Downloaded 11 times














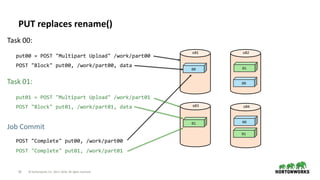

![20 © Hortonworks Inc. 2011–2018. All rights reserved
S3A Committer writing ORC and Parquet to S3A
val orcDataS3 = new Path(ireland, "orcData")
orcWasbDataframe.write.
partitionBy("year", "month").
mode(SaveMode.Append).orc(orcDataS3.toString)
val orcS3DF = spark.read.orc(orcData.toString).as[LandsatImage]
val parquetS3 = new Path(ireland, "parquetData")
orcDF.write.
partitionBy("year", "month").
mode(SaveMode.Append).parquet(parquetData.toString)
cat(new Path(parquetData, "_SUCCESS"))](https://image.slidesharecdn.com/2018-04-15-put-is-the-new-rename-berlin-180424120901/85/PUT-is-the-new-rename-20-320.jpg)
![22 © Hortonworks Inc. 2011–2018. All rights reserved
CSV: less a format, more a mess
Commas vs tabs? Mixed?
Single/double/no quotes. Escaping?
Encoding?
Schema? At best: header
missing columns?
NULL?
Numbers?
Date and time?
Compression?
CSV injection attacks (cells with = as first char) [Excel, google docs]](https://image.slidesharecdn.com/2018-04-15-put-is-the-new-rename-berlin-180424120901/85/PUT-is-the-new-rename-22-320.jpg)










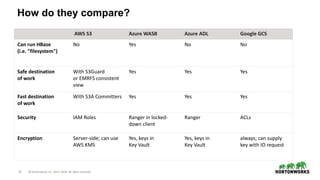




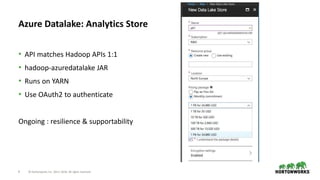
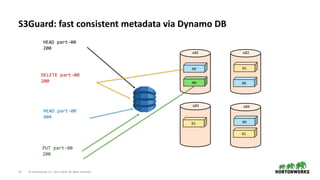
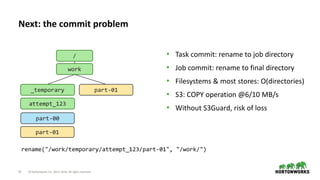
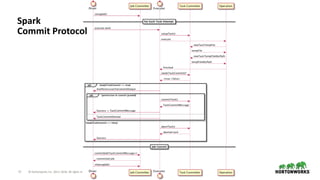
The document discusses the significance of cloud storage for analytic applications, detailing various object storage solutions such as Azure WASB, Azure Data Lake, and Amazon S3. It highlights features like S3Guard for metadata consistency, the challenges of using CSV files, and introduces S3 Select for issuing SQL queries directly on S3 data. The document concludes that while all cloud infrastructures offer object stores, AWS S3 is the least suited as a destination, despite available solutions.























































































