Download to read offline










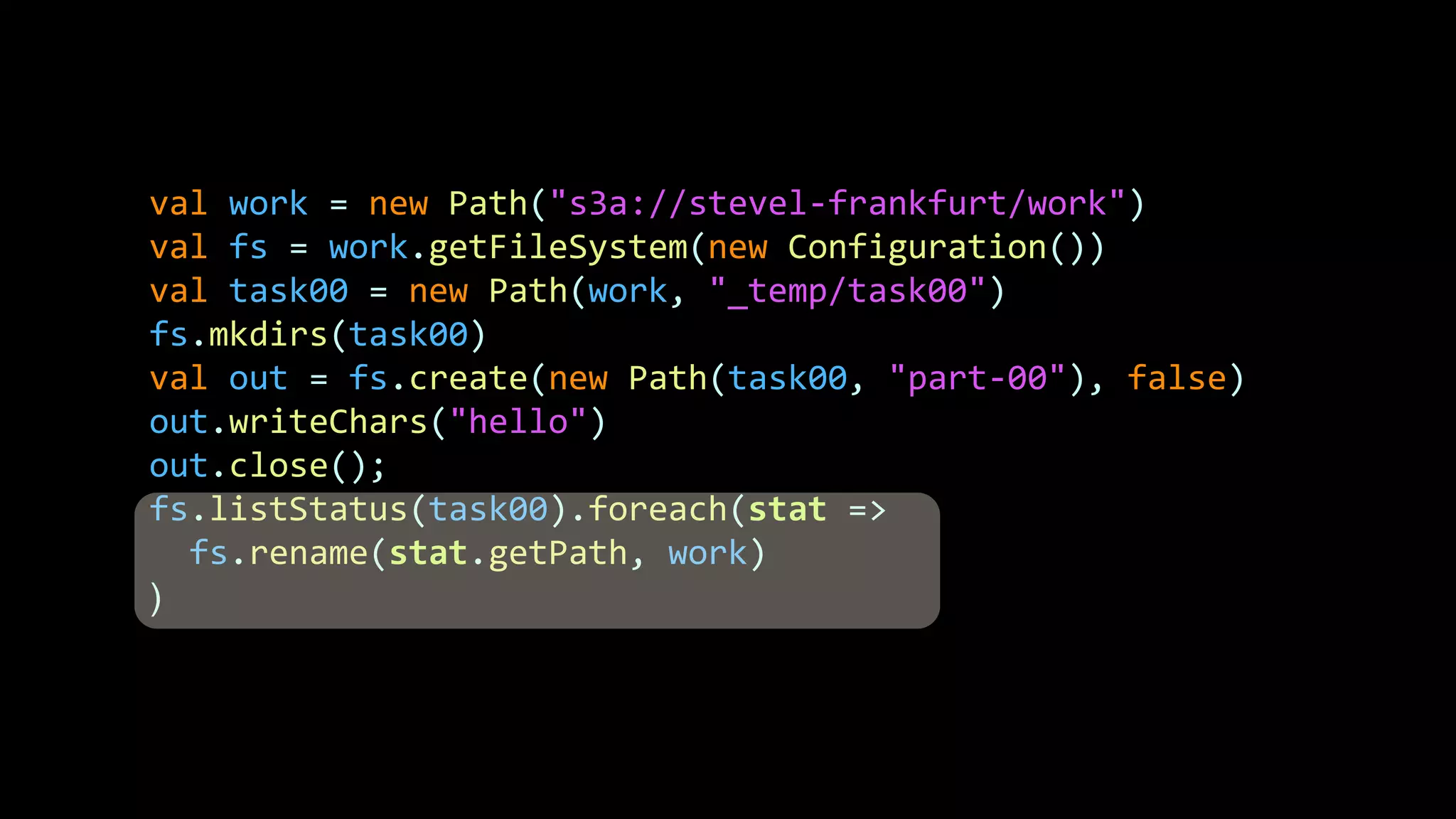
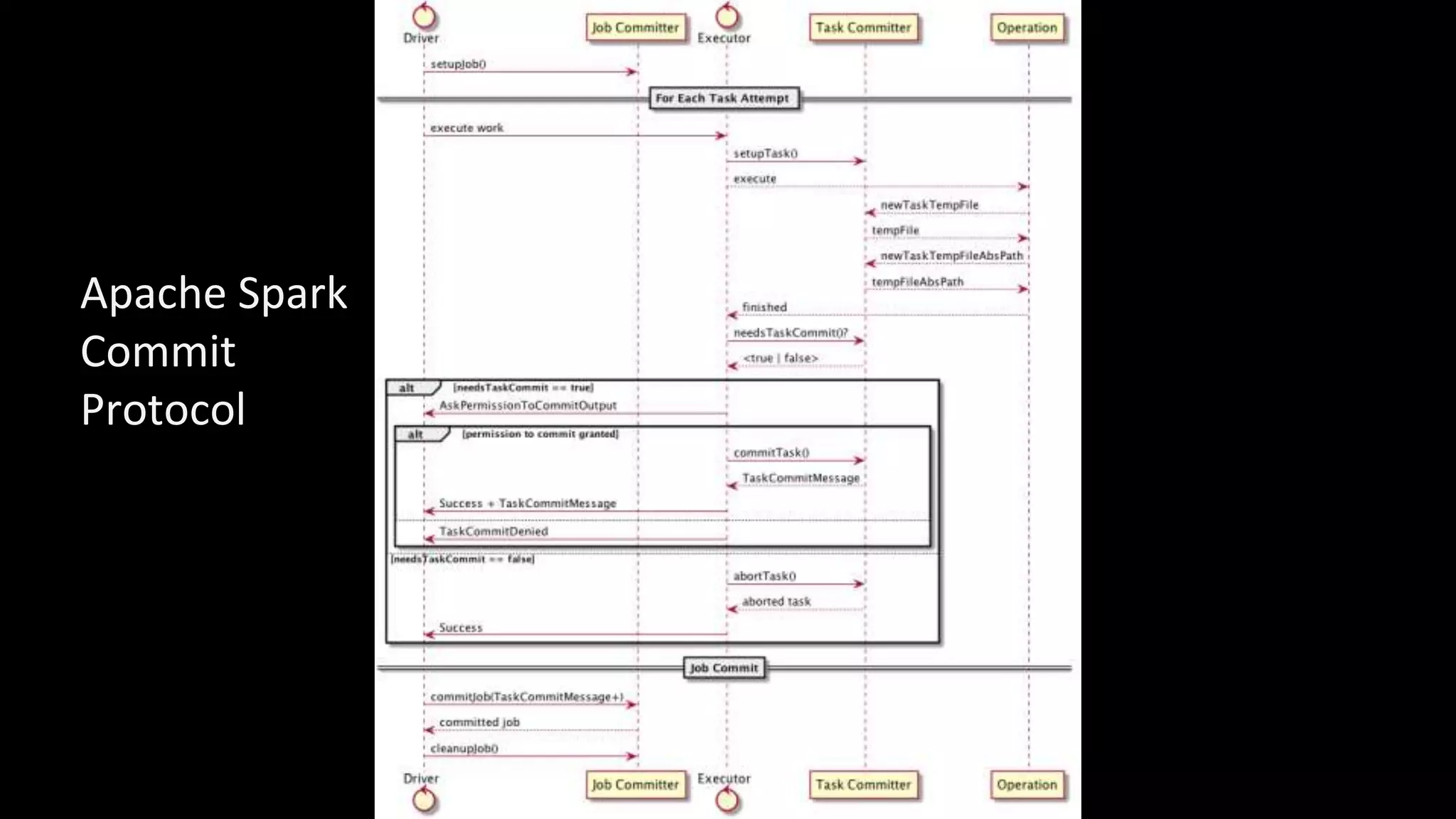
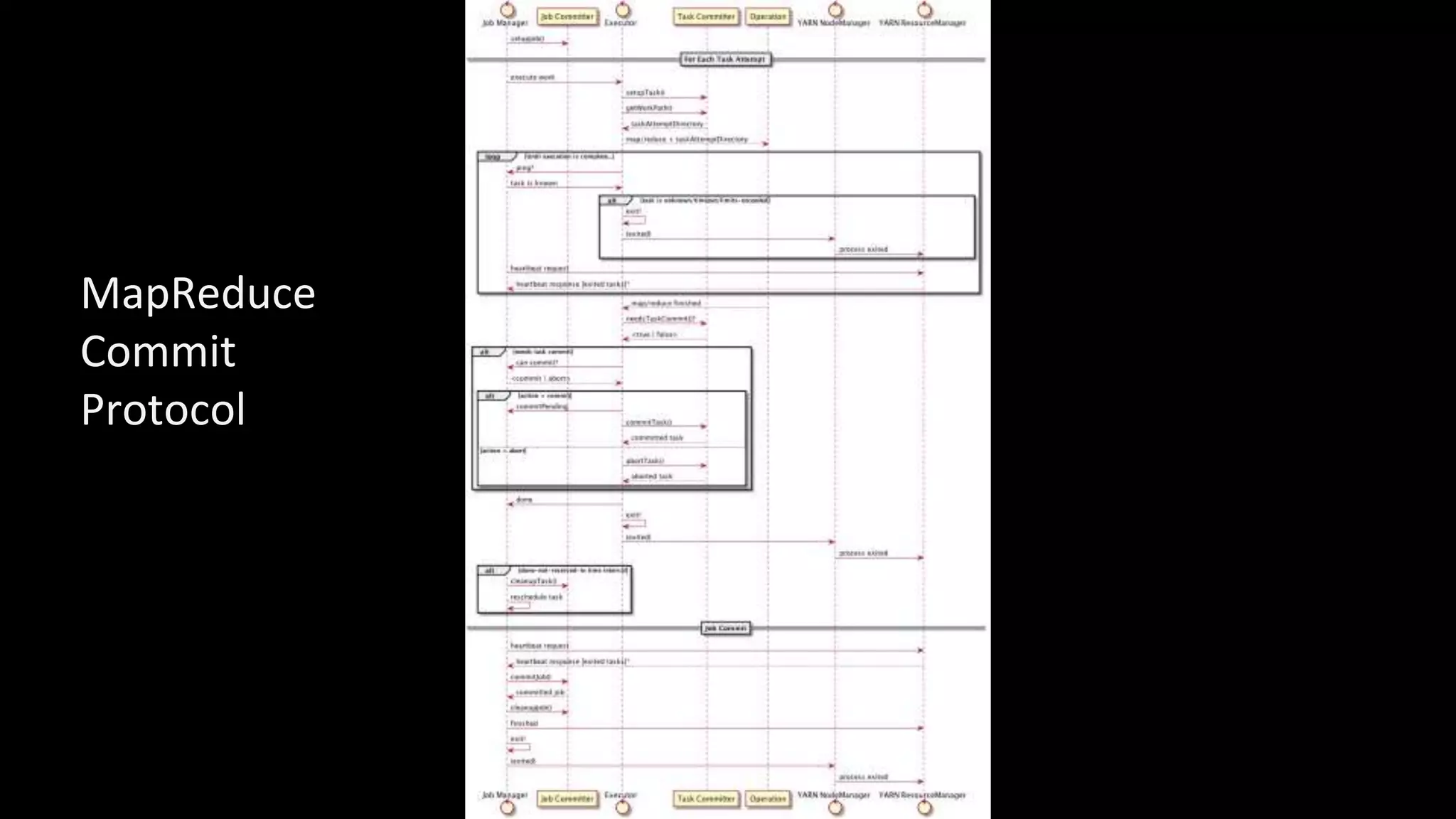
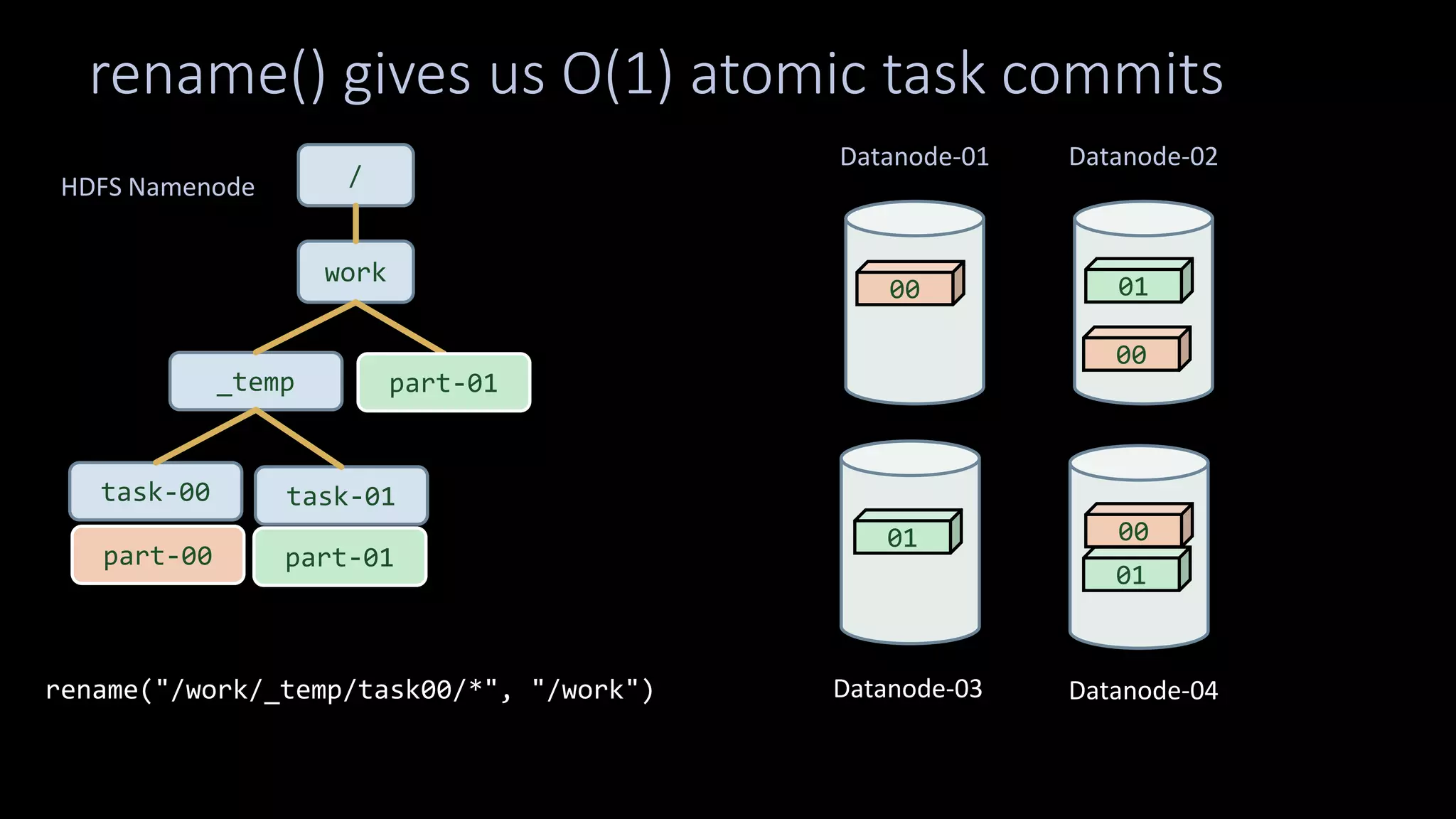
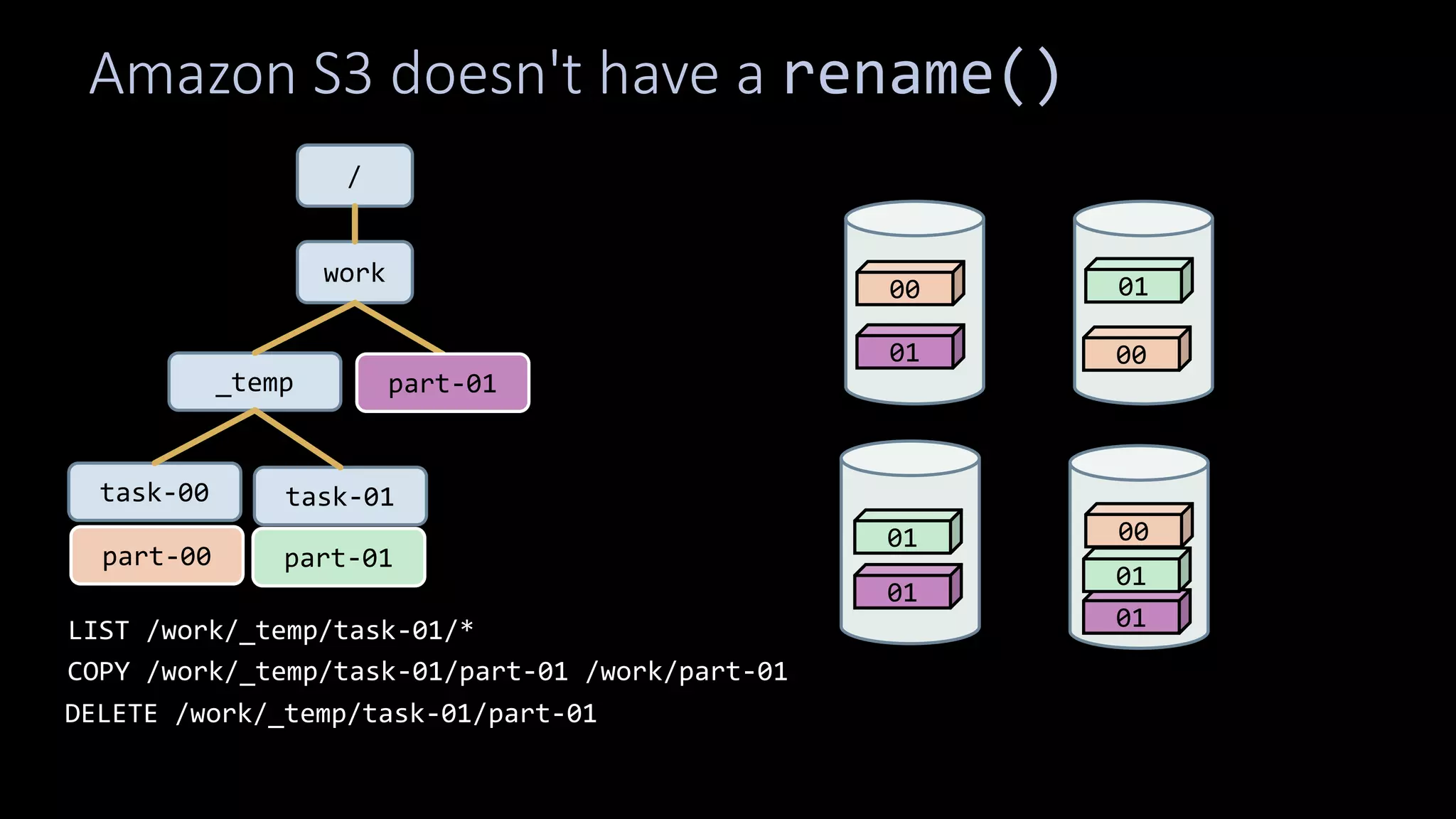





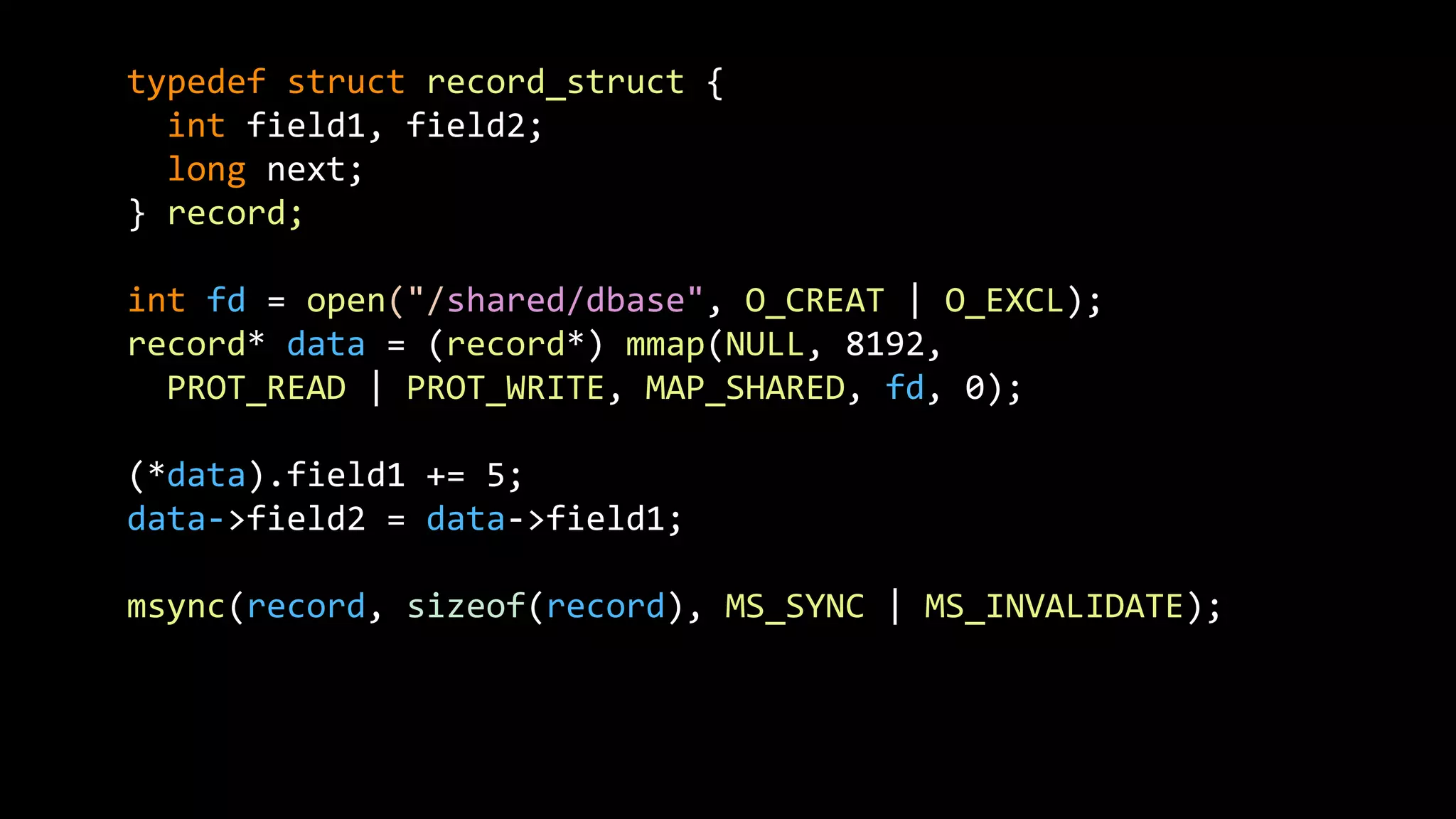
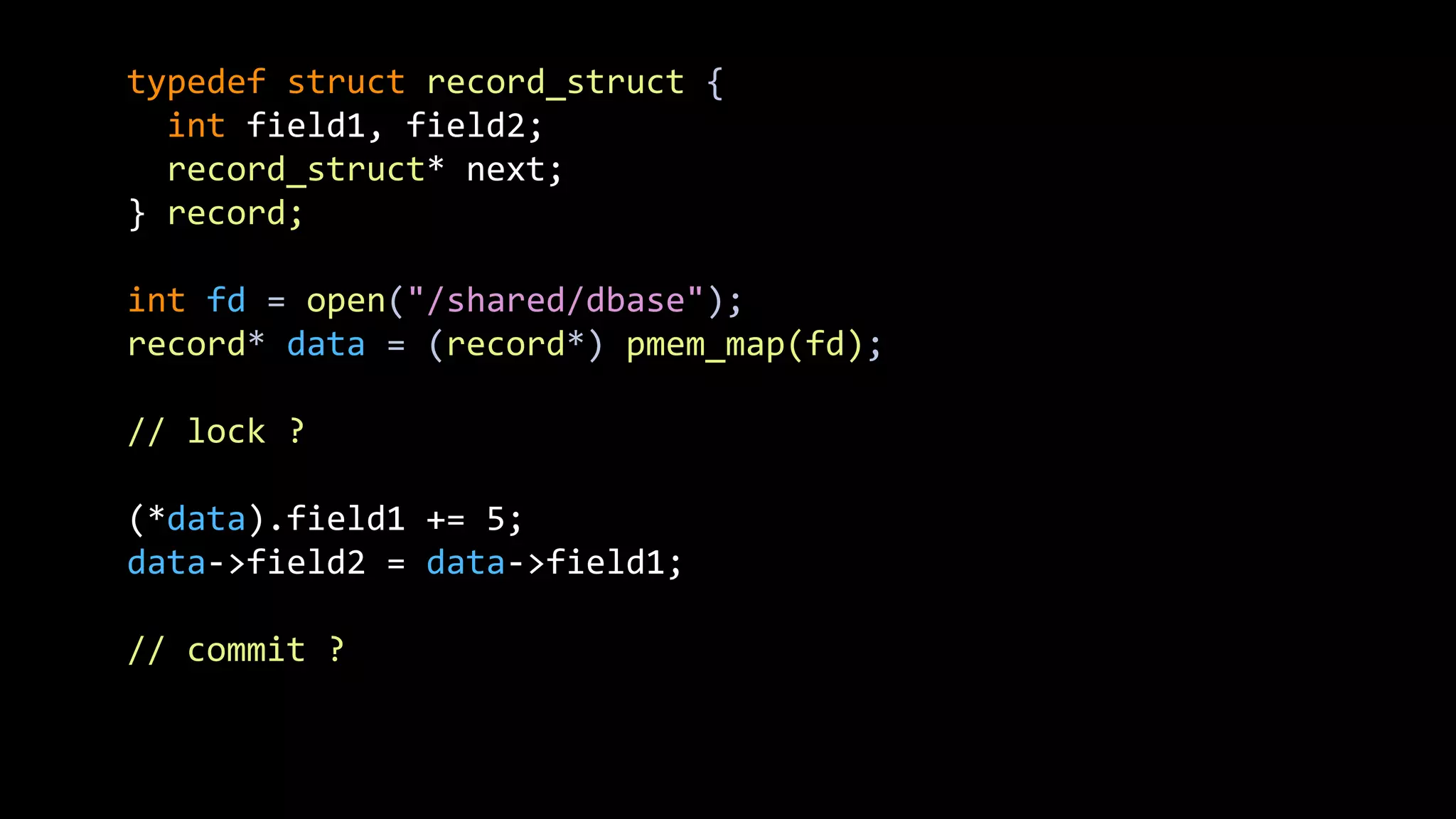







The document discusses how storage models need to evolve as the underlying technologies change. Object stores like S3 provide scale and high availability but lack semantics and performance of file systems. Non-volatile memory also challenges current models. The POSIX file system metaphor is ill-suited for object stores and NVM. SQL provides an alternative that abstracts away the underlying complexities, leaving just object-relational mapping and transaction isolation to address. The document examines renaming operations, asynchronous I/O, and persistent in-memory data structures as examples of areas where new models may be needed.










![[db tech showcase Tokyo 2017] C23: Lessons from SQLite4 by SQLite.org - Richa...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-sqlite4-20170906-170911071410-thumbnail.jpg?width=640&height=640&fit=bounds)












































































