References
• Jascha Sohl-Dickstein,Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep
unsupervised learning using nonequilibrium thermodynamics. In International
Conference on Machine Learning, pp. 2256‒2265, 2015.
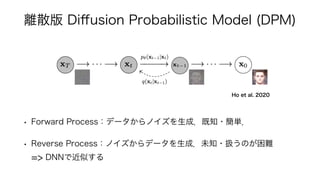
• Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising di
ff
usion probabilistic models.
Advances in Neural Information Processing Systems, 33, 2020.
• Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the
data distribution. In Advances in Neural Information Processing Systems, pp. 11895‒
11907, 2019.
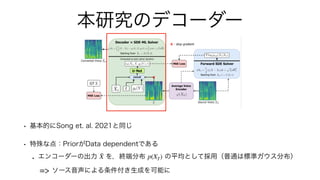
• Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon,
and Ben Poole. Score-Based Generative Modeling through Stochastic Di
ff
erential
Equations. In International Conference on Learning Representations, 2021.
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Di
ff
usion-based Voice Conversion with Fast
Maximum Likelihood Sampling Scheme
発表者: 阿久澤圭 (松尾研D3)](https://image.slidesharecdn.com/20220318akuzawa-220322065615/85/DL-Diffusion-based-Voice-Conversion-with-Fast-Maximum-Likelihood-Sampling-Scheme-1-320.jpg)
![DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Di
ff
usion-based Voice Conversion with Fast
Maximum Likelihood Sampling Scheme
発表者: 阿久澤圭 (松尾研D3)](https://image.slidesharecdn.com/20220318akuzawa-220322065615/75/DL-Diffusion-based-Voice-Conversion-with-Fast-Maximum-Likelihood-Sampling-Scheme-1-2048.jpg)









![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Monaural Audio Source Separationusing Variational Autoencoders](https://cdn.slidesharecdn.com/ss_thumbnails/20190717dlmonauralaudiosourceseparationusingvariationalautoencodersver2-190719035345-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]音声言語病理学における機械学習とDNN](https://cdn.slidesharecdn.com/ss_thumbnails/200731dldetectionofvoicedisorders-200731055557-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]音声言語病理学における機械学習とDNN](https://cdn.slidesharecdn.com/ss_thumbnails/201016dltext-to-speech-201016023355-thumbnail.jpg?width=640&height=640&fit=bounds)



















