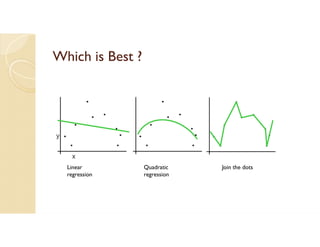
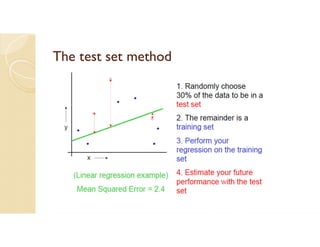
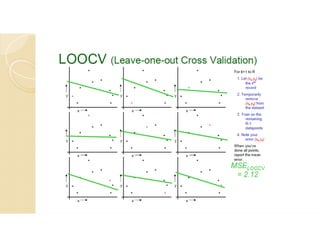
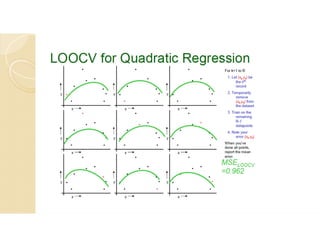
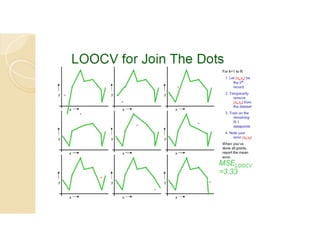
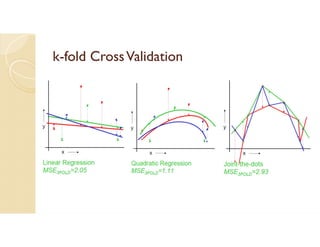
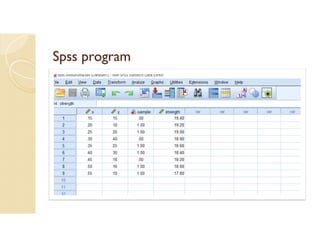
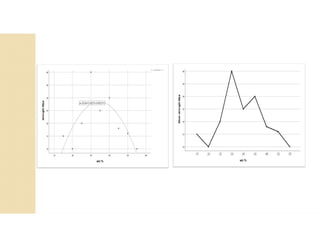
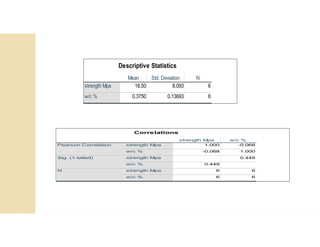
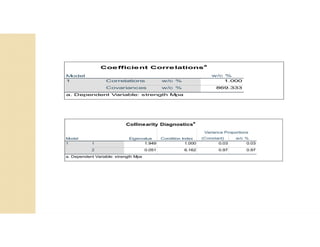
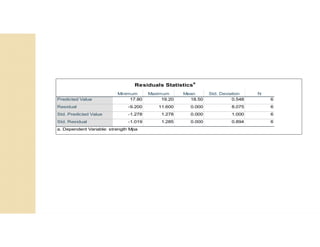
Cross-validation is a technique used to evaluate machine learning models by reserving a portion of a dataset to test the model trained on the remaining data. There are several common cross-validation methods, including the test set method (reserving 30% of data for testing), leave-one-out cross-validation (training on all data points except one, then testing on the left out point), and k-fold cross-validation (randomly splitting data into k groups, with k-1 used for training and the remaining group for testing). The document provides an example comparing linear regression, quadratic regression, and point-to-point connection on a concrete strength dataset using k-fold cross-validation. SPSS output for the