4
最近の研究
FPGAによる津波シミュレーション -- GPUを超える高性能計算の手法24 Aug, 2016
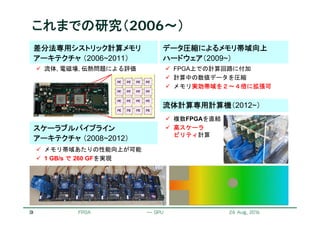
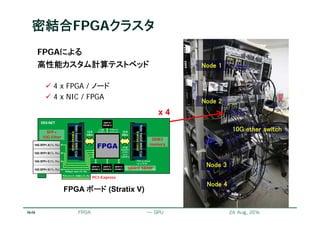
密結合FPGAクラスタ
FPGA & 専用ネットワーク
高性能計算アプリ開発のテストベッド
ストリーム計算回路高位合成コンパイラ
DSLによる簡易記述から、高性能計算専用回路を自動生成
ドライバ・ライブラリを含む処理系
FPGAによる津波シミュレーションアクセラレータ
FPGAクラスタ、高位合成コンパイラの実証アプリ
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
DRAM
FPGA
CPU
DRAM
FPGA
CPU
DRAM
FPGA
PCI-Express (x8)
DRAM
FPGA
DRAM
FPGA
CPU
CPU
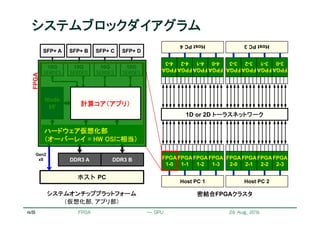
Intra-node network
Computing node w/ FPGA boards
Inter-FPGA network
(Accelerator-domain
network, ADN)
General-purpose network
本日のテーマ
46
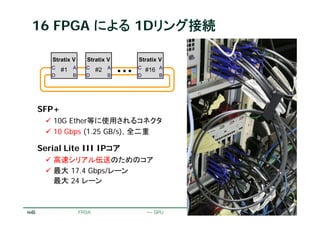
16 FPGA による1Dリング接続
SFP+
10G Ether等に使用されるコネクタ
10 Gbps (1.25 GB/s), 全二重
Serial Lite III IPコア
高速シリアル伝送のためのコア
最大 17.4 Gbps/レーン
最大 24 レーン
FPGAによる津波シミュレーション -- GPUを超える高性能計算の手法 24 Aug, 2016
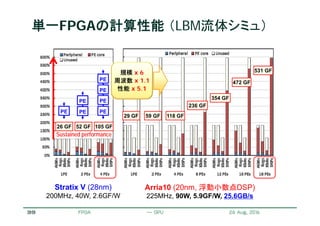
Stratix V
#1 A
B
C
D
Stratix V
#2 A
B
C
D
Stratix V
#16 A
B
C
D









![12
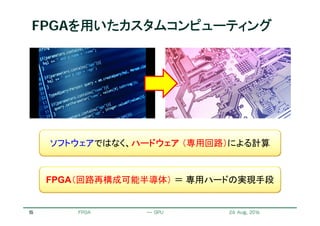
並列性とハードウェア構造
並列性を活かすことのできる構造が必要
FPGAによる津波シミュレーション -- GPUを超える高性能計算の手法 24 Aug, 2016
for (i=1; i < 100; i++) {
z[i] = (a*x[i] + b*y[i])/z[i-1];
}
*
+
/
*
a x[i] b y[i]
z[i]
z[i-1]
*
+
/
*
a x[i+1] b y[i+1]
z[i+1]
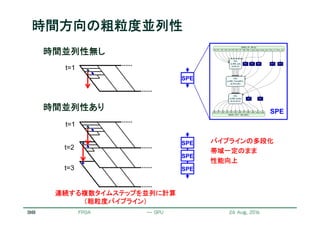
サイクル
ソフトウェアパイプライニングの例
並列性や依存関係に即した
演算器やその接続があれば、
高い稼働率を実現可
z[i-1]
*
+
/
*
a x[i] b y[i]
z[i]
*
+
/
*
a x[i+1] b y[i+1]
z[i+1]](https://image.slidesharecdn.com/ksano8thfpgax0824forslideshare-160831135252/85/FPGA-GPU-12-320.jpg)





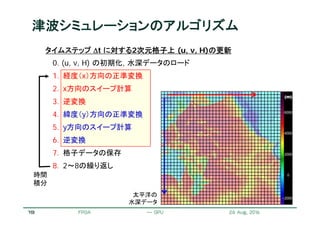

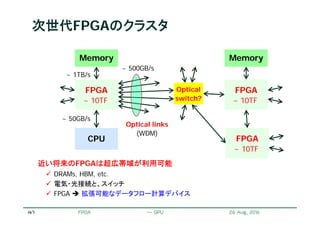
![21
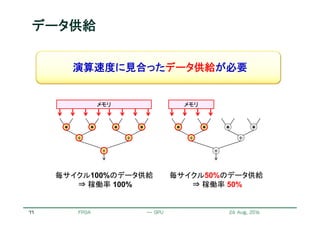
各ステップ : 反復ステンシル計算
i -1 i+1i
j
j +1
j -1
局所的な格子点(ステンシル)の参照と計算
スィープしながら全格子を計算
さらにそれを反復
計算格子
リコンフィギャラブルシステム研究会 May 13, 2011
ステンシル
[ i, j ]
[ i, j ]
ステンシル計算
[ i–1,j ][ i+1, j ] [ i, j–1][ i, j+1]](https://image.slidesharecdn.com/ksano8thfpgax0824forslideshare-160831135252/85/FPGA-GPU-21-320.jpg)
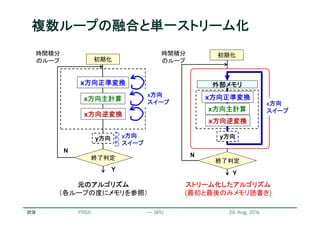
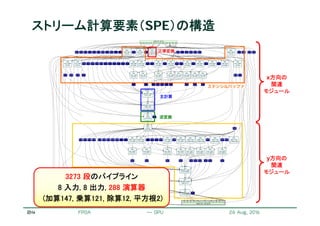
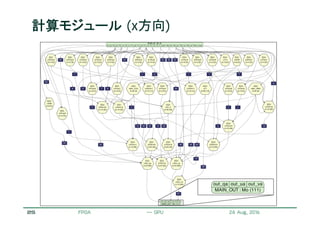
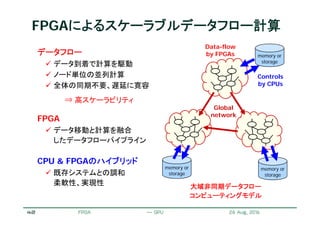
![22
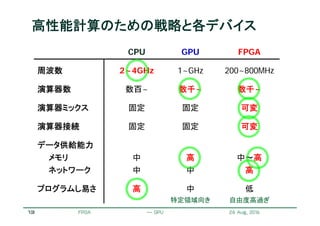
ステンシル計算のストリーム化
リコンフィギャラブルシステム研究会 May 13, 2011
ステンシル
バッファ
次の参照データ
2行分の大きさのステンシルバッファ
参照データのストリームをバッファへ格納
バッファ内のデータを用いてステンシル計算
データストリームに対するパイプライン処理が可能
[ i, j ]
ステンシル計算
計算結果の
ストリーム
[ i, j ] [ i–1,j ][ i+1, j ] [ i, j–1][ i, j+1]
[ i+1, j+1 ]
入力データ
ストリーム
[ i+2, j+1 ]](https://image.slidesharecdn.com/ksano8thfpgax0824forslideshare-160831135252/85/FPGA-GPU-22-320.jpg)

































![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)








































