













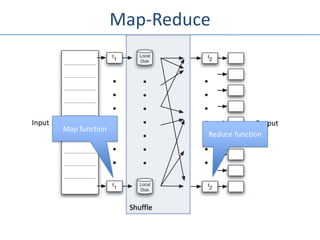

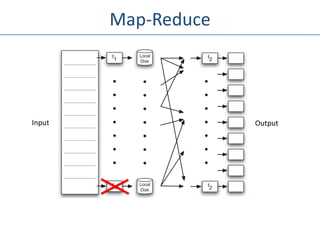
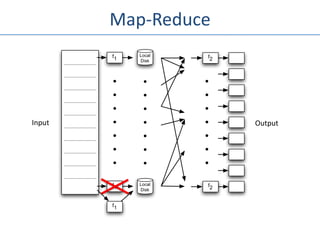
![Example – WordCount
• Mapper
– read line, tokenize into words
– emit (word, 1)
• Reducer
– read (word, [k1, … , kn])
– Emit (word, Σki)](https://image.slidesharecdn.com/seattlescalabilitymeetup-111026173519-phpapp02/85/Seattle-Scalability-Meetup-Ted-Dunning-MapR-24-320.jpg)




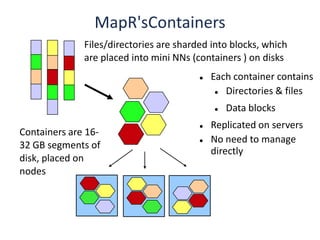
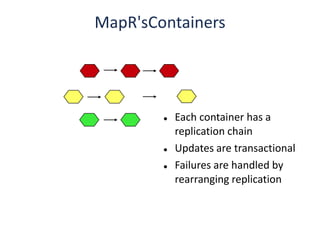
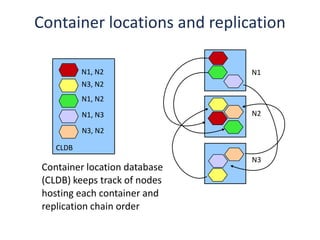

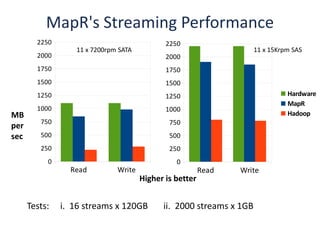
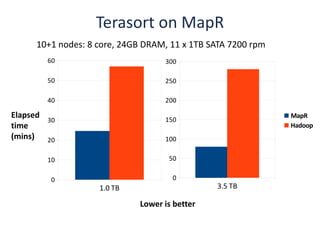
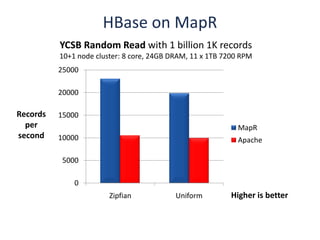
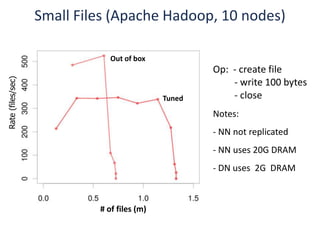
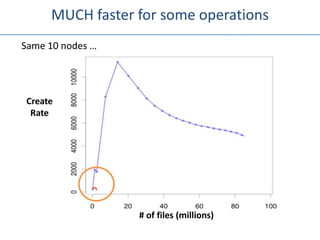


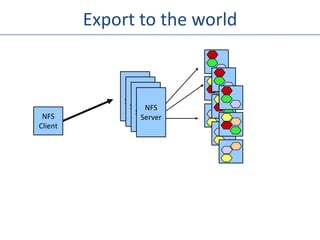
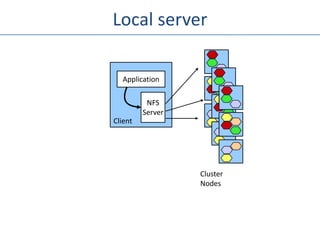
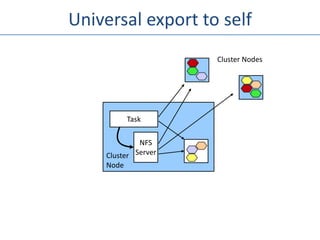
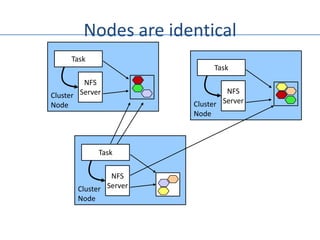

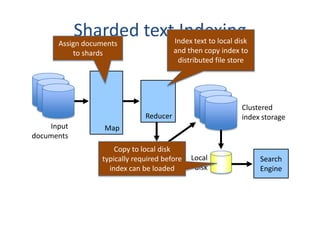

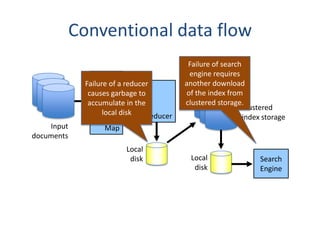
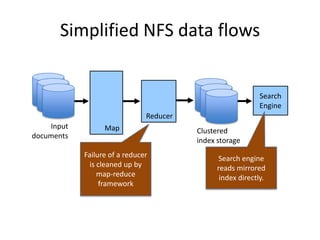
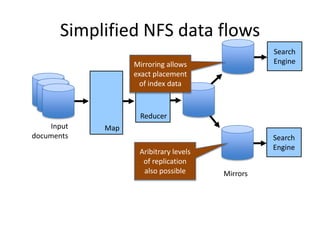


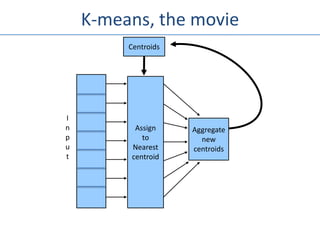

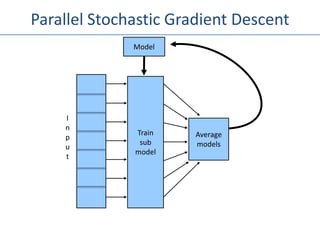
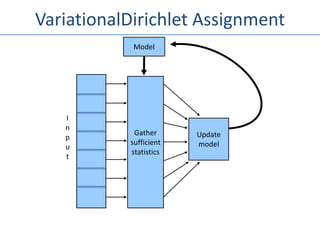
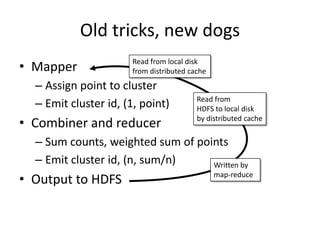
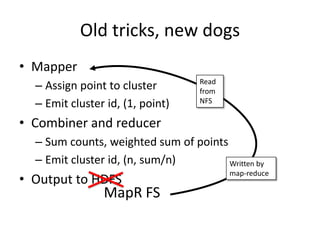

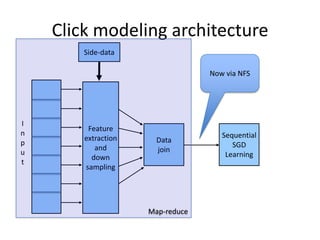
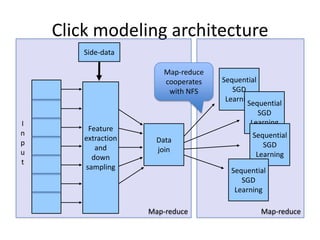

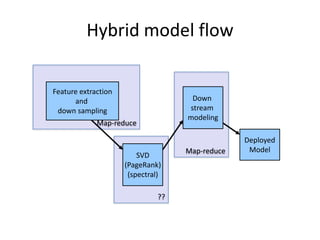
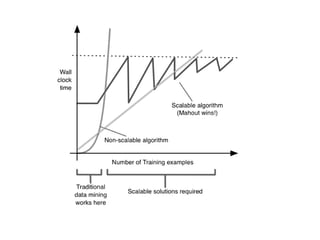
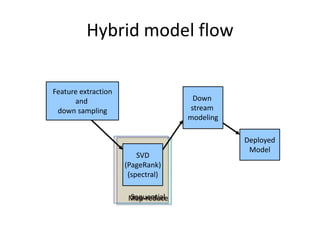




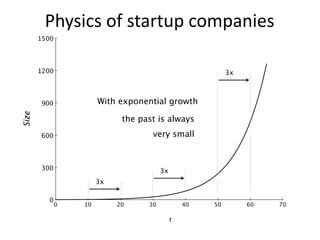
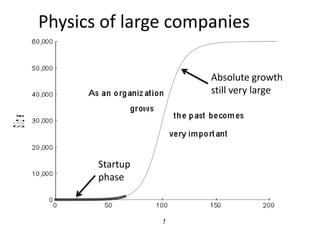
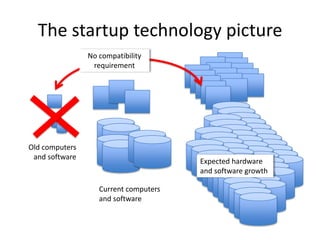
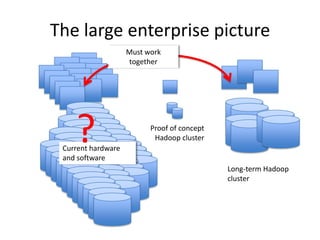
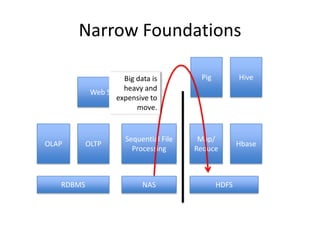
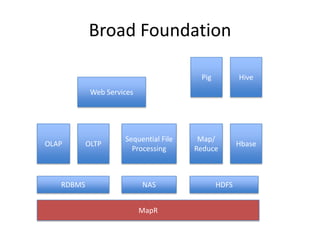
The document outlines an agenda for a Seattle Meetup focused on Hadoop and NoSQL technologies, featuring speakers and lightning talks on cloud computing and scalability. It discusses the innovations and improvements offered by MapR, a distributed filesystem that enhances performance and provides a broad foundation for big data applications. The text also touches on concepts such as MapReduce, container management, and the integration of new technologies within large enterprises.
























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








