Downloaded 15 times








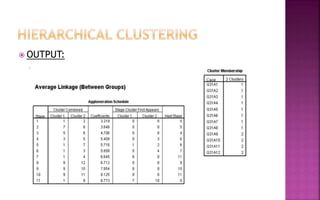




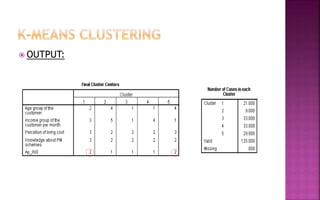





The document discusses various clustering techniques used for grouping customers and faculty based on their characteristics through cluster analysis, including hierarchical and k-means clustering methods. It describes how these techniques identify group membership and categorize data, with practical examples related to faculty's technology adaptation and banking customers' demographics. The analysis results in distinct clusters that allow for targeted marketing and interventions based on the findings.






































![Market Research_Grp 3_27-05-2024[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/marketresearchgrp327-05-20241-250406071106-a43d19be-thumbnail.jpg?width=640&height=640&fit=bounds)
















































