Downloaded 38 times















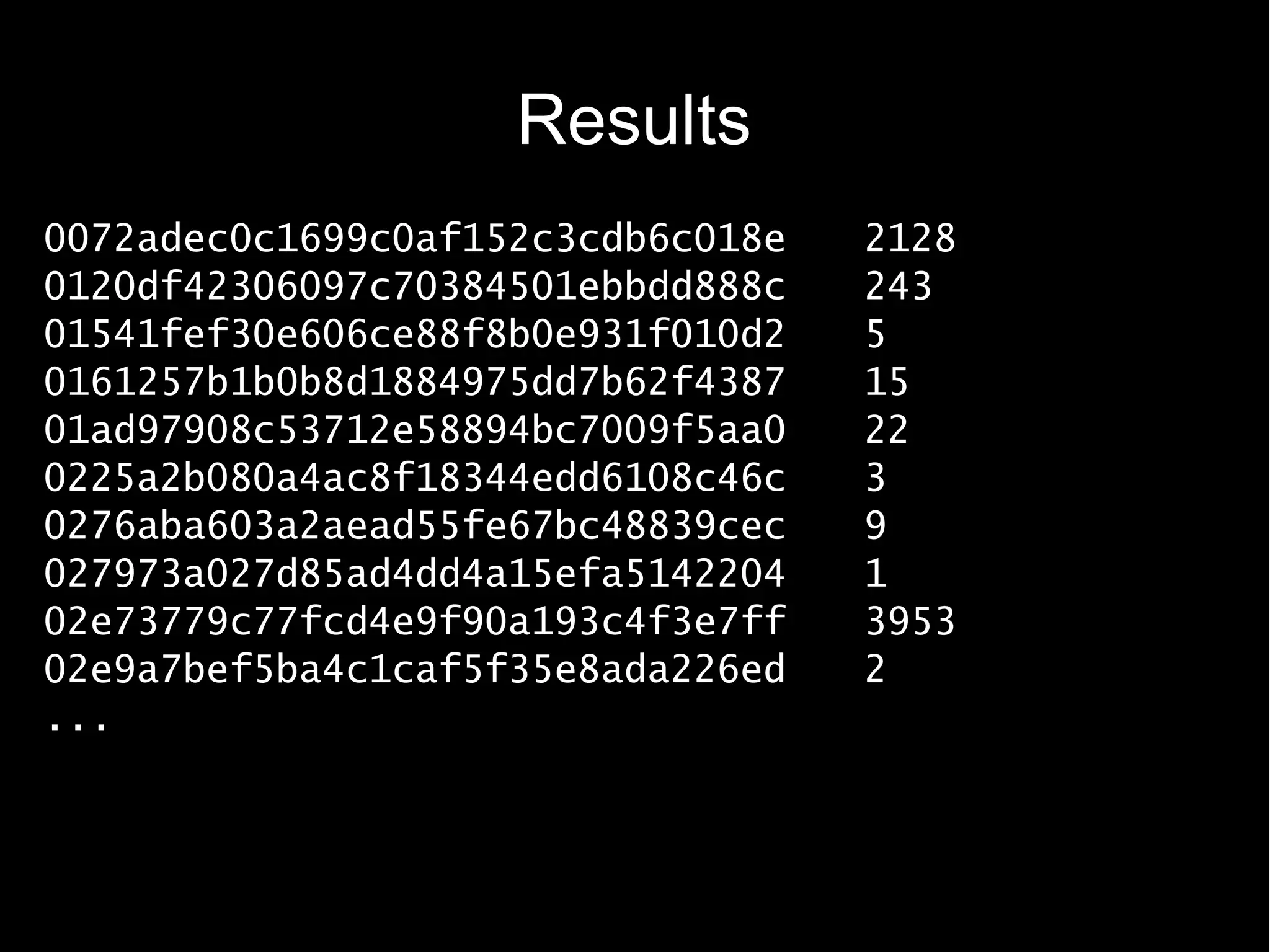
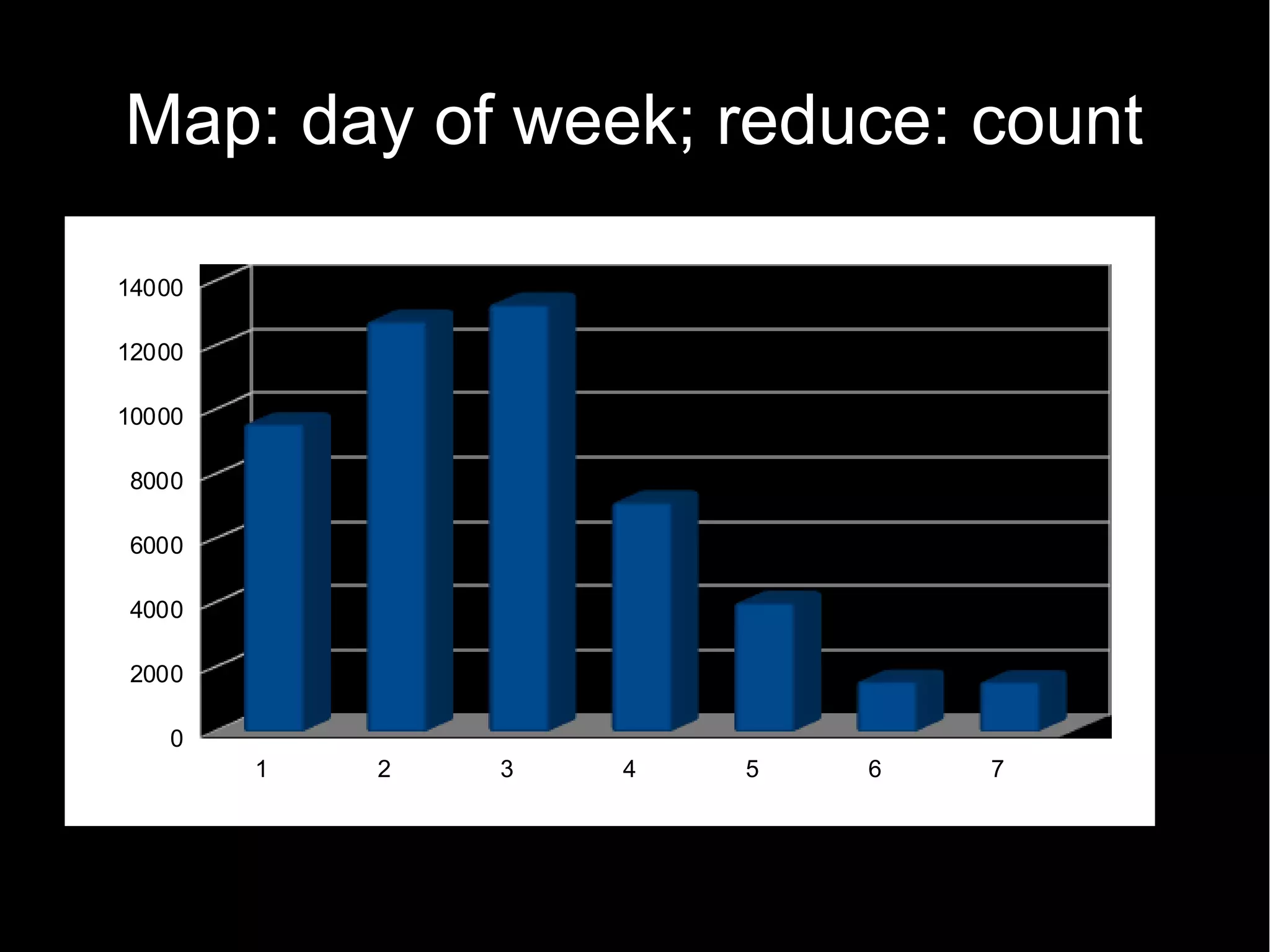
![Reduce to device count
class CountReducer2 extends Reducer {
def iw = new IntWritable()
def reduce(Text k,
Iterable values,
Reducer.Context ctx) {
def sum = values.collect() {it.get()}.sum()
iw.set(sum)
ctx.write(k, iw);
}
}
(device,[count1, count2, ...] ) → (deviceID, count')](https://image.slidesharecdn.com/myothercomputerisadatacentre-2012-120322160157-phpapp02/75/My-other-computer-is-a-datacentre-2012-edition-17-2048.jpg)


![Hardware Challenges
Energy Proportional Computing
[Barroso07]
Energy Proportional Datacenter Networks
[Abts10]
Dark Silicon and the End of Multicore Scaling
[Esmaeilzadeh10]
Scaling of CPU, storage, network](https://image.slidesharecdn.com/myothercomputerisadatacentre-2012-120322160157-phpapp02/75/My-other-computer-is-a-datacentre-2012-edition-23-2048.jpg)

![New problem: availability
Availability in Globally Distributed Storage
Systems [Ford10]
Failure Trends in a Large Disk Drive Population
[Pinheiro07]
DRAM Errors in the Wild [Schroeder09]
Characterizing Cloud Computing Hardware
Reliability [Vishwanath10]
Understanding Network Failures in Data
Centers [Gill11]](https://image.slidesharecdn.com/myothercomputerisadatacentre-2012-120322160157-phpapp02/75/My-other-computer-is-a-datacentre-2012-edition-25-2048.jpg)


The document discusses the challenges and technologies involved in managing big data in datacenters, emphasizing the importance of architecture, failure tolerance, and scalability. It outlines various distributed computing frameworks like MapReduce, Hadoop, and strategies for data replication and retrieval to ensure efficient processing. Additionally, it addresses hardware considerations, energy efficiency, and the need for algorithms that support large, unreliable clusters.





![[Webinar] Getting to Insights Faster: A Framework for Agile Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/agile-big-datav2-131122164332-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Webinar] Measure Twice, Build Once: Real-Time Predictive Analytics](https://cdn.slidesharecdn.com/ss_thumbnails/infochimpsthinkbigwebinar-130510142153-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










