Downloaded 49 times









![Spark
[MZ12] Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael
J. Franklin, Scott Shenker, and Ion Stoica. 2012. Resilient distributed datasets: a fault-tolerant abstraction for in-
memory cluster computing. In Proceedings of the 9th USENIX conference on Networked Systems Design and
Implementation (NSDI'12). USENIX Association, Berkeley, CA, USA, 2-2.
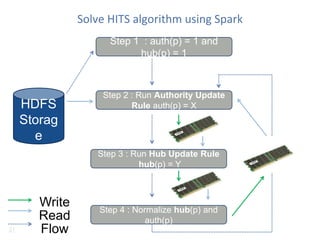
Transformations/Actions Description
Map(function f1) Pass each element of the RDD through f1 in parallel and return the resulting RDD.
Filter(function f2) Select elements of RDD that return true when passed through f2.
flatMap(function f3) Similar to Map, but f3 returns a sequence to facilitate mapping single input to multiple
outputs.
Union(RDD r1) Returns result of union of the RDD r1 with the self.
Sample(flag, p, seed) Returns a randomly sampled (with seed) p percentage of the RDD.
groupByKey(noTasks) Can only be invoked on key-value paired data – returns data grouped by value. No. of
parallel tasks is given as an argument (default is 8).
reduceByKey(function f4,
noTasks)
Aggregates result of applying f4 on elements with same key. No. of parallel tasks is the
second argument.
Join(RDD r2, noTasks) Joins RDD r2 with self – computes all possible pairs for given key.
groupWith(RDD r3,
noTasks)
Joins RDD r3 with self and groups by key.
sortByKey(flag) Sorts the self RDD in ascending or descending based on flag.
Reduce(function f5) Aggregates result of applying function f5 on all elements of self RDD
Collect() Return all elements of the RDD as an array.
Count() Count no. of elements in RDD
take(n) Get first n elements of RDD.
First() Equivalent to take(1)
saveAsTextFile(path) Persists RDD in a file in HDFS or other Hadoop supported file system at given path.
saveAsSequenceFile(path
)
Persist RDD as a Hadoop sequence file. Can be invoked only on key-value paired RDDs
that implement Hadoop writable interface or equivalent.
foreach(function f6) Run f6 in parallel on elements of self RDD.](https://image.slidesharecdn.com/sparkmeetup23jan2015ver0-150126200138-conversion-gate02/85/Distributed-Deep-Learning-others-for-Spark-Meetup-22-320.jpg)
![25
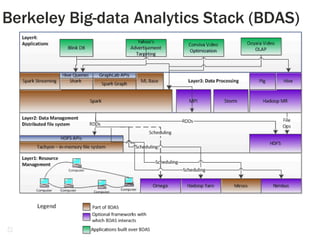
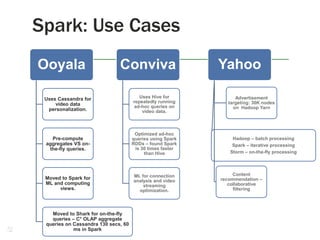
Spark Use Cases: Spark is good for linear algebra, optimization and
N-body problems.Computations/Operations
Giant 1 (simple stats) is perfect
for Hadoop 1.0.
Giants 2 (linear algebra), 3 (N-
body), 4 (optimization) Spark
from UC Berkeley is efficient.
Logistic regression, kernel SVMs,
conjugate gradient descent,
collaborative filtering, Gibbs
sampling, alternating least squares.
Example is social group-first
approach for consumer churn
analysis [2]
Interactive/On-the-fly data
processing – Storm.
OLAP – data cube operations.
Dremel/Drill
Data sets – not embarrassingly
parallel?
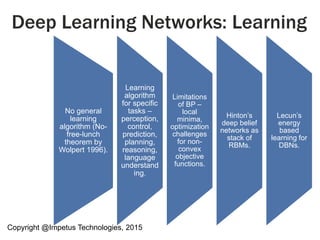
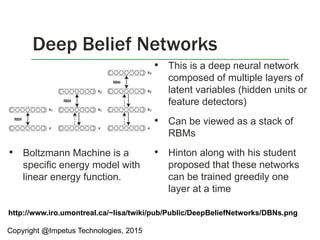
Deep Learning
Artificial Neural Networks/Deep
Belief Networks
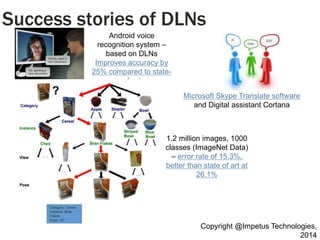
Machine vision from Google [3]
Speech analysis from Microsoft
Giant 5 – Graph processing –
GraphLab, Pregel, Giraph
[1] National Research Council. Frontiers in Massive Data Analysis . Washington, DC: The National Academies Press, 2013.
[2] Richter, Yossi ; Yom-Tov, Elad ; Slonim, Noam: Predicting Customer Churn in Mobile Networks through Analysis of Social
Groups. In: Proceedings of SIAM International Conference on Data Mining, 2010, S. 732-741
[3] Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao, Marc'Aurelio
Ranzato, Andrew W. Senior, Paul A. Tucker, Ke Yang, Andrew Y. Ng: Large Scale Distributed Deep Networks. NIPS 2012:](https://image.slidesharecdn.com/sparkmeetup23jan2015ver0-150126200138-conversion-gate02/85/Distributed-Deep-Learning-others-for-Spark-Meetup-25-320.jpg)




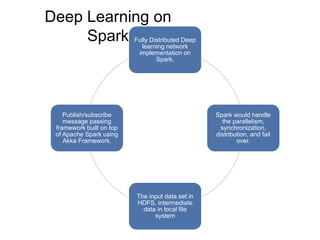
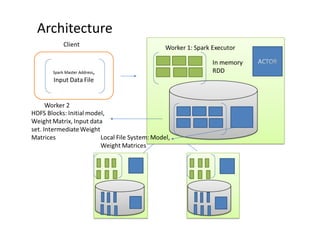



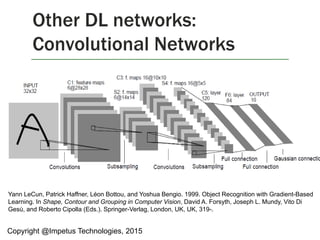




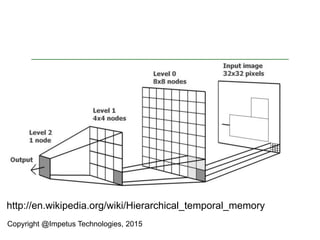

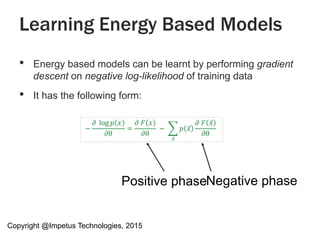


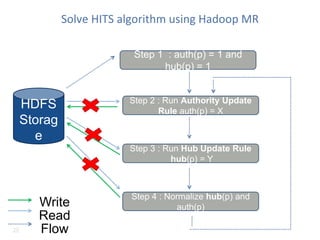
The document discusses a Spark meet-up held on January 23, 2015, in Bangalore, featuring presentations on distributed deep learning, outlier detection algorithms, and autoscaling in Spark, among other topics. It highlights various deep learning networks and their applications, such as speech recognition and video sequencing, while addressing the challenges of deep learning and the advantages of using Spark for data processing. Additionally, it provides examples and coding snippets related to Spark's capabilities, such as logistic regression and the HITS algorithm.



































































