Downloaded 111 times
![Pay Attention to MLPs (gMLP)
小林 範久 Present Square Co.,Ltd.
DEEPLEARNING JP
[DL Papers]
http://deeplearning.jp/
1](https://image.slidesharecdn.com/kobayashi-210528032327/85/DL-Pay-Attention-to-MLPs-gMLP-1-320.jpg)










![Appendix
24
Copyright (C) Present Square Co., Ltd. All Rights Reserved.
参考文献
• [1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia
Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, 2017.
• [2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional
transformers for language understanding. In NAACL, 2018.
• [7] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai,Thomas Unterthiner,
Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al.An image is worth 16x16 words: Transformers
for image recognition at scale. In ICLR, 2021.
• [8] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training
data-efficient image transformers & distillation through attention. arXiv preprint arXiv:2012.12877, 2020.
• [19] Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung,
Daniel Keysers, Jakob Uszkoreit, Mario Lucic, and Alexey Dosovitskiy. Mlp-mixer: An all-mlp architecture for vision.
arXiv preprint arXiv:2105.01601, 2021.
• [24] Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional
networks. In ICML, 2017.](https://image.slidesharecdn.com/kobayashi-210528032327/85/DL-Pay-Attention-to-MLPs-gMLP-24-320.jpg)

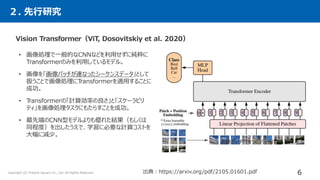
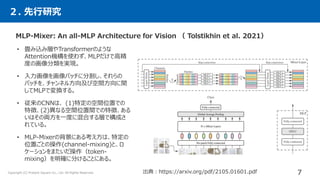
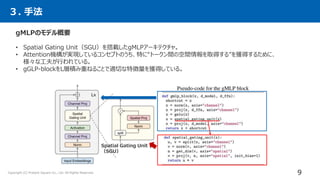
The document summarizes a research paper that compares the performance of MLP-based models to Transformer-based models on various natural language processing and computer vision tasks. The key points are: 1. Gated MLP (gMLP) architectures can achieve performance comparable to Transformers on most tasks, demonstrating that attention mechanisms may not be strictly necessary. 2. However, attention still provides benefits for some NLP tasks, as models combining gMLP and attention outperformed pure gMLP models on certain benchmarks. 3. For computer vision, gMLP achieved results close to Vision Transformers and CNNs on image classification, indicating gMLP can match their data efficiency.


![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)

































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)














