


























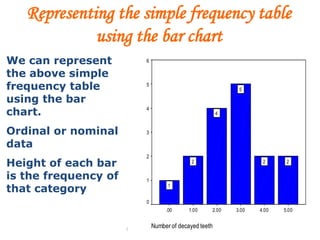
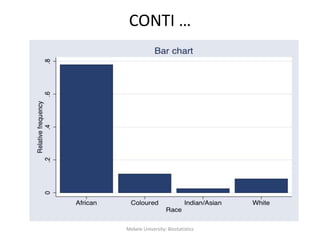
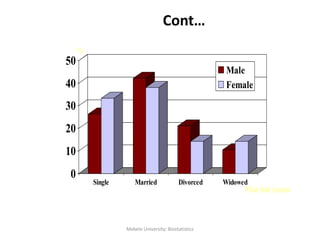

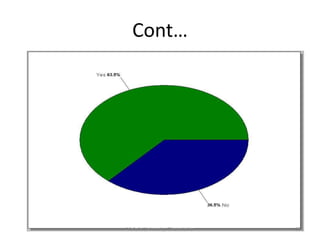



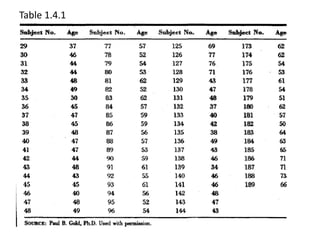


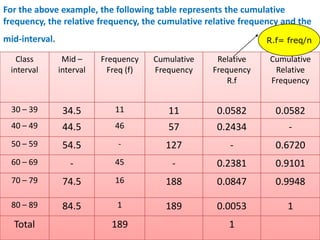

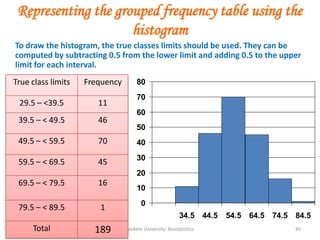
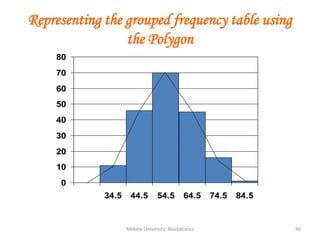

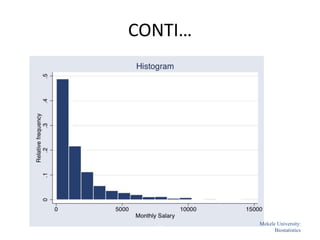

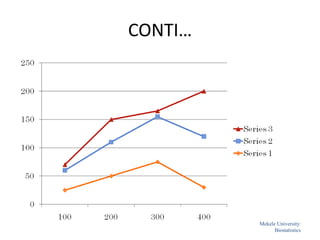

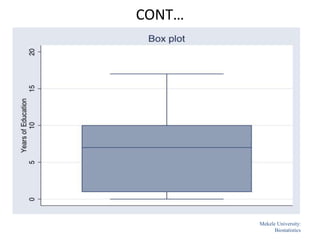








![Mekele University: Biostatistics 64
The Median:
When ordering the data, it is the observation that divide
the set of observations into two equal parts such that half
of the data are before it and the other are after it.
• If n is odd, the median will be the middle of observations.
It will be the (n+1)/2 th ordered observation.
When n = 11, then the median is the 6th observation.
• If n is even, there are two middle observations.
• The median will be the mean of these two middle
observations.
It will be the [(n/2)th+((n/2)+1)th]/2 ordered observation.
When n = 12, then the median is an observation halfway
between the 6th and 7th ordered observation.](https://image.slidesharecdn.com/biostat-130825010956-phpapp02/85/INTRODUCTION-TO-BIO-STATISTICS-64-320.jpg)









![Mekele University: Biostatistics 74
2.The Variance:
• It measure dispersion relative to the scatter of the values a
bout their mean.
a) Sample Variance ( ) :
• ,where is sample mean
• Find Sample Variance of ages , = 56
• Solution:
• S2= [(43-56) 2 +(66-56) 2+…..+(50-56) 2 ]/ 10
• = 900/10 = 90
x
2
S
1
)(
1
2
2
n
xx
S
n
i
i
x](https://image.slidesharecdn.com/biostat-130825010956-phpapp02/85/INTRODUCTION-TO-BIO-STATISTICS-74-320.jpg)



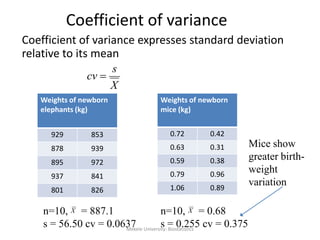











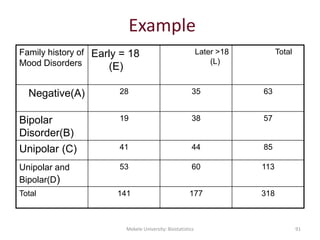












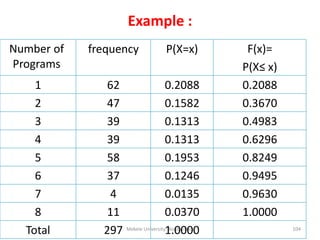










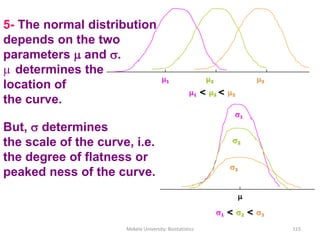




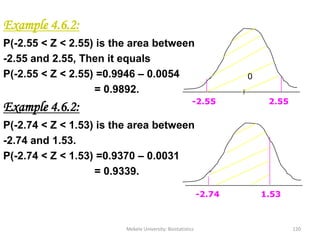

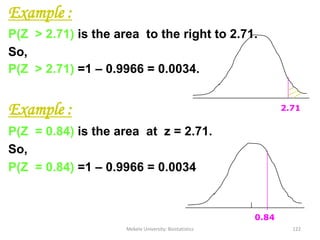











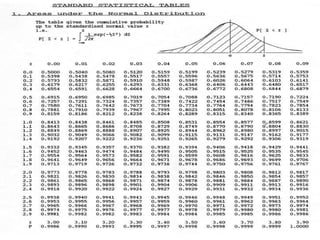
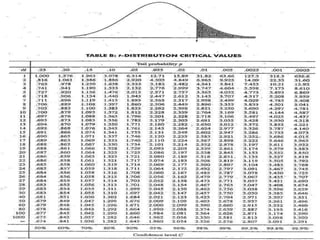





































































![Mekele University: Biostatistics 206
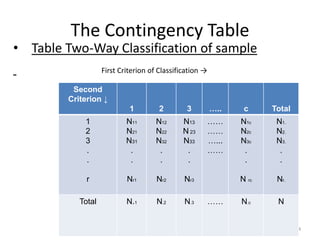
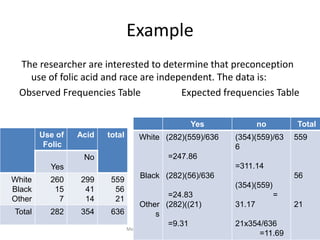
Chi-square Test
• After the calculations of expected frequency,
Prepare a table for expected frequencies and use Chi-square
Where summation is for all values of r xc = k cells.
• D.F.: the degrees of freedom for using the table are (r-1)(c-1)
for α level of significance
• Note that the test is always one-sided.
k
i
e
eo
i
ii
1
2
]
)(
[
2
](https://image.slidesharecdn.com/biostat-130825010956-phpapp02/85/INTRODUCTION-TO-BIO-STATISTICS-206-320.jpg)



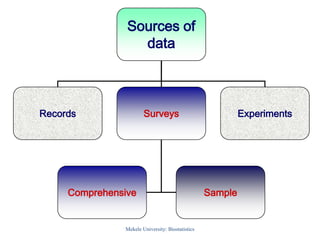
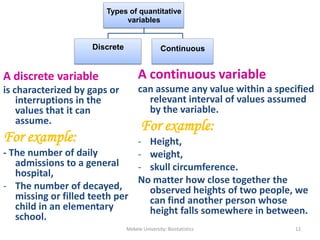
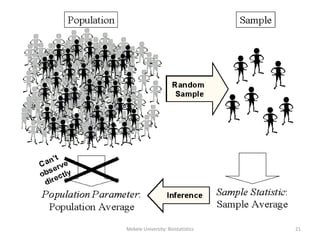
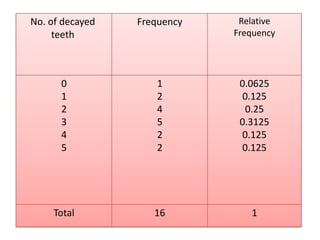
This document provides an introduction to biostatistics. It defines key concepts such as statistics, data, variables, populations, and samples. It discusses different types of variables including quantitative and qualitative variables. It also describes different measurement scales including nominal, ordinal, interval and ratio scales. Sources of data and descriptive statistics are introduced. Descriptive statistics help summarize and organize data using tables, graphs, and numerical measures.










































































































