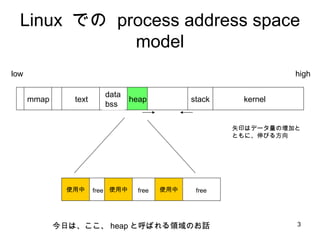
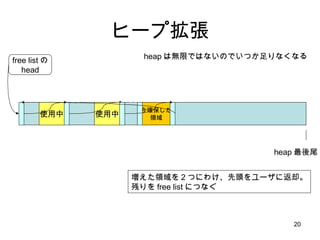
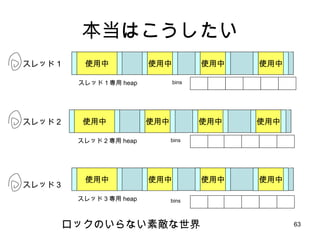
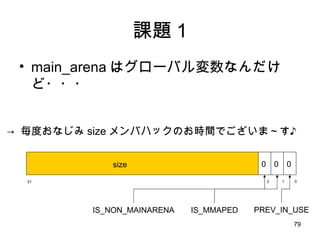
Linux での process address space model kernel stack text mmap data bss heap 矢印はデータ量の増加と ともに、伸びる方向 使用中 使用中 使用中 今日は、ここ、 heap と呼ばれる領域のお話 low high free free free
4.
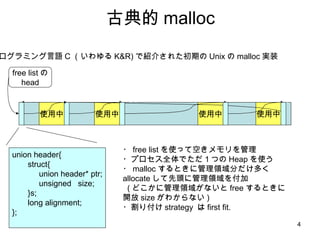
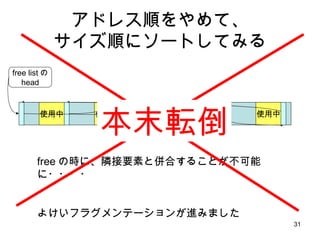
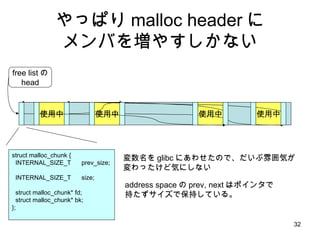
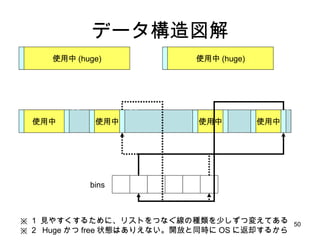
古典的 malloc プログラミング言語C (いわゆる K&R) で紹介された初期の Unix の malloc 実装 使用中 使用中 使用中 free listの head 使用中 ・ free list を使って空きメモリを管理 ・プロセス全体でただ1つの Heap を使う ・ malloc するときに管理領域分だけ多く allocate して先頭に管理領域を付加 ( どこかに管理領域がないと free するときに開放 size がわからない ) ・割り付け strategy は first fit. union header{ struct{ union header* ptr; unsigned size; }s; long alignment; };
5.
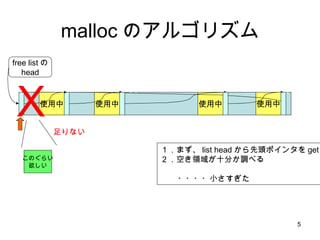
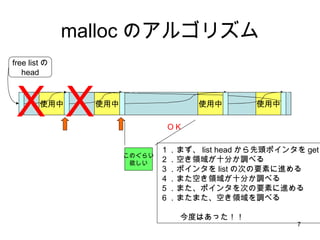
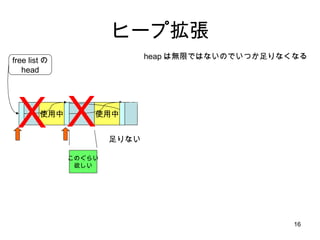
malloc のアルゴリズム 使用中使用中 使用中 free listの head 使用中 このぐらい 欲しい X 足りない 1.まず、 list head から先頭ポインタを get 2.空き領域が十分か調べる ・・・・小さすぎた
6.
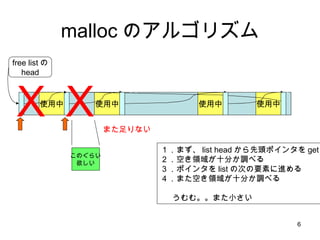
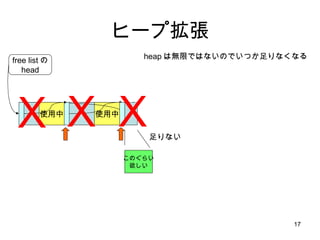
malloc のアルゴリズム 使用中使用中 使用中 free listの head 使用中 X また足りない X このぐらい 欲しい 1.まず、 list head から先頭ポインタを get 2.空き領域が十分か調べる 3.ポインタを list の次の要素に進める 4.また空き領域が十分か調べる うむむ。。また小さい
7.
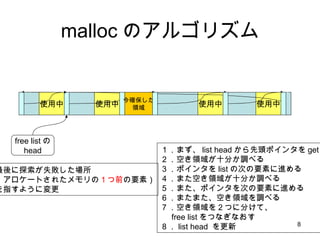
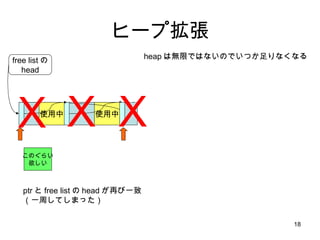
malloc のアルゴリズム 使用中使用中 使用中 free listの head 使用中 1.まず、 list head から先頭ポインタを get 2.空き領域が十分か調べる 3.ポインタを list の次の要素に進める 4.また空き領域が十分か調べる 5.また、ポインタを次の要素に進める 6.またまた、空き領域を調べる 今度はあった!! X OK X このぐらい 欲しい
8.
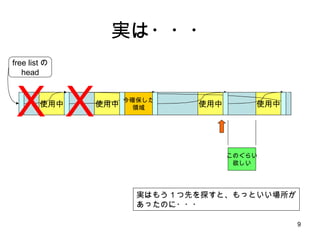
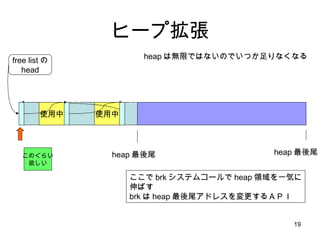
malloc のアルゴリズム 使用中使用中 使用中 free listの head 使用中 1.まず、 list head から先頭ポインタを get 2.空き領域が十分か調べる 3.ポインタを list の次の要素に進める 4.また空き領域が十分か調べる 5.また、ポインタを次の要素に進める 6.またまた、空き領域を調べる 7.空き領域を2つに分けて、 free list をつなぎなおす 8. list head を更新 今確保した 領域 最後に探索が失敗した場所 (アロケートされたメモリの 1つ前 の要素) を指すように変更
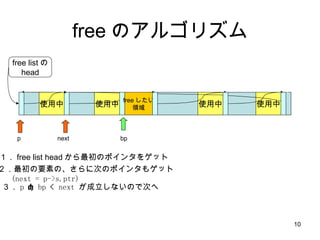
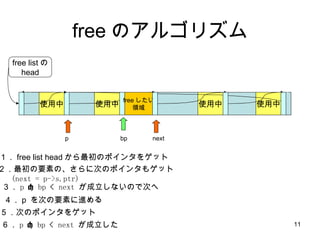
free のアルゴリズム 使用中使用中 使用中 free listの head 使用中 free したい 領域 1. free list head から最初のポインタをゲット 2.最初の要素の、さらに次のポインタもゲット (next = p->s.ptr) 3. p < bp < next が成立しないので次へ bp p next
11.
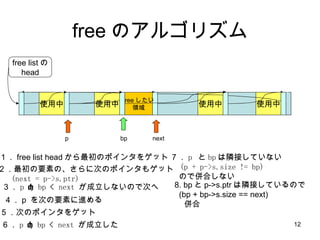
free のアルゴリズム 使用中使用中 使用中 free listの head 使用中 free したい 領域 bp p next 1. free list head から最初のポインタをゲット 2.最初の要素の、さらに次のポインタもゲット (next = p->s.ptr) 3. p < bp < next が成立しないので次へ 4. p を次の要素に進める 5 .次のポインタをゲット 6 . p < bp < next が成立した
12.
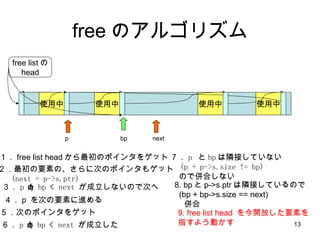
free のアルゴリズム 使用中使用中 使用中 free listの head 使用中 bp p 7 . p と bp は隣接していない (p + p->s.size != bp) ので併合しない next 1. free list head から最初のポインタをゲット 2.最初の要素の、さらに次のポインタもゲット (next = p->s.ptr) 3. p < bp < next が成立しないので次へ 4. p を次の要素に進める 5 .次のポインタをゲット 6 . p < bp < next が成立した 8. bp と p->s.ptr は隣接しているので (bp + bp->s.size == next) 併合 free したい 領域
13.
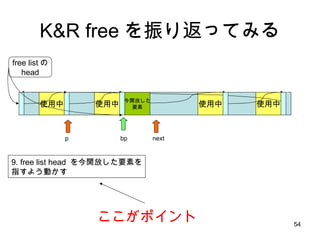
free のアルゴリズム 使用中使用中 使用中 free listの head 使用中 bp p 7 . p と bp は隣接していない (p + p->s.size != bp) ので併合しない next 1. free list head から最初のポインタをゲット 2.最初の要素の、さらに次のポインタもゲット (next = p->s.ptr) 3. p < bp < next が成立しないので次へ 4. p を次の要素に進める 5 .次のポインタをゲット 6 . p < bp < next が成立した 8. bp と p->s.ptr は隣接しているので (bp + bp->s.size == next) 併合 9. free list head を今開放した要素を 指すよう動かす
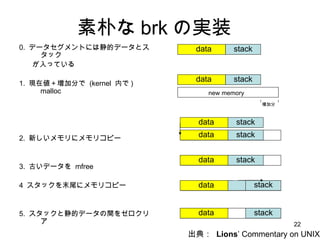
素朴な brk の実装 0. データセグメントには静的データとスタック が入っている 1. 現在値+増加分で (kernel 内で ) malloc 2. 新しいメモリにメモリコピー 3. 古いデータを mfree 4 スタックを末尾にメモリコピー 5. スタックと静的データの間をゼロクリア new memory data data stack stack 出典: Lions ’ Commentary on UNIX 増加分 data stack data stack data stack data stack data stack
small bin 1624 32 40 504 ・・・ size index 2 63 3 4 5 chunks これで小さいサイズの malloc が /* 8 の倍数に切り上げ */ size = request2size(req); if( size <= 512 ) { bin_index = size/8; chunk = bins[bin_index].bk; unlink(chunk); /* remove freelist */ return chunk + sizeof(size_t)*2; } このぐらい簡単に終わる 構造体とかはたいてい、このぐらいのサイズにおさまるよね? best fit どころか、 just fit アロケータですよ。と 8 8 8 8 8 bin width free list head の配列
44.
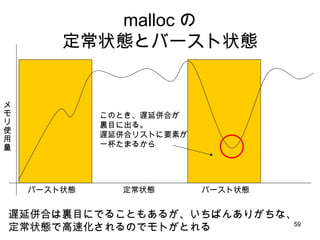
さらに改良 512byte overの部分が手付かず でも、大きいサイズにも 8byte おきに bin を用意するのは現実的じゃない でもリストを複数もつ。 というアイデアは悪くない
45.
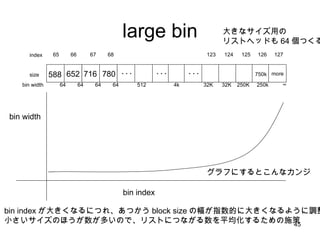
large bin 588652 716 780 ・・・ size index 65 123 66 67 68 64 64 64 64 32K bin width 124 32K 125 250K 126 250k 127 ∞ グラフにするとこんなカンジ bin width bin index bin index が大きくなるにつれ、あつかう block size の幅が指数的に大きくなるように調整 小さいサイズのほうが数が多いので、リストにつながる数を平均化するための施策 大きなサイズ用の リストヘッドも 64 個つくる ・・・ 512 4k ・・・ 750k more
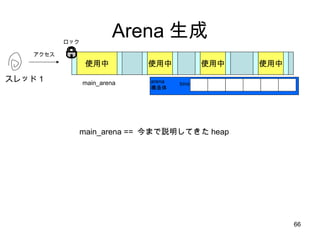
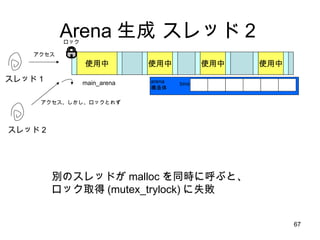
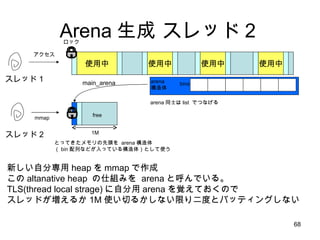
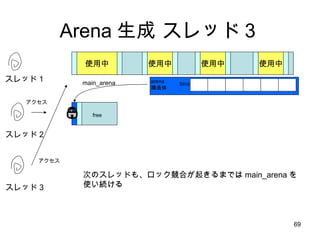
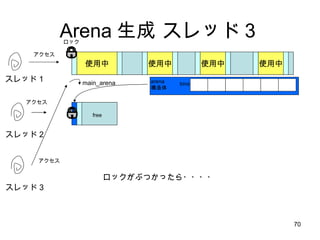
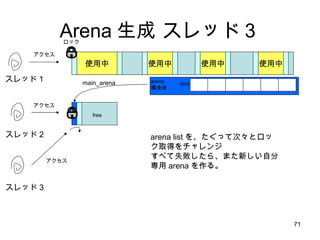
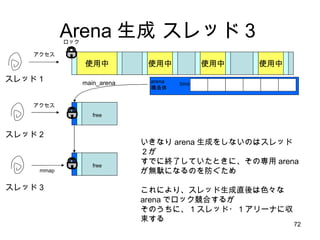
1スレッド:1 Arena の隠れた利点SMP マシンでは、別の CPU からアクセスしたメモリは自分 CPU のキャッシュには乗らないのでラストアクセスを単純に管理してはうまくいかない しかし、ユーザ空間から自分がどの CPU で動いているのか明に意識するのは無理 (いつのまにか勝手に変わるし) そこでカーネルがもつスレッドの CPU affinity スケジューリングに着目して、自分スレッドがアクセスしたデータは自分 CPU でアクセスした確率が高いと考える スレッド専用メモリ=キャッシュヒット率がものすごく Up!



















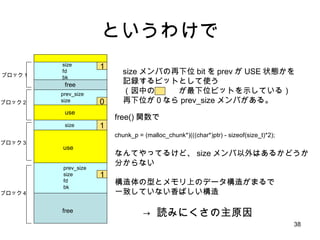
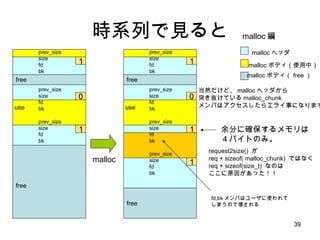
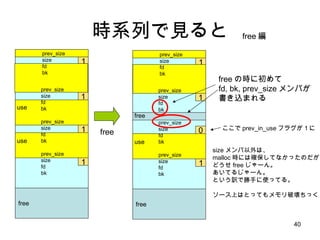


![small bin 16 24 32 40 504 ・・・ size index 2 63 3 4 5 chunks これで小さいサイズの malloc が /* 8 の倍数に切り上げ */ size = request2size(req); if( size <= 512 ) { bin_index = size/8; chunk = bins[bin_index].bk; unlink(chunk); /* remove freelist */ return chunk + sizeof(size_t)*2; } このぐらい簡単に終わる 構造体とかはたいてい、このぐらいのサイズにおさまるよね? best fit どころか、 just fit アロケータですよ。と 8 8 8 8 8 bin width free list head の配列](https://image.slidesharecdn.com/glibcmalloc-110710054847-phpapp01/85/Glibc-malloc-internal-43-320.jpg)










![バッファの遅延合体 その2 gligc malloc では最低確保サイズが 32 なので bins[0] と bins[1] は使ってない bins[1] をこの遅延されてる block をつなげるリストのリストヘッドとして特別な意味で用いる ソースコード上は unsorted_chunk と呼ばれているが、ソートしない=時系列順である。 リストをたぐって、要求サイズと一致するものを検索 要求サイズと一致しないものは、この時点で、隣と併合して実際の free 処理](https://image.slidesharecdn.com/glibcmalloc-110710054847-phpapp01/85/Glibc-malloc-internal-57-320.jpg)














































![SECCON 2016 Online CTF [Memory Analysis] Write-Up (ver.korean)](https://cdn.slidesharecdn.com/ss_thumbnails/seccon2016onlinectfmemoryanalysiswrite-upver-161217144042-thumbnail.jpg?width=640&height=640&fit=bounds)














![[CB16] House of Einherjar :GLIBC上の新たなヒープ活用テクニック by 松隈大樹](https://cdn.slidesharecdn.com/ss_thumbnails/cb16matsukumaja-161109043944-thumbnail.jpg?width=640&height=640&fit=bounds)

















