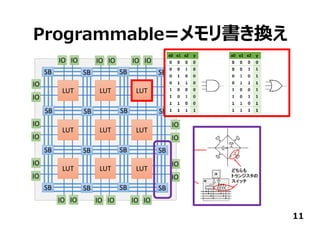
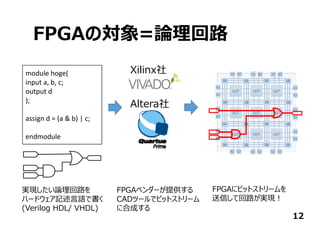
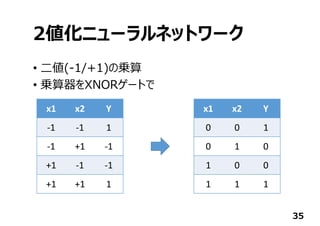
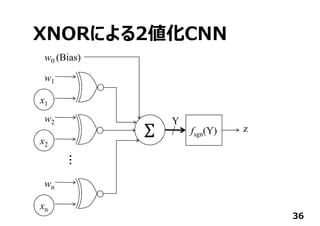
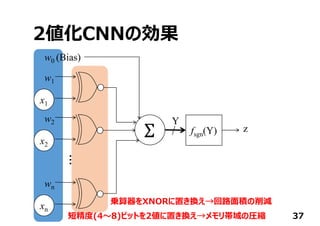
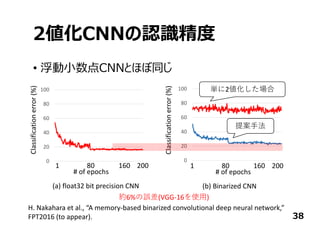
日本Googleオフィスで開催されたTensorFlow User Groupでしゃべったときのスライドです。TensorFlowからFPGAに落とす方法と2値化ディープニューラルネットワークについて。








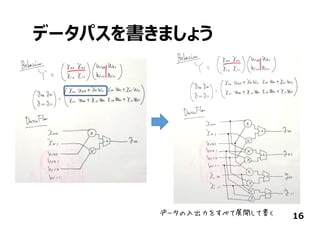
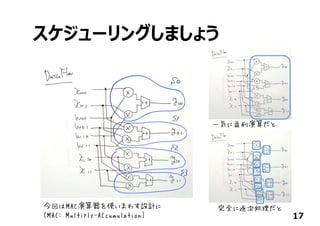
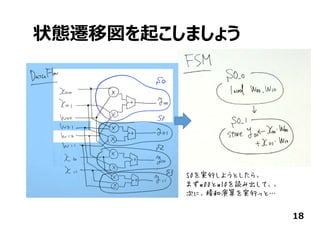
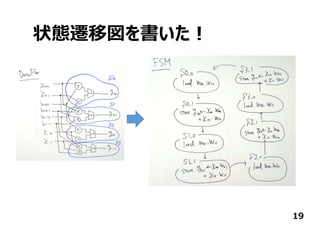
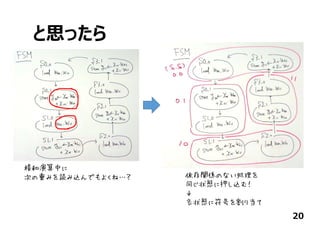




![あともう少し…
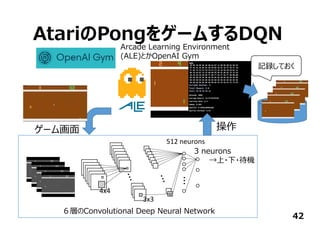
31
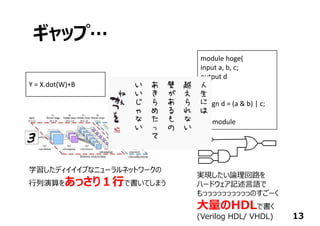
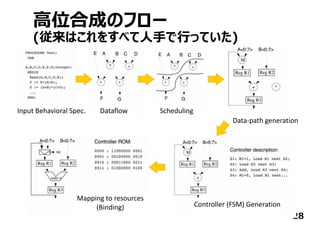
⾏列演算ライブラリの
中⾝をC/C++で書く
ただし、HDLよりは抽象的
(演算器スケジューリング・
FSMは不要)
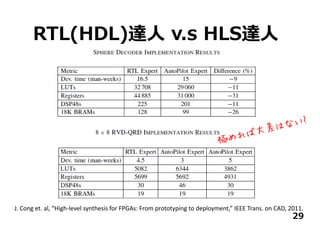
Y = X.dot(W)+B
⾏列演算をあっさり1⾏で
Y=0;
for(i=0; i < m; i++){
for( j = 0; j < n; j++){
Y += X[i][j]*W[j][i];
}
}
⾼位合成ツールが
HDLを吐いてくれるので
従来のフローを通して
FPGAに実現できる](https://image.slidesharecdn.com/tensorflowusergroup2016v1-161012163053/85/Tensor-flow-usergroup-2016-31-320.jpg)
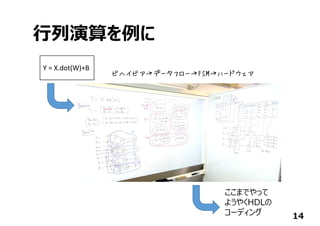
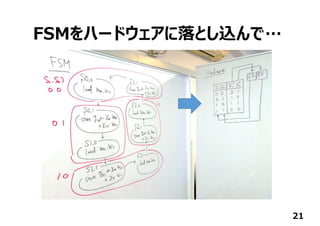
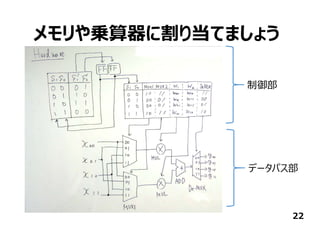
![今回作ったもの
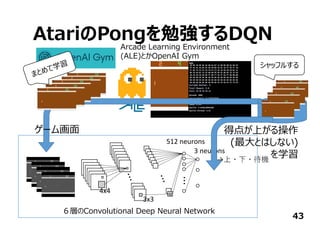
32
⾏列演算ライブラリの
中⾝をC/C++で書く
ただし、HDLよりは抽象的
(演算器スケジューリング・
FSMは不要)
Y = X.dot(W)+bias
ディープニューラルネットワークを
さっくり記述
Y=0;
for(i=0; i < m; i++){
for( j = 0; j < n; j++){
Y += X[i][j]*W[j][i];
}
}
⾼位合成ツールが
HDLを吐いてくれるので
従来のフローを通して
FPGAに実現できる
ここを⾃動⽣成+α](https://image.slidesharecdn.com/tensorflowusergroup2016v1-161012163053/85/Tensor-flow-usergroup-2016-32-320.jpg)




























































![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL Hacks]ディープラーニングを まともに動かすために ハードウェアの人が考えていること](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks1115ueno-181116004417-thumbnail.jpg?width=640&height=640&fit=bounds)













