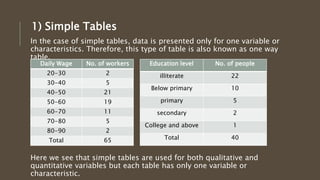
The document explains the processing of data in research, which involves several key steps: editing, coding, classification, and tabulation. It details each step, emphasizing the importance of accurately editing data, coding qualitative data into quantitative formats, classifying the data for meaningful analysis, and presenting the data through tables for statistical examination. The document also outlines various types of classification and tabulation methods, and highlights the benefits of each stage in the data processing workflow.











































![Review of literature [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/reviewofliteratureautosaved-230315053854-fbe61789-thumbnail.jpg?width=640&height=640&fit=bounds)




















































