Download to read offline





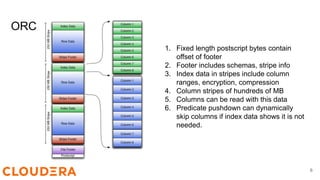





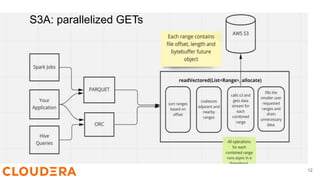




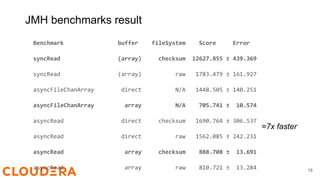
![Java Microbench Harness
Native IO implementation of vectored IO API in RawLocal and Checksum
filesystem +
JMH benchmark to compare the performance across
● FS: [Raw, Checksum file system].
● Buffers: [Direct, Heap]
● read: [seek() + read(), Vectored, java async file channel read]
see: org.apache.hadoop.benchmark.VectoredReadBenchmark
17](https://image.slidesharecdn.com/2023-06-hadoopvectoredio-231120093358-e1855a66/85/Hadoop-Vectored-IO-17-320.jpg)

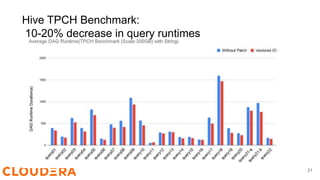
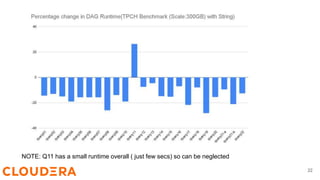
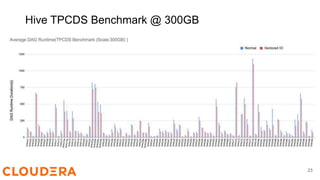
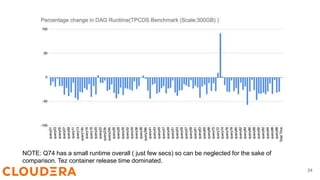

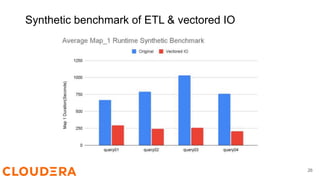















Steve Loughran discusses the benefits of Hadoop's vectored I/O, which significantly speeds up data retrieval from cloud storage by optimizing read operations for columnar formats like ORC and Parquet. The new API allows for parallel data fetching, decreasing query runtimes in environments like S3 by up to 70%. Vectored I/O will be included in Hadoop version 3.3.5, and efforts are underway to support it in ORC and Parquet libraries.
![[ACNA2022] Hadoop Vectored IO_ your data just got faster!.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/acna2022hadoopvectoredioyourdatajustgotfaster-221013195632-d6eeb468-thumbnail.jpg?width=640&height=640&fit=bounds)

































































