Download to read offline



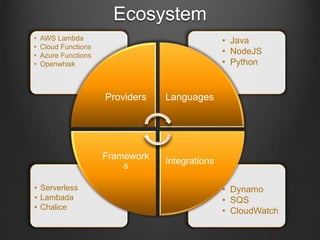

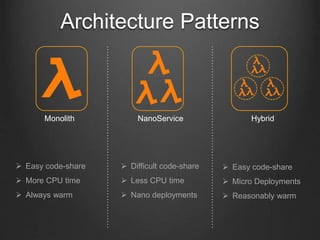
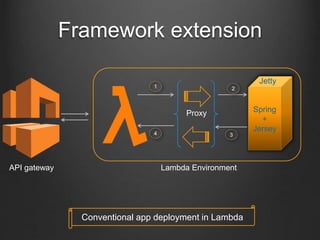

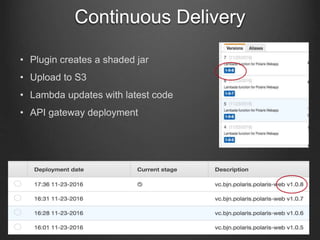



The document discusses the Lambda architecture in the context of functional programming and cloud computing. It covers various aspects such as event-driven design, cloud service providers, and deployment strategies, highlighting the benefits and limitations of using serverless functions. Key components include AWS Lambda, Azure Functions, and deployment requirements related to maximum response times and payload sizes.












































































