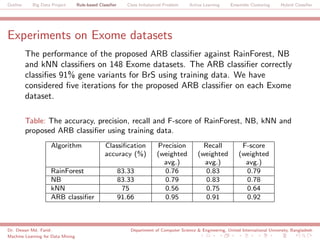
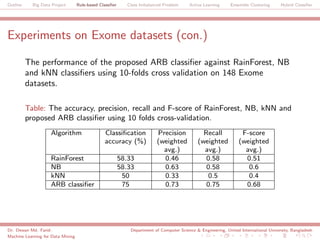
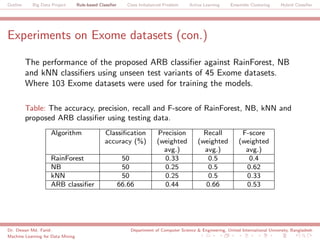
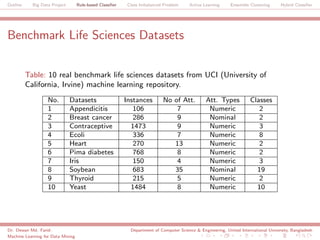
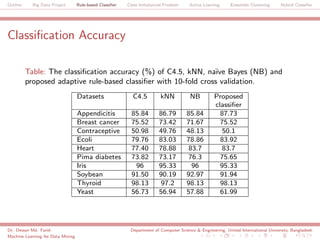
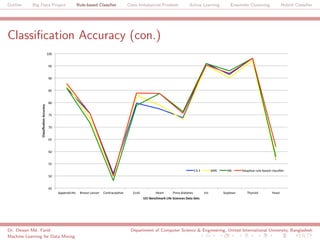
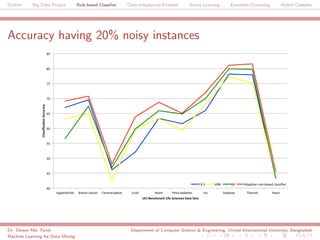



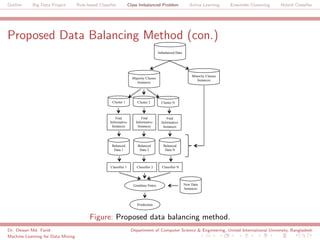
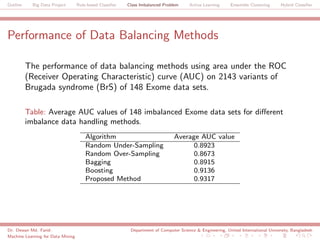

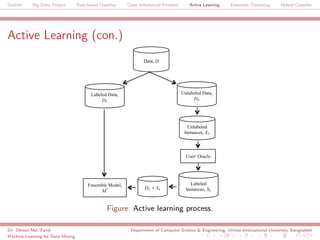











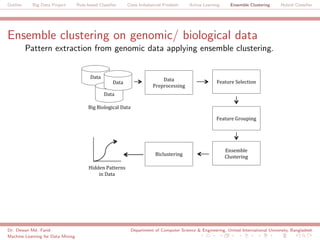




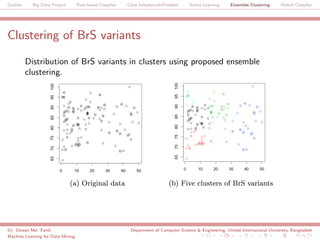





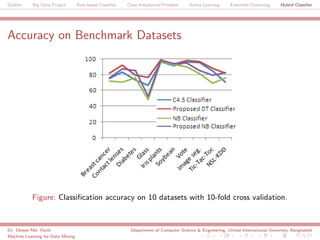

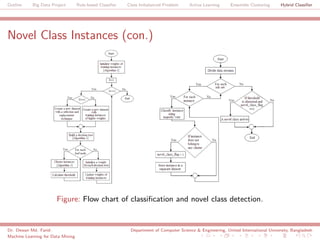



The document discusses a big data project focused on rule-based classifiers and their applications in addressing class imbalance problems, as well as techniques such as active learning and ensemble clustering in machine learning. It defines key concepts in data mining and machine learning, outlines research projects in the field, including the Bridgeiris project on clinical genomics, and details algorithms like decision trees and k-nearest neighbors. Additionally, it explores the classification of genetic data related to Brugada syndrome, highlighting the importance of effective knowledge extraction from large datasets.



























































![[IJET-V2I3P22] Authors: Harsha Pakhale,Deepak Kumar Xaxa](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i3p22-160711112719-thumbnail.jpg?width=640&height=640&fit=bounds)










































