Download to read offline



























![(U1 ,Madrid, Point(x1, y1))
(U2 ,Logroño, Point(x2, y2))
(U1 ,Cadiz, Point(x3, y3))
(U3 ,Logroño, Point(x4, y4))
Geomesa
(U1 ,Ávila, Point(x5, y5))
(U2 ,Huelva, Point(x6, y6))
(U3 ,Huelva, Point(x7, y7))
(U2 ,Logroño, Point(x8, y8))
HBase
Master
Spark Executor-1
Spark Executor-2
Point(x1, y1), [U1 ,Madrid]
Point(x5, y5), [U1 ,Ávila]
Point(x2, y2), [U21 ,Logroño]
Point(x4, y4), [U31 ,Logroño]
Point(x6, y6), [U1 ,Huelva]
Point(x7, y7), [U3 ,Huelva]
Point(x3, y3), [U1 ,Cadiz]
Point(x8, y8), [U21 ,Logroño]
Region Server-1
Region Server-2
Region Server-3](https://image.slidesharecdn.com/commitconf2018-181127111446/85/Geoposicionamiento-Big-Data-o-It-s-bigger-on-the-inside-Commit-conf-2018-36-320.jpg)
![ECLQuery.toCQL(“people
between 1000, 200”)
Geomesa
HBase
Master
Client.java
Region Server-1
Region Server-2
Region Server-3
Point(x1, y1), [U1 ,Madrid]
Point(x5, y5), [U1 ,Ávila]
Point(x2, y2), [U21 ,Logroño]
Point(x4, y4), [U31 ,Logroño]
Point(x6, y6), [U1 ,Huelva]
Point(x7, y7), [U3 ,Huelva]
Point(x3, y3), [U1 ,Cadiz]
Point(x8, y8), [U21 ,Logroño]](https://image.slidesharecdn.com/commitconf2018-181127111446/85/Geoposicionamiento-Big-Data-o-It-s-bigger-on-the-inside-Commit-conf-2018-37-320.jpg)
![Geomesa
HBase
Master
val dataFrame =
sparkSession.read
.format("geomesa")
.options(dsParams)
.option("geomesa.feat
ure", "spain")
.load()
Spark Driver
Region Server-1
Region Server-2
Region Server-3
Point(x1, y1), [U1 ,Madrid]
Point(x5, y5), [U1 ,Ávila]
Point(x2, y2), [U21 ,Logroño]
Point(x4, y4), [U31 ,Logroño]
Point(x6, y6), [U1 ,Huelva]
Point(x7, y7), [U3 ,Huelva]
Point(x3, y3), [U1 ,Cadiz]
Point(x8, y8), [U21 ,Logroño]](https://image.slidesharecdn.com/commitconf2018-181127111446/85/Geoposicionamiento-Big-Data-o-It-s-bigger-on-the-inside-Commit-conf-2018-38-320.jpg)






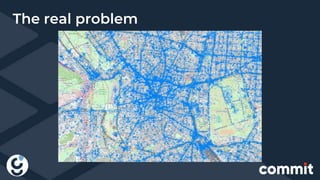
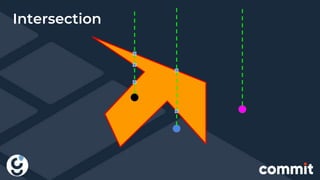
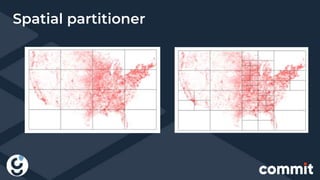
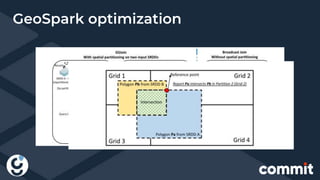
The document discusses the integration of big data and geopositioning analytics, emphasizing the importance of choosing proper keys for data processing and storage. It highlights how using advanced analytics and artificial intelligence can transform data into actionable insights for strategic decision-making. The document also presents challenges and solutions related to geospatial data handling within big data frameworks, specifically addressing the computational costs associated with geospatial operations.

























































