Download as PDF, PPTX







![Introduction to Magellan
Shapefiles
*.shp
*.dbf
sqlContext.read.format(“magellan”)
.load(${neighborhoods.path})
GeoJSON
*.json
sqlContext.read.format(“magellan”)
.option(“type”, “geojson”)
.load(${neighborhoods.path})
polygon metadata
([0], [(-122.4413024, 7.8066277),
…])
neighborhood -> Marina
([0], [(-122.4111659, 37.8003388),
…])
neighborhood -> North Beach](https://image.slidesharecdn.com/4gbramsriharsha-160224014538/85/Magellan-Spark-as-a-Geospatial-Analytics-Engine-by-Ram-Sriharsha-7-320.jpg)
![Introduction to Magellan
polygon metadata
([0], [(-
122.4413024,
7.8066277), …])
neighborhood ->
Marina
([0], [(-
122.4111659,
37.8003388), …])
neighborhood ->
North Beach
neighborhoods.filter(
point(-122.4111659, 37.8003388)
within
‘polygon
).show()
polygon metadata
([0], [(-
122.4111659,
37.8003388), …])
neighborhood ->
North Beach
Shape literal
Boolean Expression](https://image.slidesharecdn.com/4gbramsriharsha-160224014538/85/Magellan-Spark-as-a-Geospatial-Analytics-Engine-by-Ram-Sriharsha-8-320.jpg)
![Introduction to Magellan
polygon metadata
([0], [(-122.4111659,
37.8003388),…])
neighborhood->
North Beach
([0], [(-122.4413024,
7.8066277),…])
neighborhood->
Marina
point
(-122.4111659,
37.8003388)
(-122.4343576,
37.8068007)
points.join(neighborhoods).
where(‘point within ‘polygon).
show()
point polygon metadata
(-122.4343576,
37.8068007)
([0], [(-
122.4111659,
37.8003388),
…])
neighborhood-
> North Beach](https://image.slidesharecdn.com/4gbramsriharsha-160224014538/85/Magellan-Spark-as-a-Geospatial-Analytics-Engine-by-Ram-Sriharsha-9-320.jpg)
![Introduction to Magellan
polygon metadata
([0], [(-122.4111659,
37.8003388),…])
neighborhood->
North Beach
([0], [(-122.4413024,
7.8066277),…])
neighborhood->
Marina
neighborhoods.filter(
point(-122.4111659, 37.8003388).buffer(0.1)
intersects
‘polygon
).show()
point polygon metadata
(-122.4343576,
37.8068007)
([0], [(-
122.4111659,
37.8003388),
…])
neighborhood-
> North Beach](https://image.slidesharecdn.com/4gbramsriharsha-160224014538/85/Magellan-Spark-as-a-Geospatial-Analytics-Engine-by-Ram-Sriharsha-10-320.jpg)
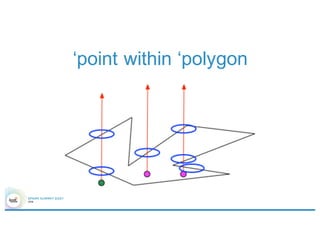








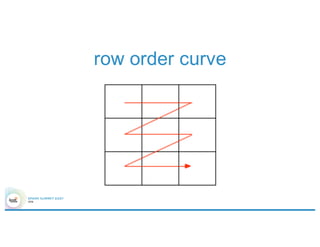
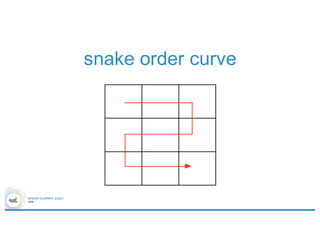
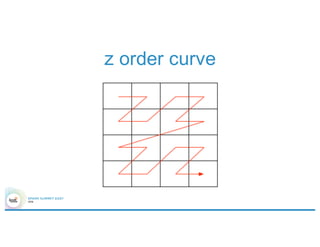









![Overall architecture
Elastic search
Shard Server
Spark Cluster
nbd.filter(
point(…)
within
‘polygon
)
curl –XGET ‘http://…’ –d ‘{
“query” : {
“filtered” : {
“filter” : {
“geohash” : [“dr5rgb”]
}
}
}
}’](https://image.slidesharecdn.com/4gbramsriharsha-160224014538/85/Magellan-Spark-as-a-Geospatial-Analytics-Engine-by-Ram-Sriharsha-34-320.jpg)



This document discusses geospatial analytics using Apache Spark and introduces Magellan, a library for performing geospatial queries and analysis on Spark. It provides an overview of geospatial analytics tasks, challenges with existing approaches, and how Magellan addresses these challenges by leveraging Spark SQL and Catalyst. Magellan allows querying geospatial data in formats like Shapefiles and GeoJSON, performs operations like spatial joins and filters, and supports optimizations like geohashing to improve query performance at scale. The document outlines the current status and features of Magellan and describes plans for further improvements in future versions.


































































































