

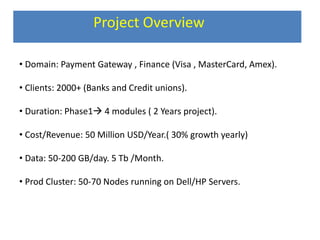
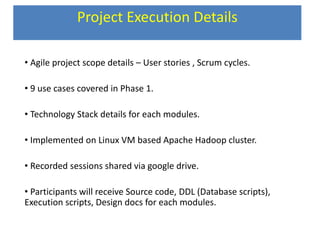






This document provides an overview of a Hadoop-based project focused on payment gateway data analytics involving 2000+ clients and a budget of 50 million USD annually, including growth details and data handling specifications. It outlines key phases including data transformation, migration to Hadoop, analytics execution using Hive, and visualization practices, detailing technology stacks and project management methodologies such as Agile. Furthermore, it includes hardware requirements, deployment strategies, and best practices learned throughout the project's lifecycle.

























![[Webinar] Getting to Insights Faster: A Framework for Agile Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/agile-big-datav2-131122164332-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























































