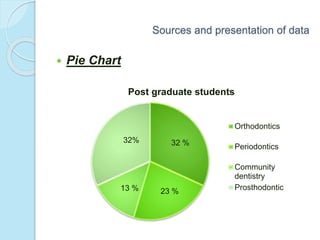
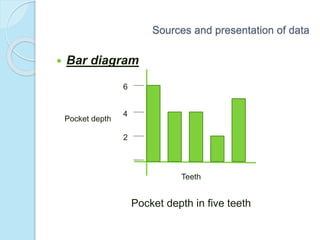
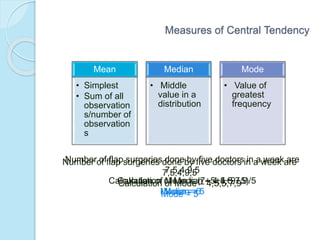
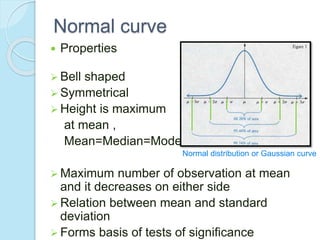
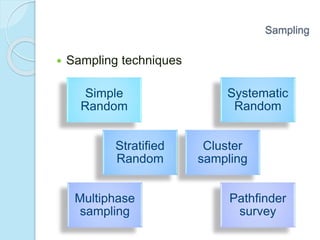
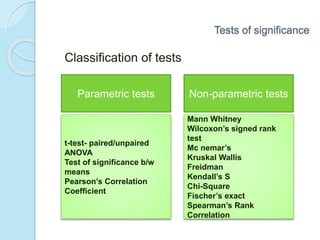
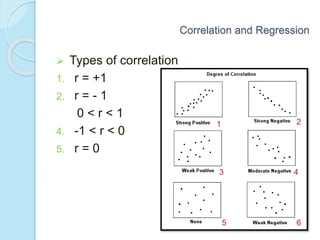
This document provides an overview of key concepts in biostatistics. It begins with introductions to terminology, sources and presentation of data, and measures of central tendency and dispersion. It then discusses the normal curve, sampling techniques, and types of tests of significance including t-tests, ANOVA, and non-parametric tests. The document provides examples and explanations of commonly used statistical analyses for comparing means and assessing relationships in data.