Downloaded 388 times
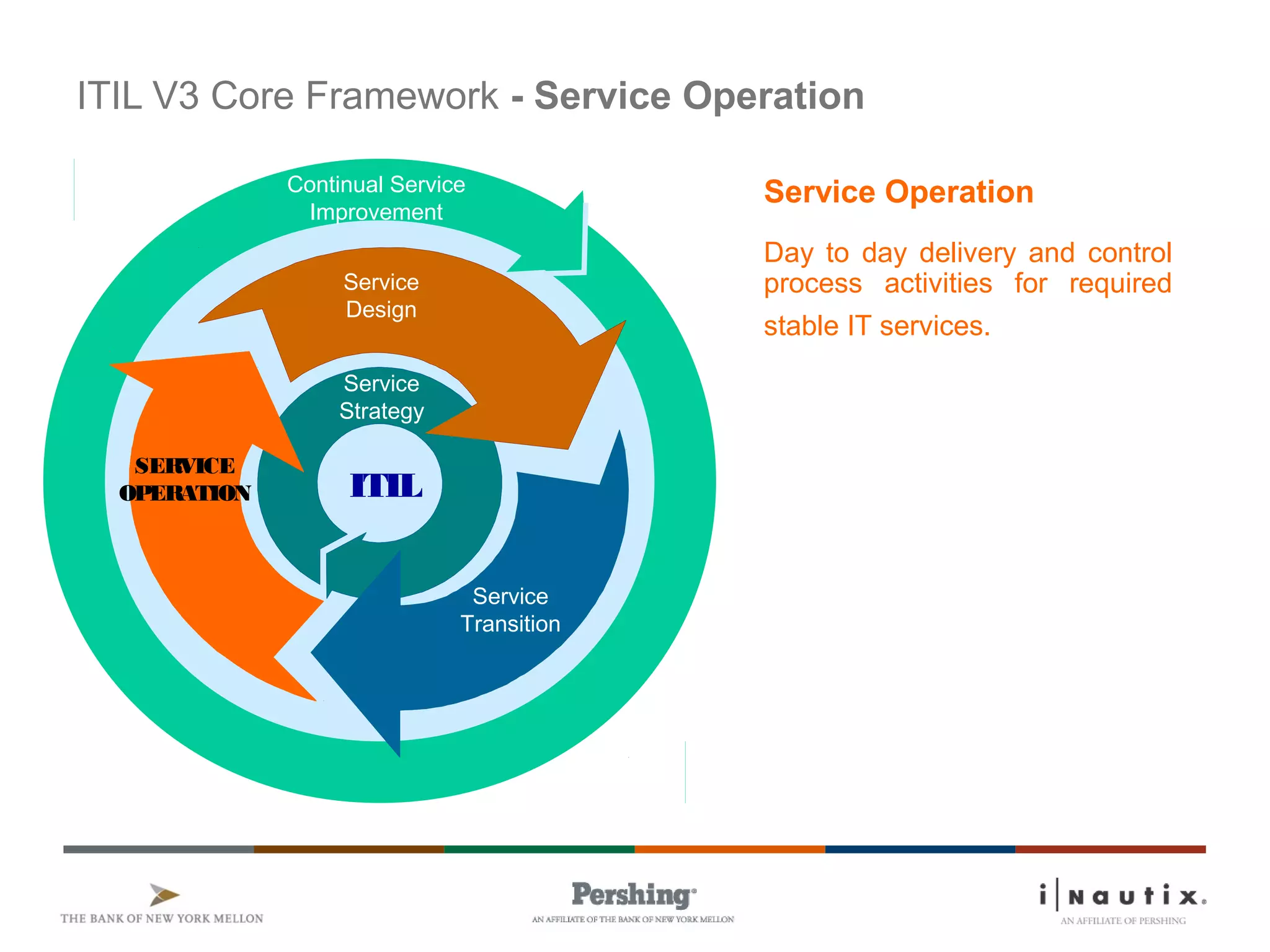



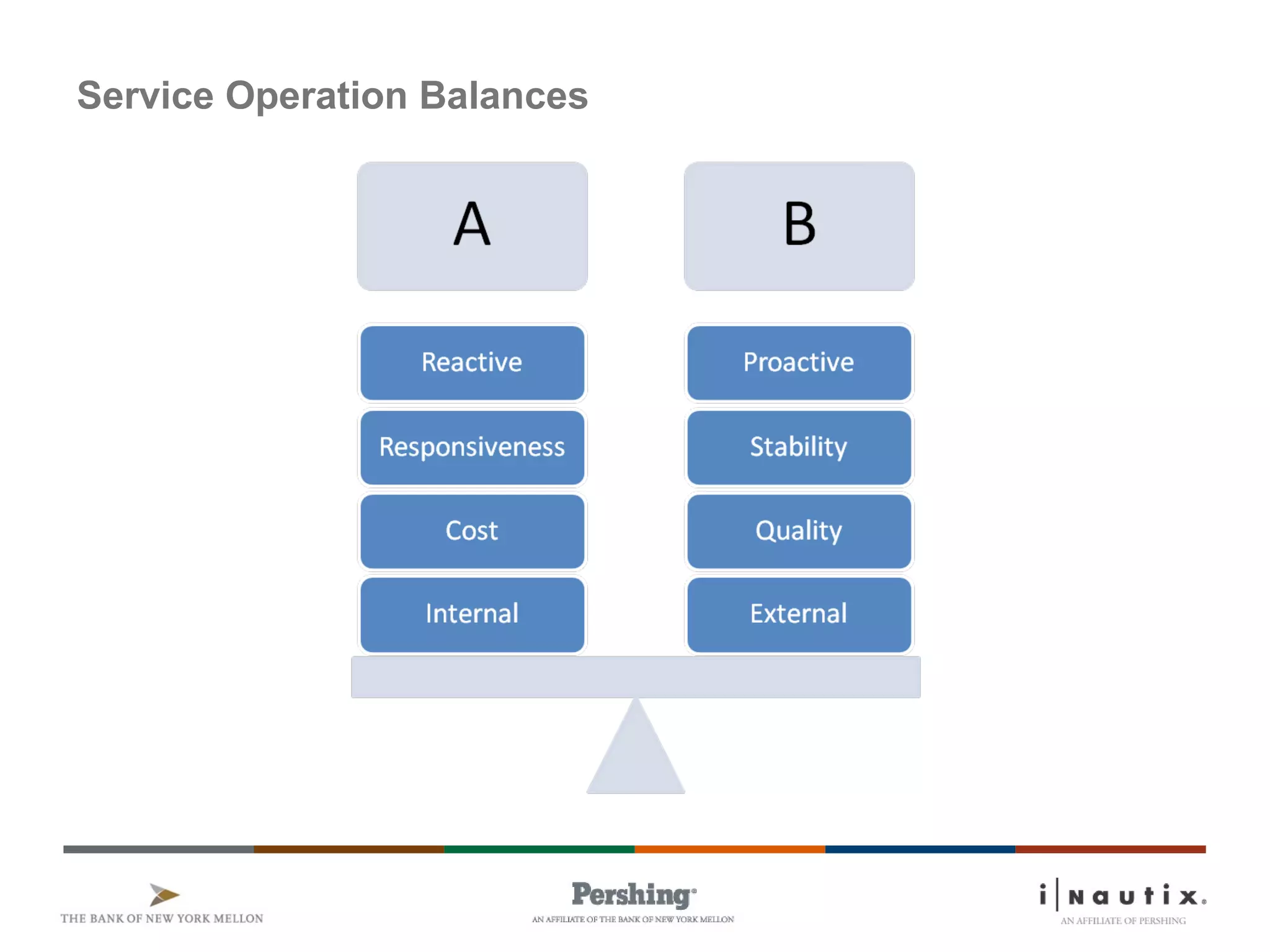





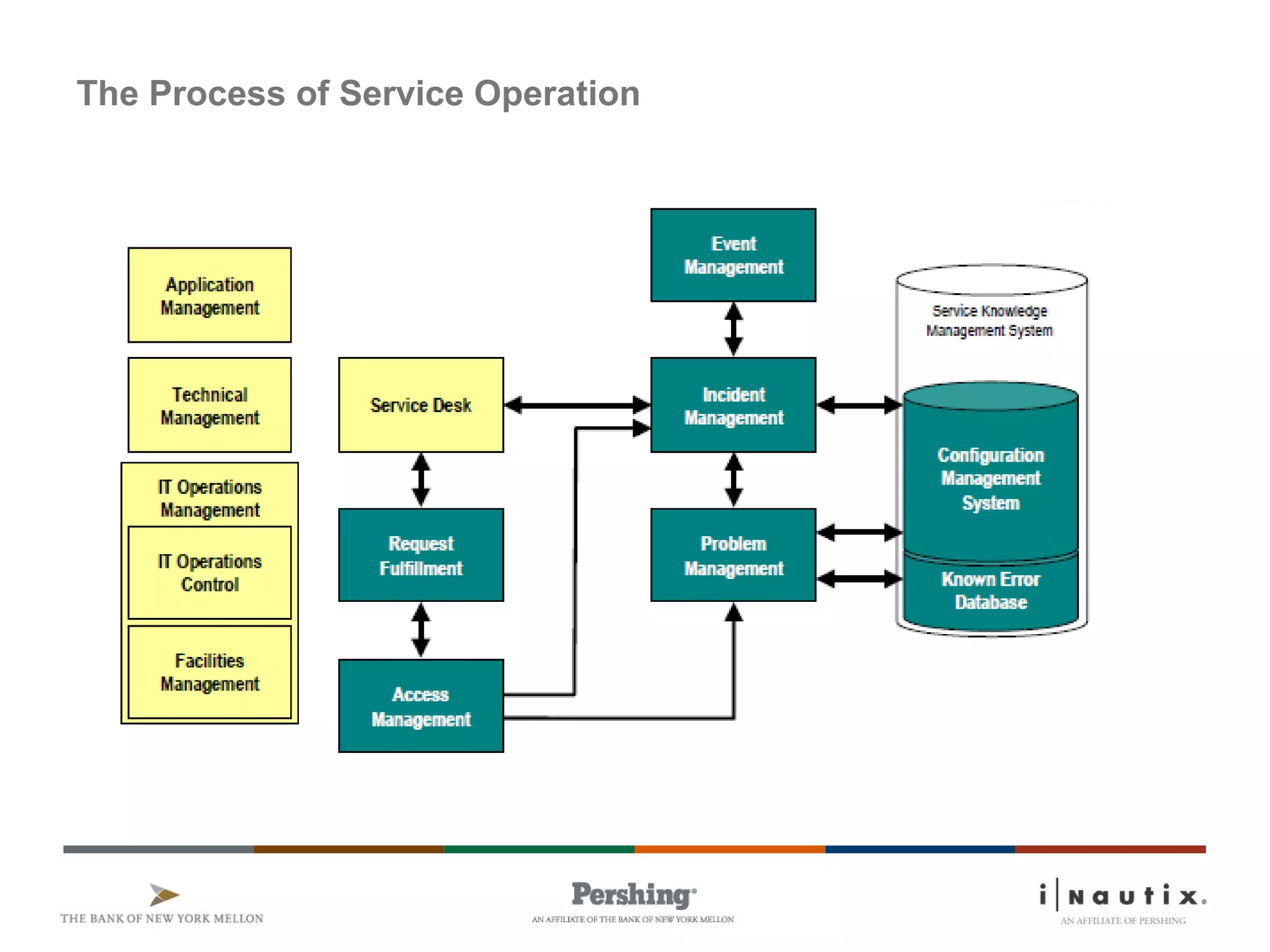


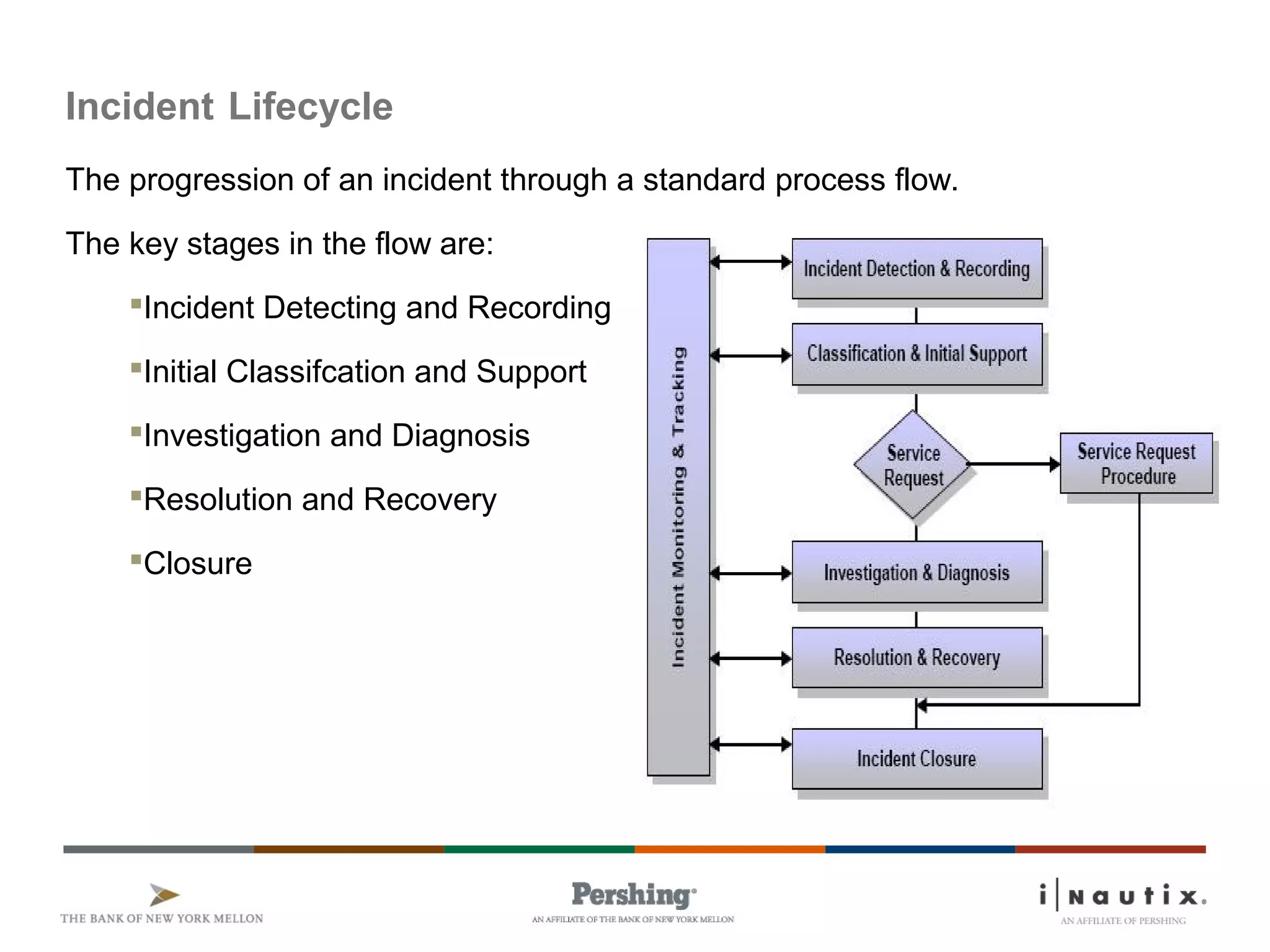


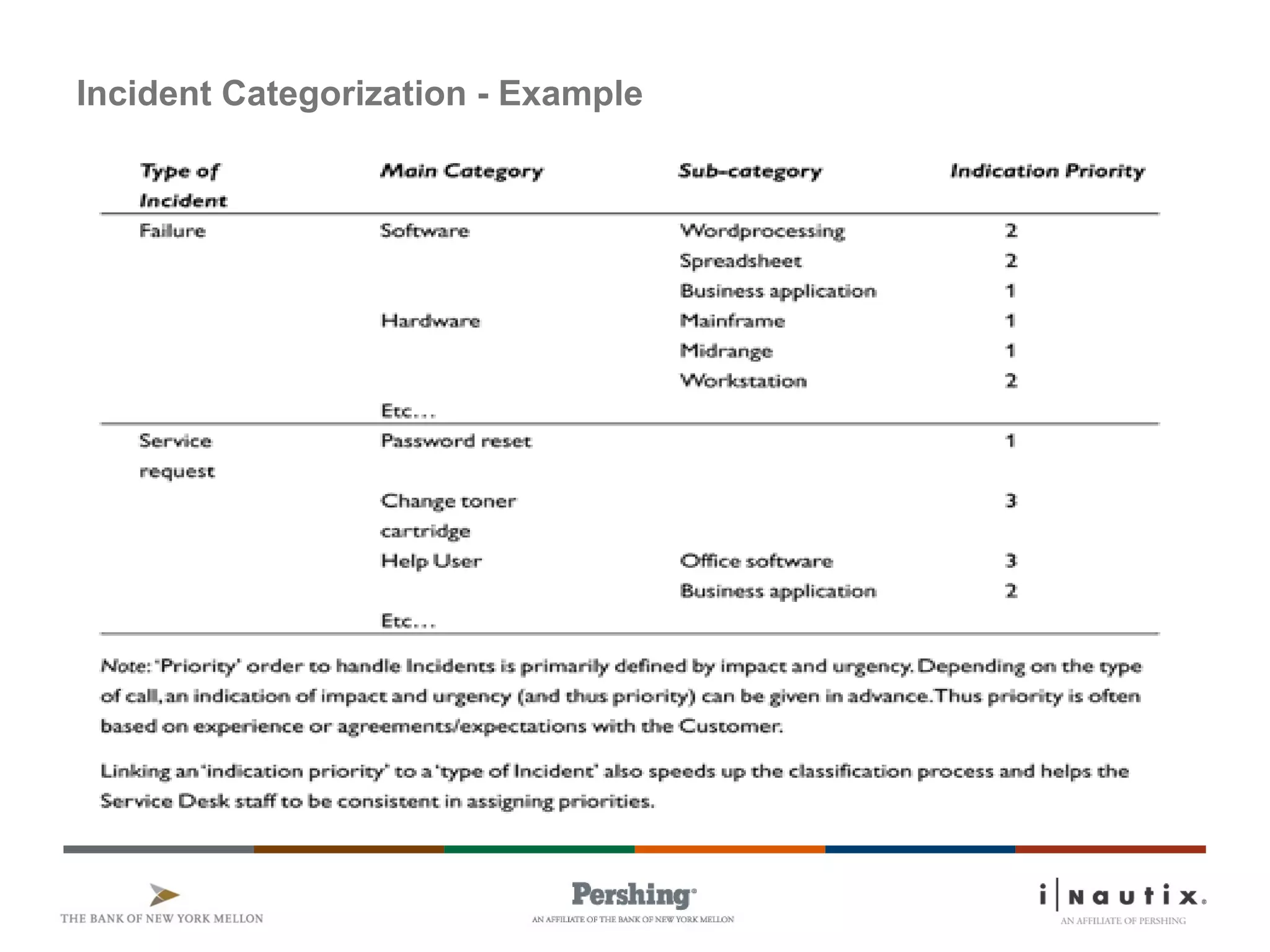





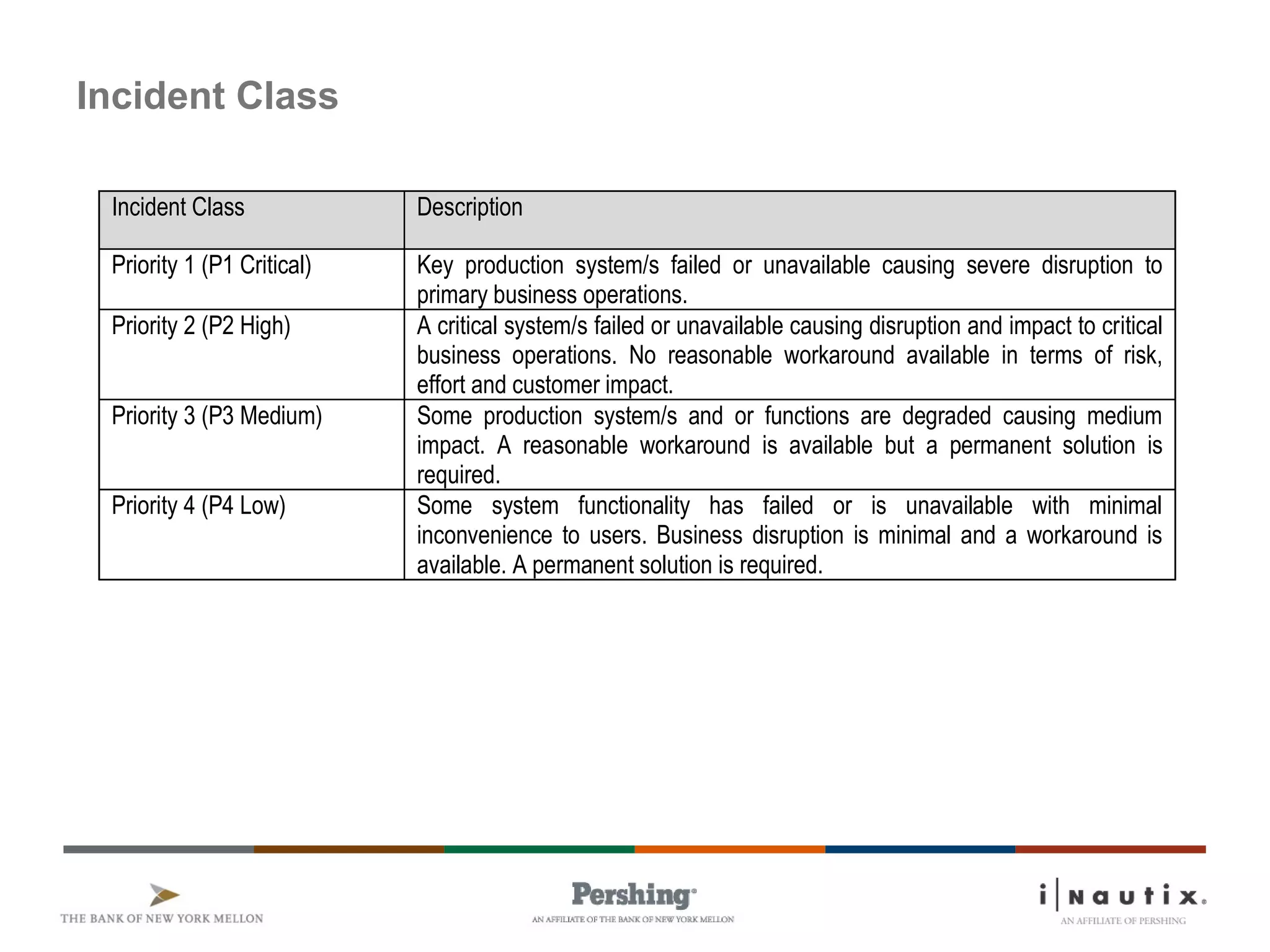
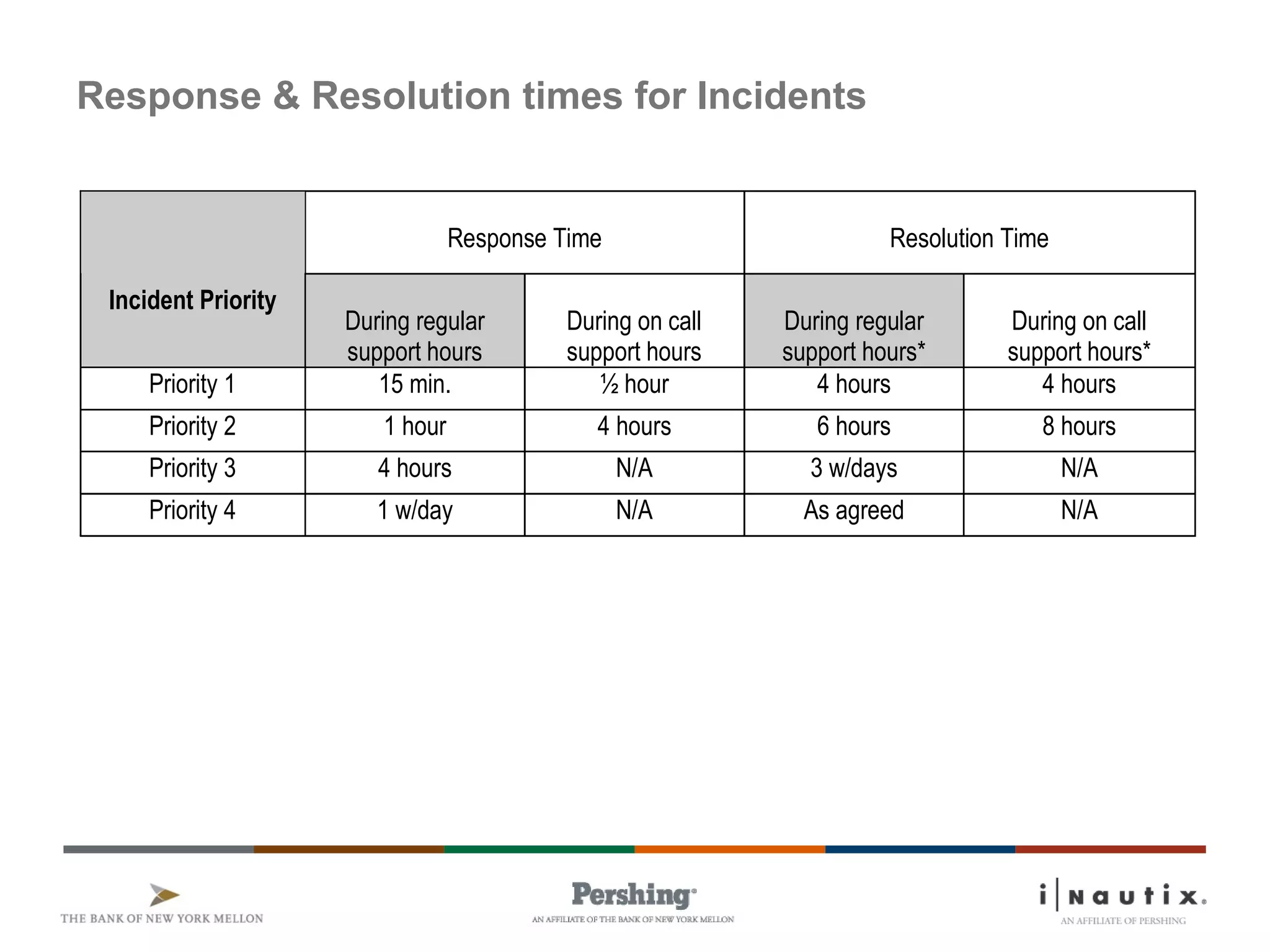

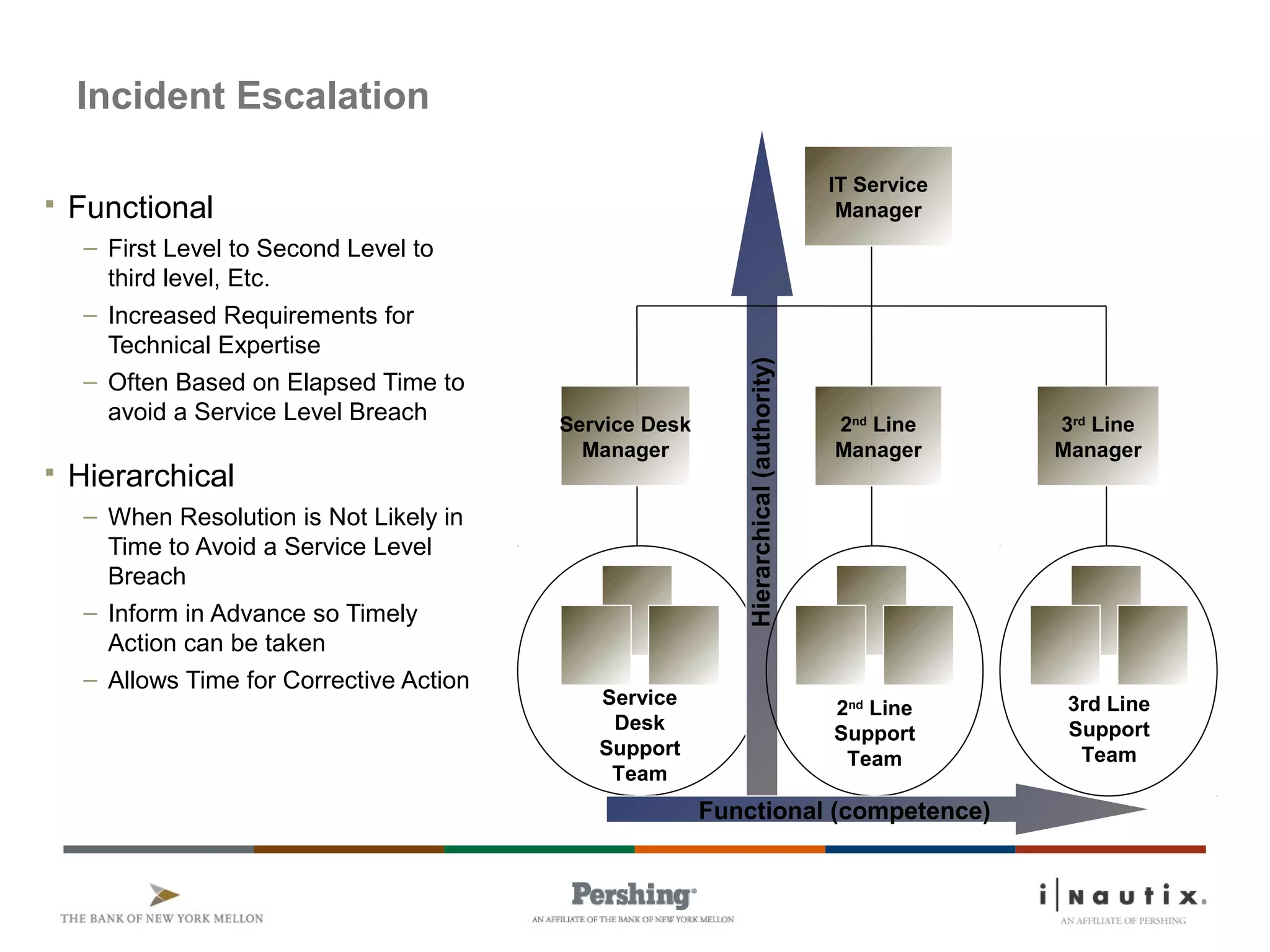
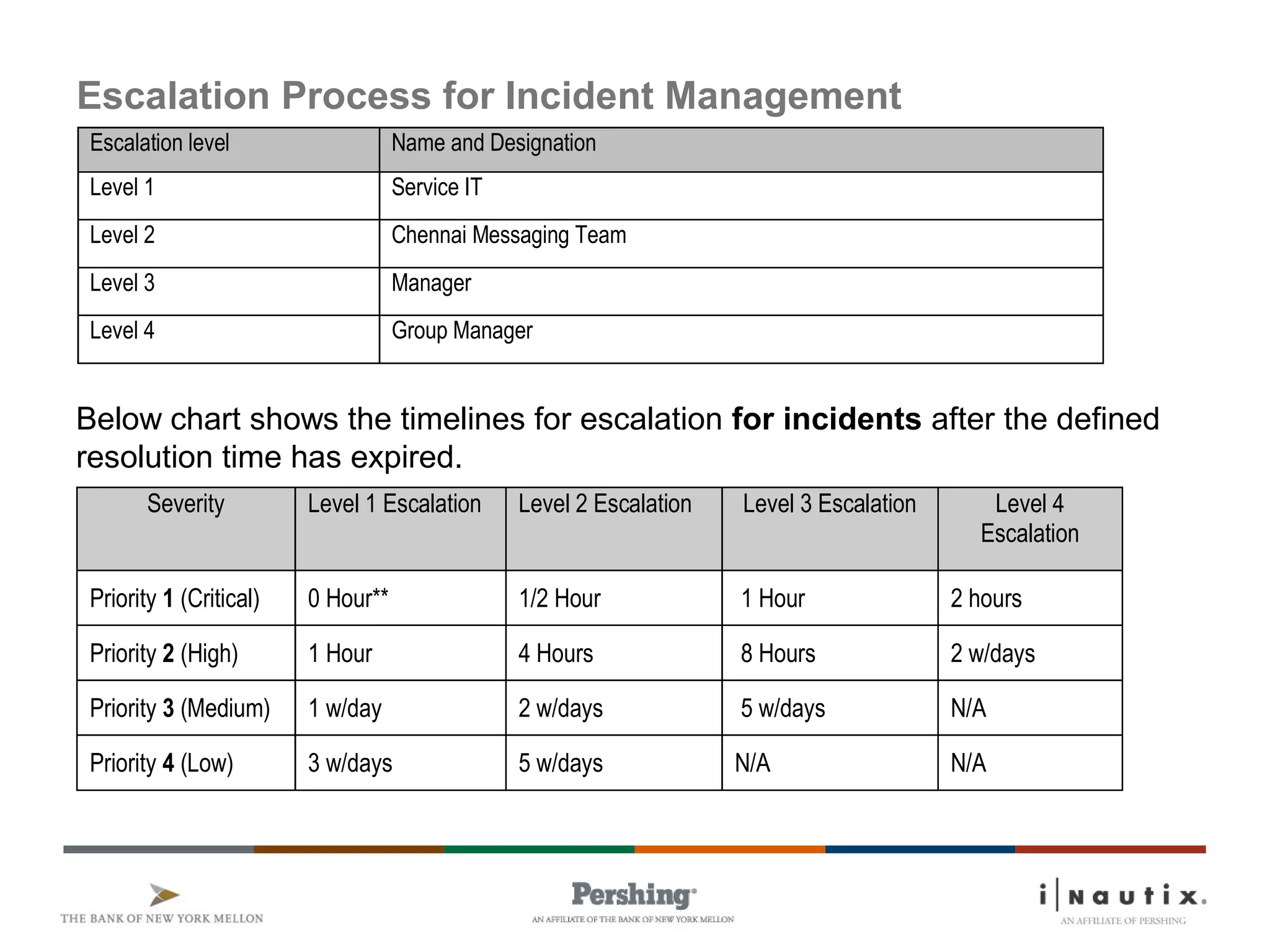


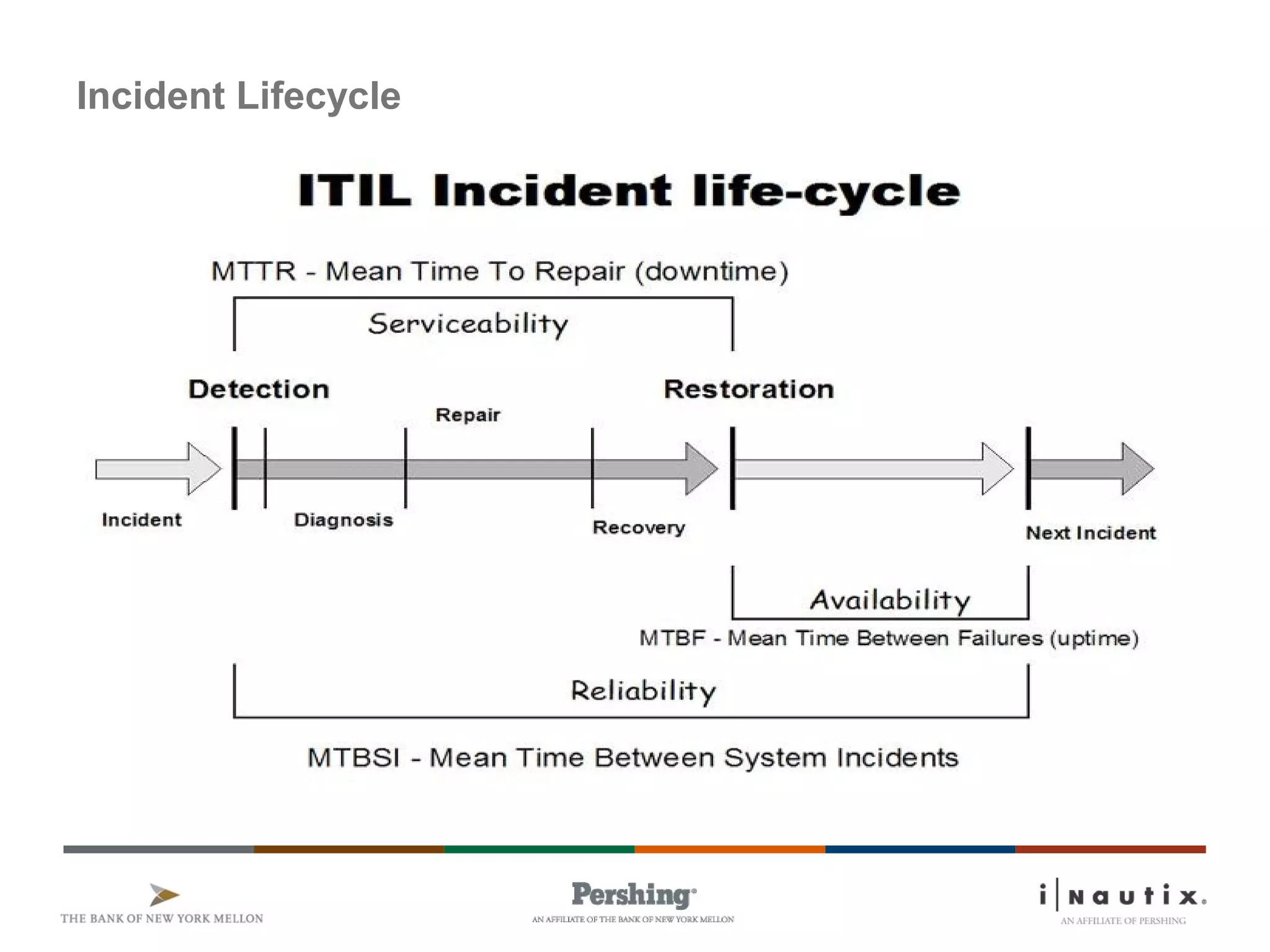
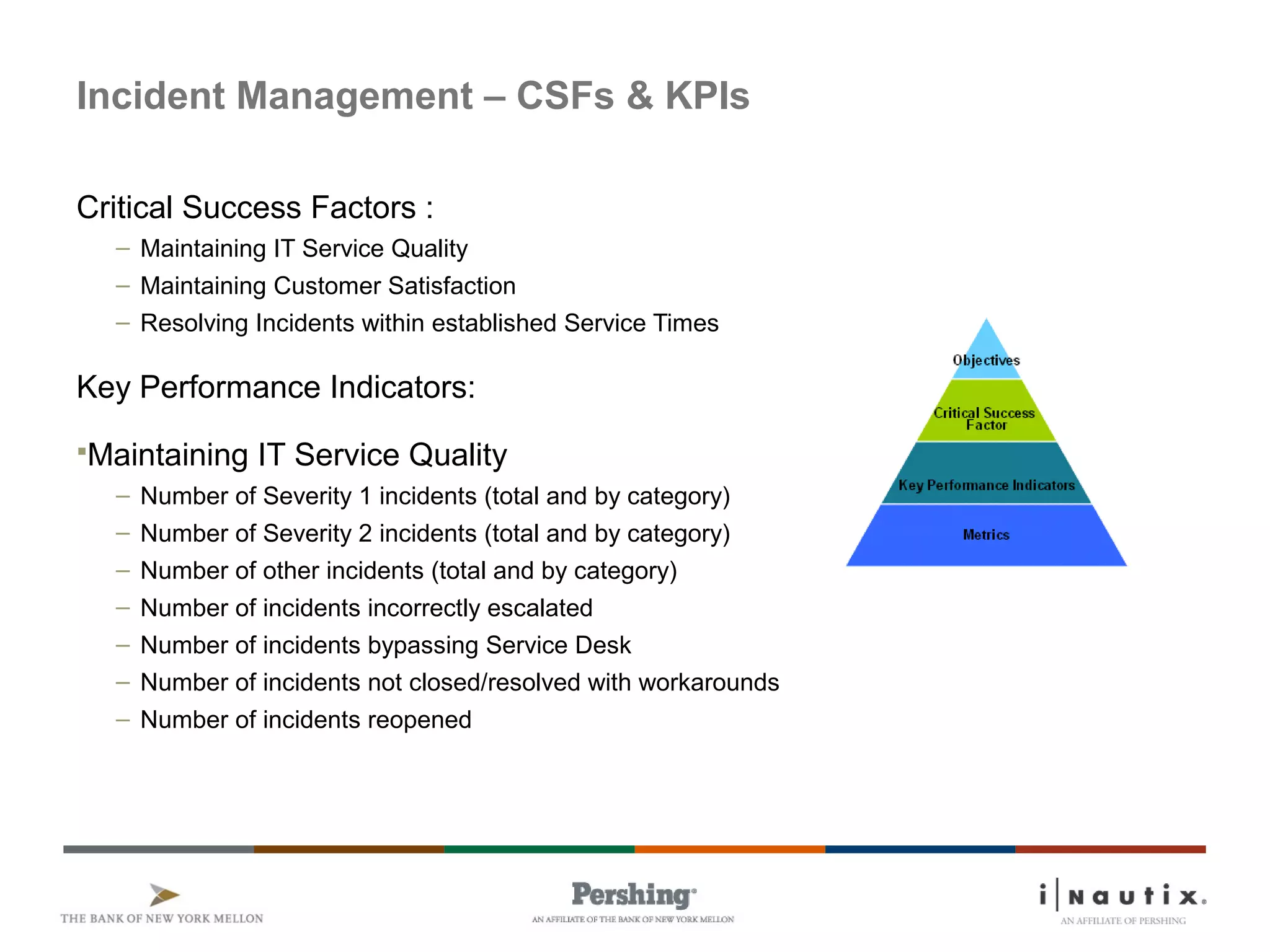
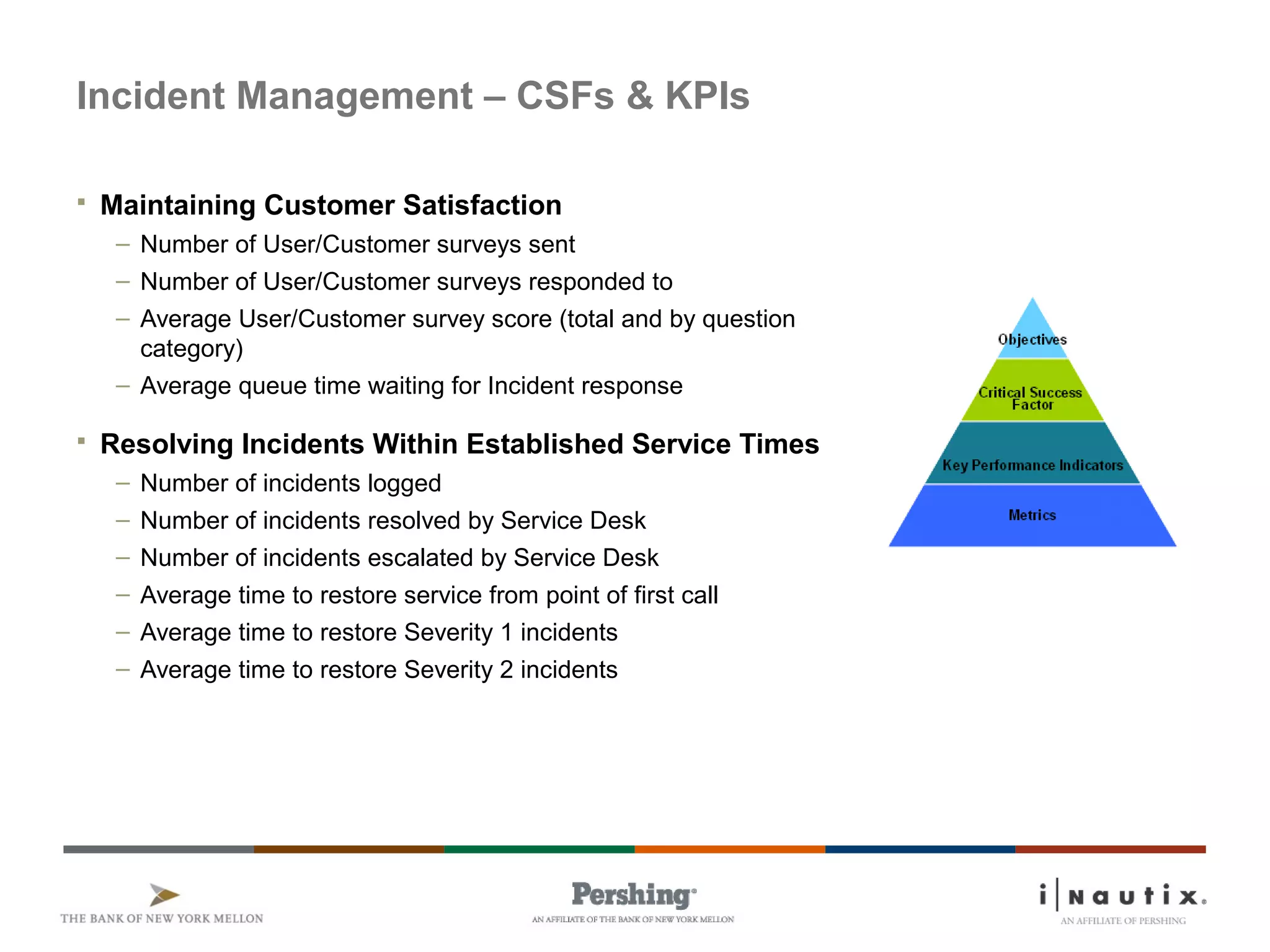





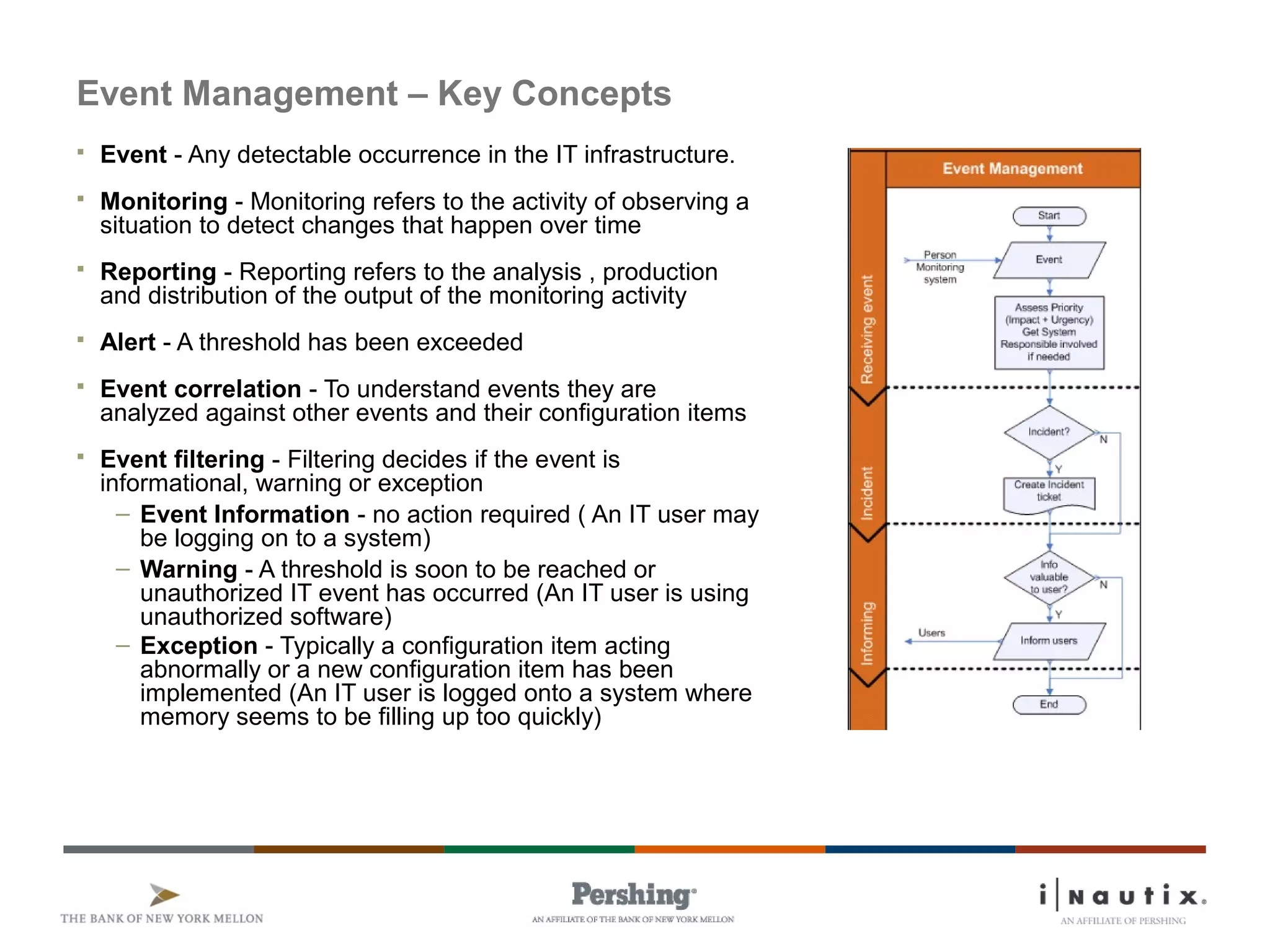






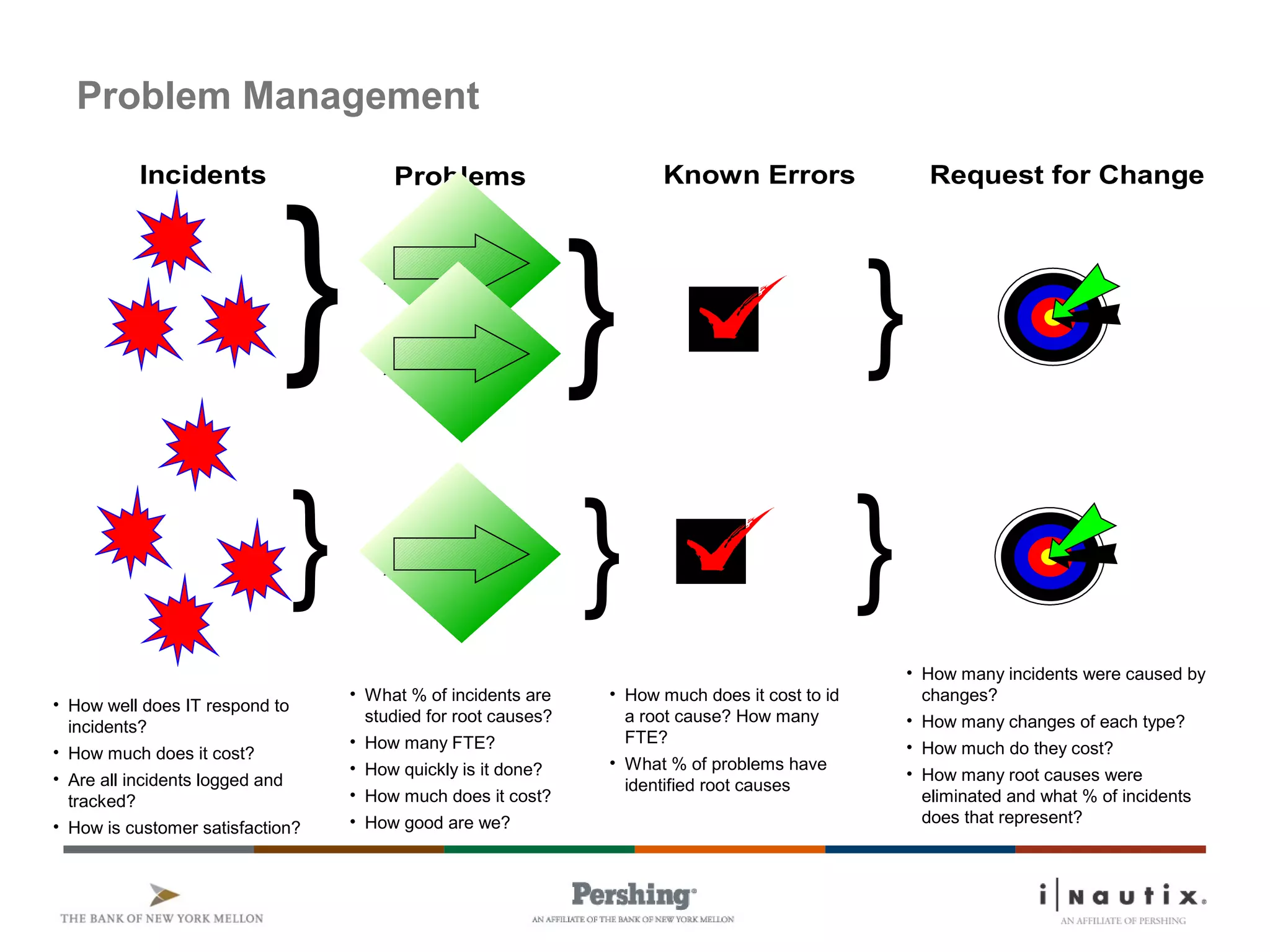

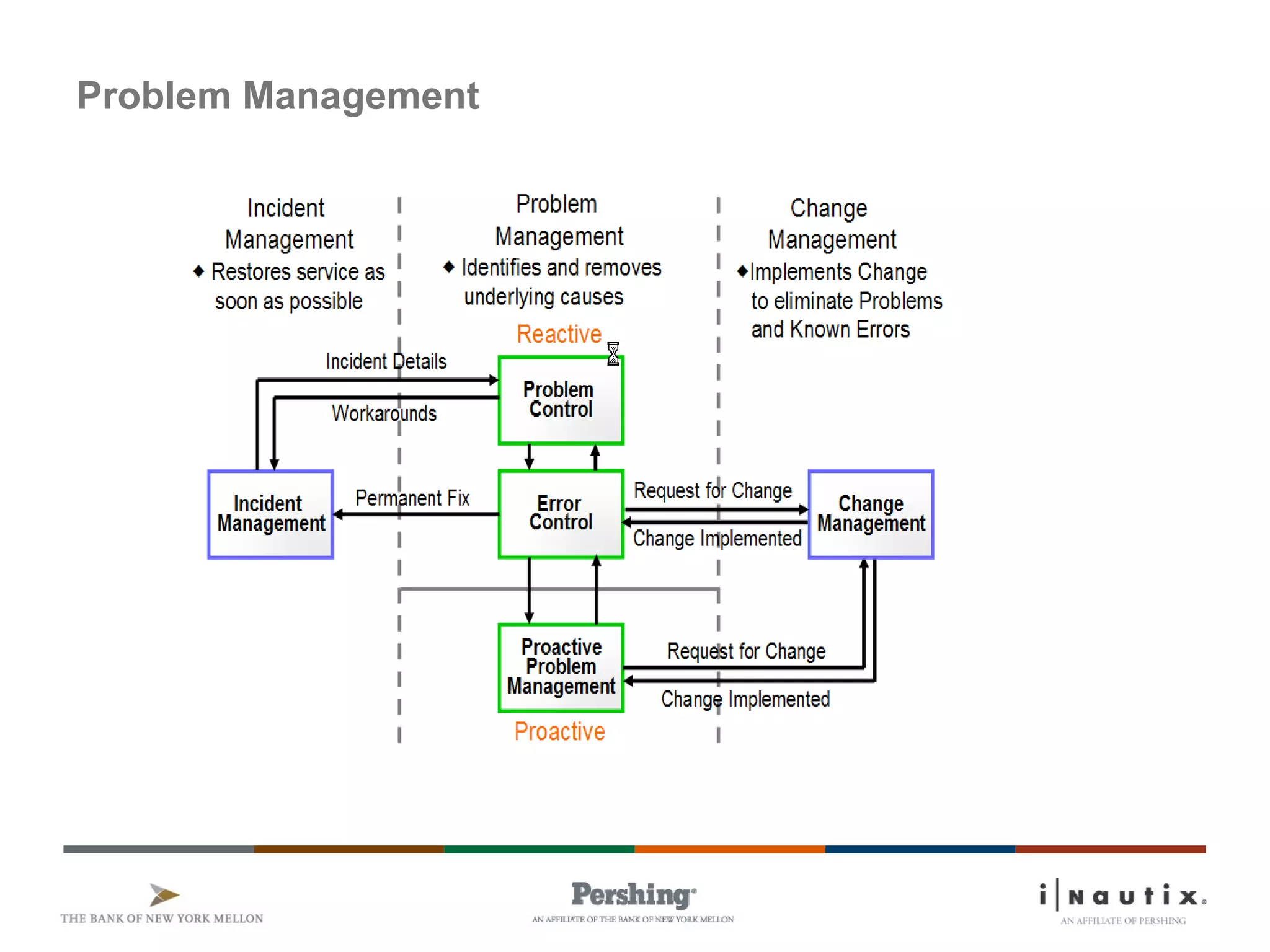






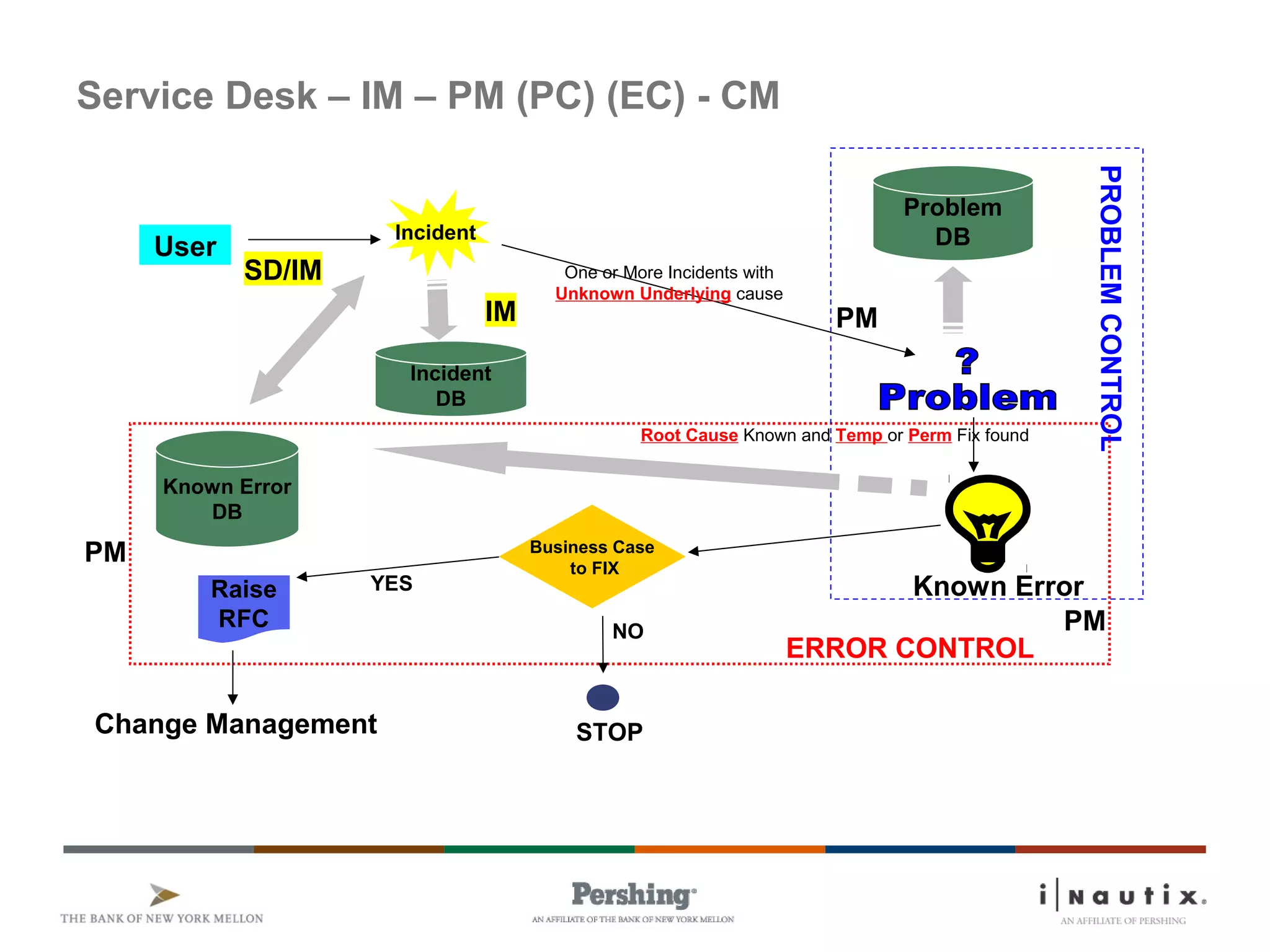
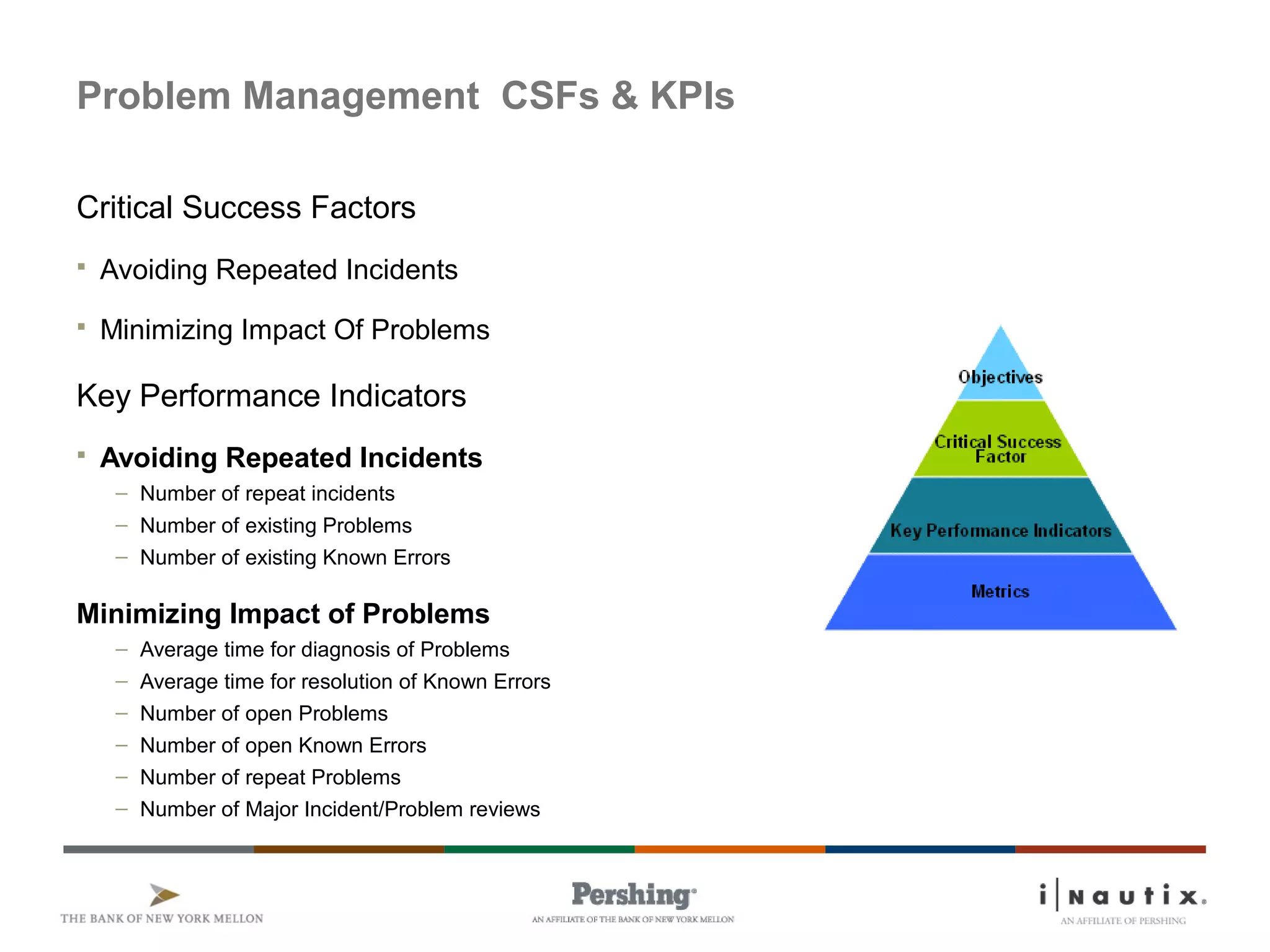













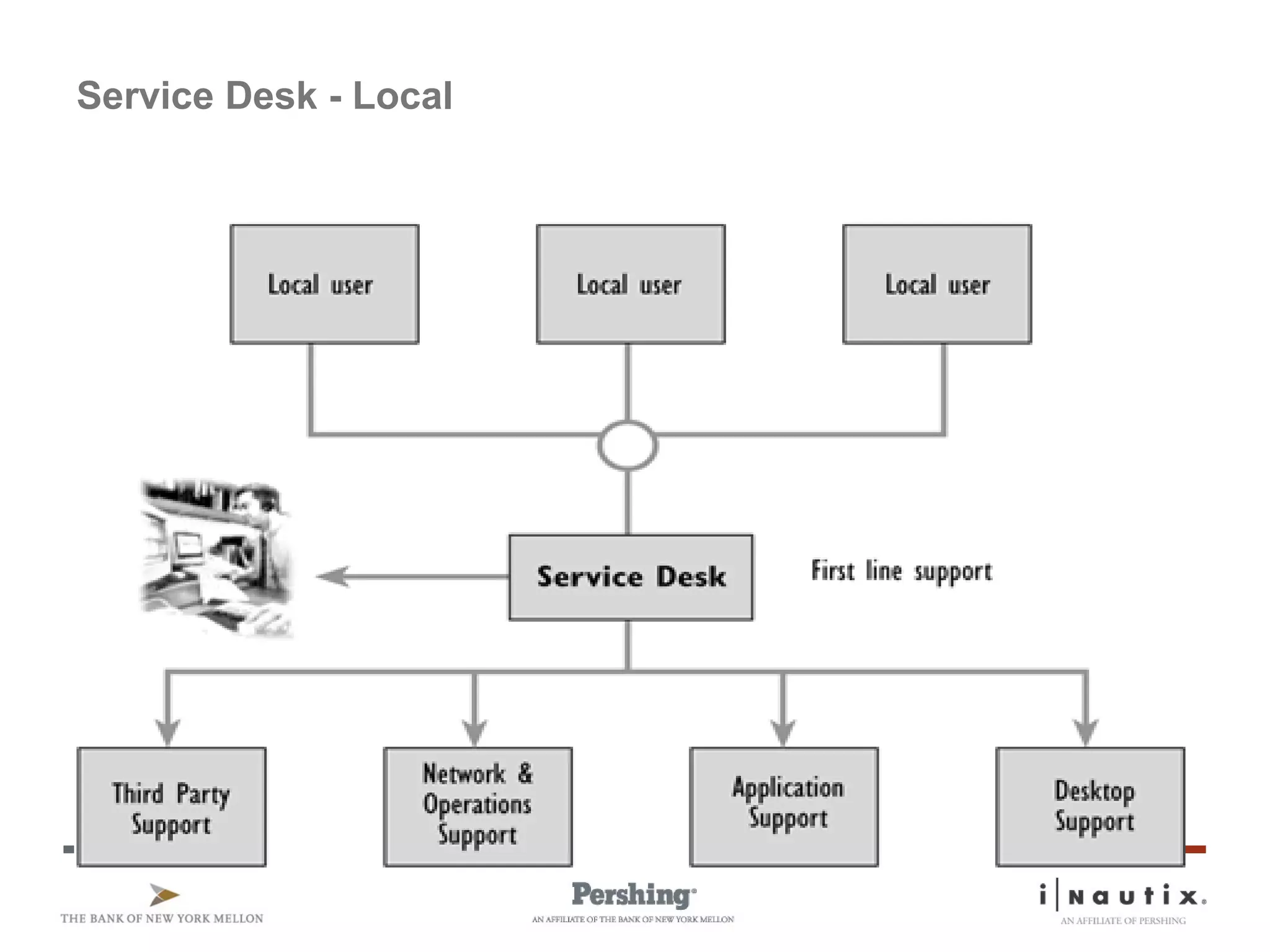

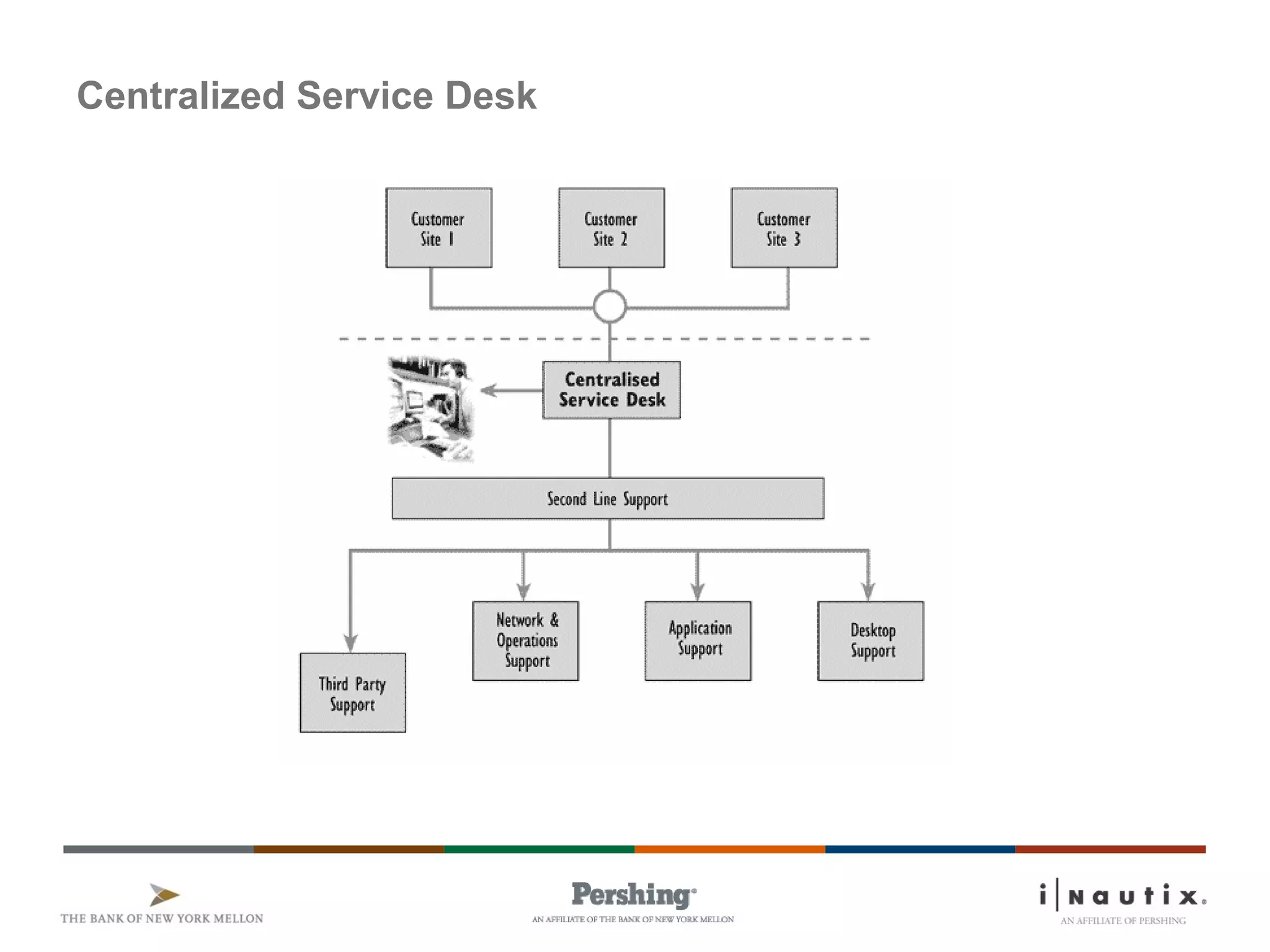

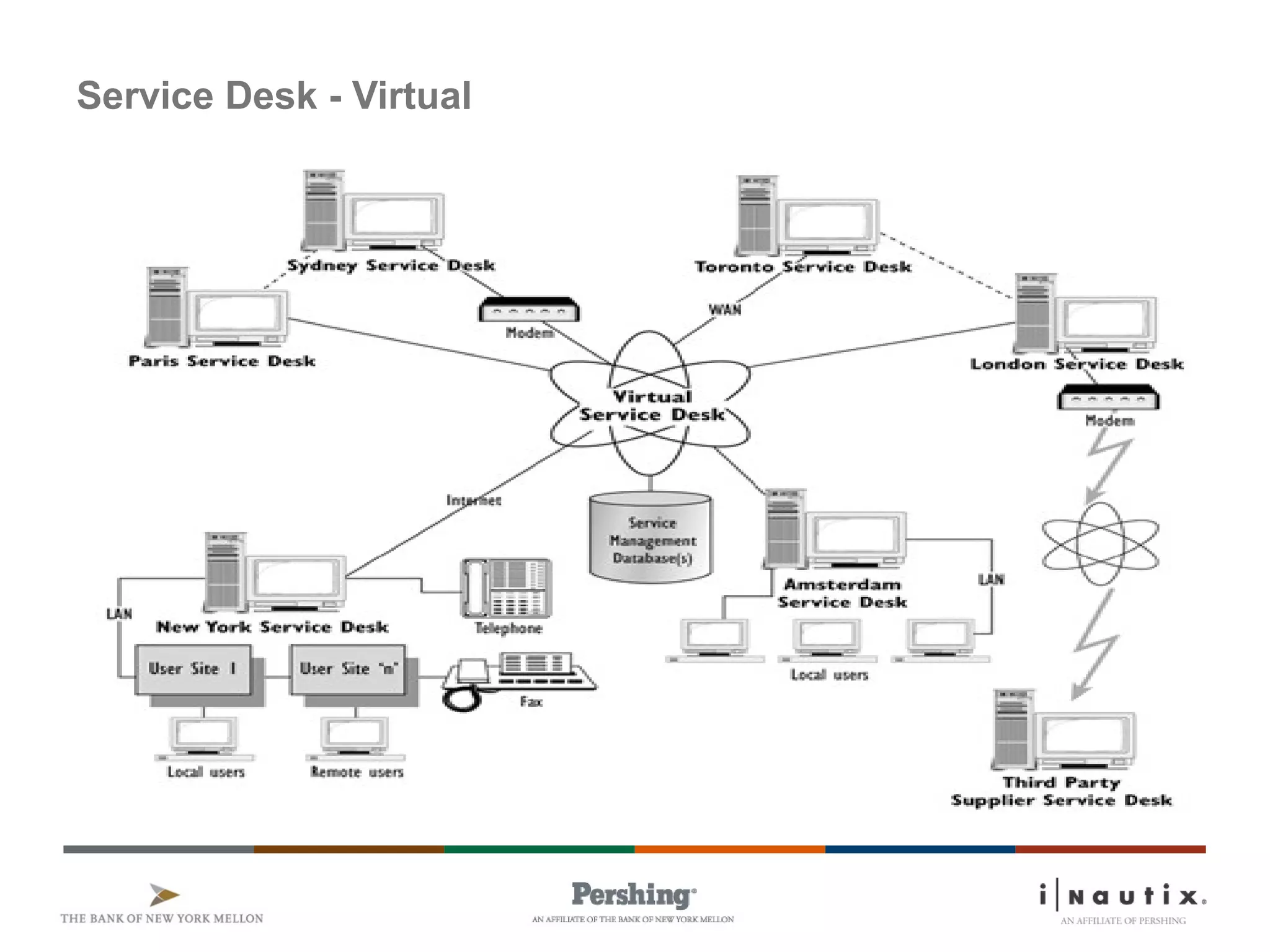




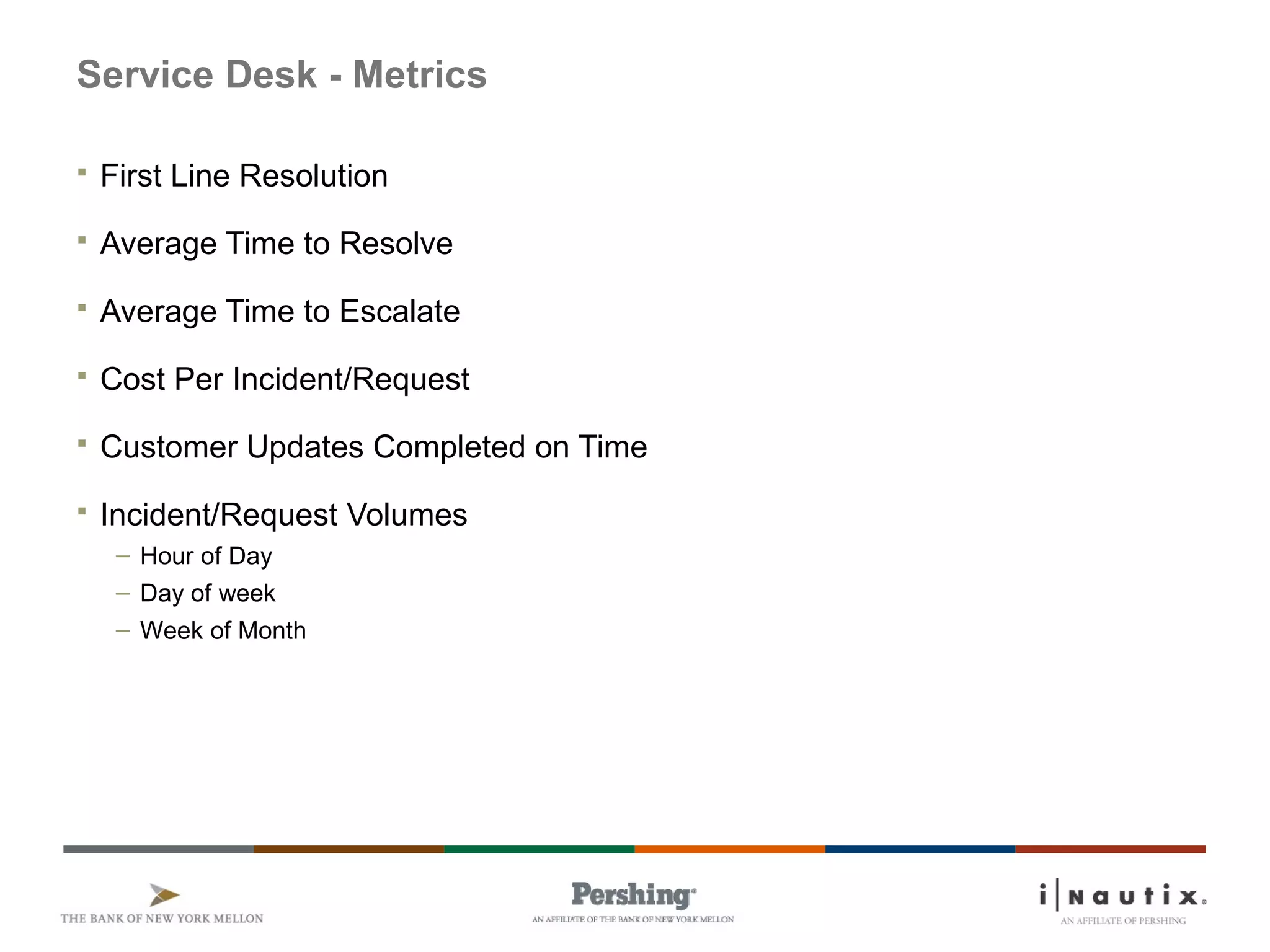






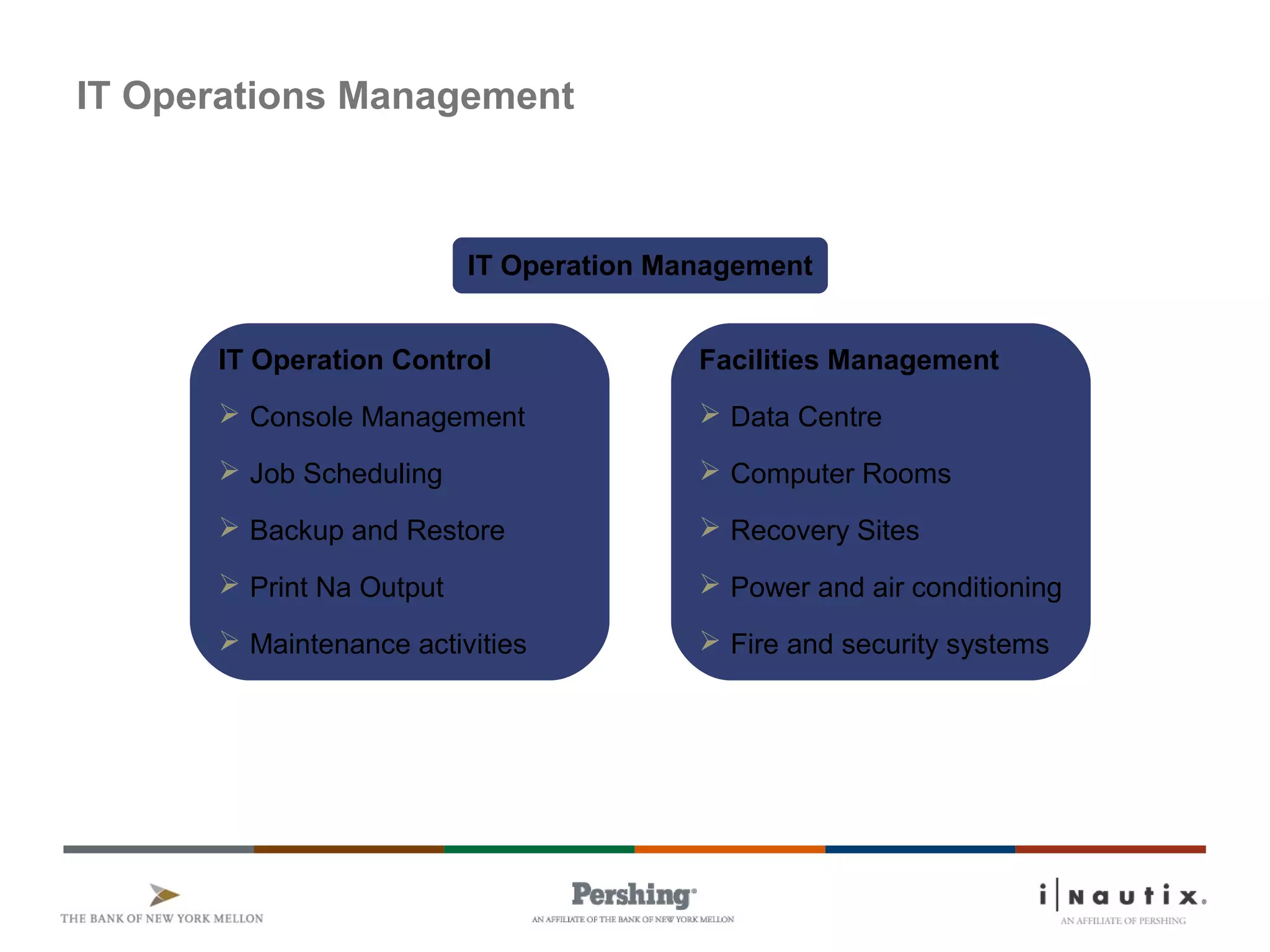

The document discusses the ITIL framework for service operation. It focuses on incident management, which aims to restore normal service operation as quickly as possible when incidents disrupt services. The key stages of incident management are incident detection and recording, initial classification and support, investigation and diagnosis, resolution and recovery, and closure. Incidents are prioritized based on urgency and impact to determine the appropriate response and resolution times. Escalation procedures are also described to ensure issues are addressed in a timely manner.









































































































