Download as PDF, PPTX





![MongoDB - GeoJSON
● Supports GeoJSON and legacy coordinate pairs [<lon>,<lat>]
● Point
● LineString
● Polygon
● MultiPoint
● MultiLineString
● MultiPolygon
● GeometryCollection](https://image.slidesharecdn.com/geospatialimplementation-210512205522/85/Comparing-Geospatial-Implementation-in-MongoDB-Postgres-and-Elastic-5-320.jpg)






















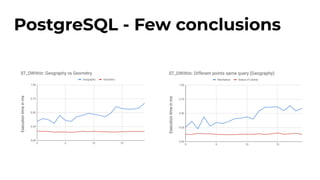













The document discusses the geospatial capabilities of MongoDB, PostgreSQL/PostGIS, and Elasticsearch, highlighting their differences in features like proximity searches, indexing, and best practices for implementation. MongoDB supports GeoJSON and has specific query functionalities, while PostgreSQL offers advanced spatial types and functions through PostGIS, and Elasticsearch utilizes geo field types and efficient query processes with caching. The closing remarks suggest that for heavy geospatial workloads, PostgreSQL and Elasticsearch may be more suitable than MongoDB, with PostgreSQL having the richest command set.














































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)















