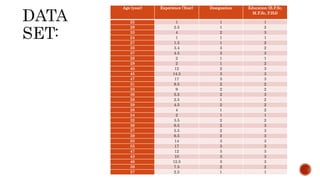
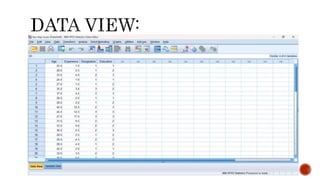
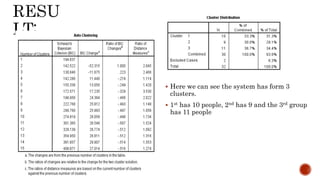
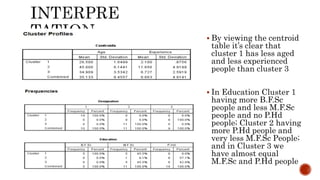
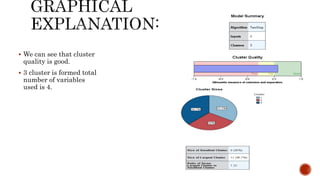
This document discusses two-step cluster analysis. It explains that two-step cluster analysis is a hybrid approach that first separates groups using a distance measure, and then chooses the optimal subgroup model using a probabilistic approach. It can handle both categorical and continuous variables by assuming variable independence within clusters. The algorithm can also automatically select the optimal number of clusters and is scalable to large datasets. The document provides an example of two-step cluster analysis using designation and education as categorical variables, and age and experience as continuous variables to cluster 30 individuals into three groups based on these characteristics.











































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











