Downloaded 692 times







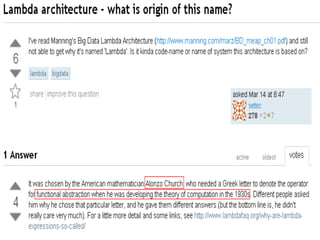
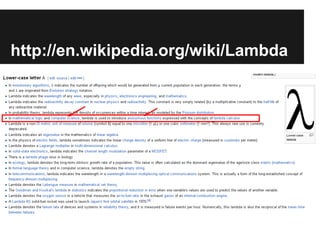

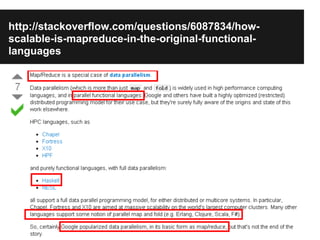


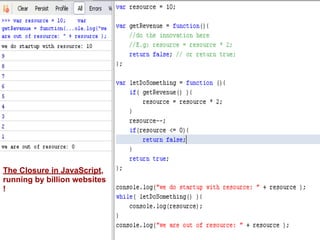
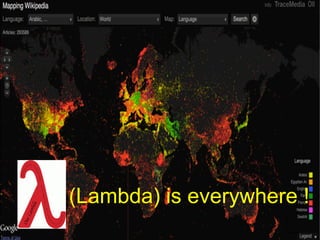


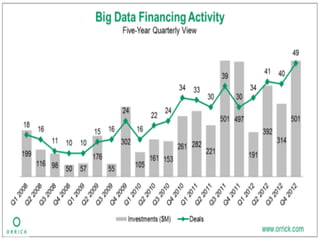


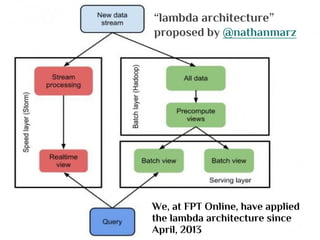


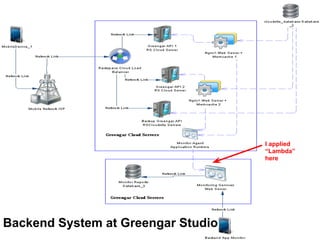
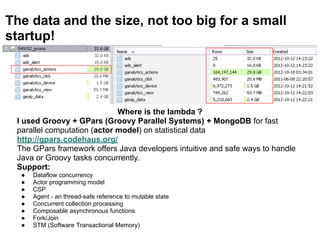
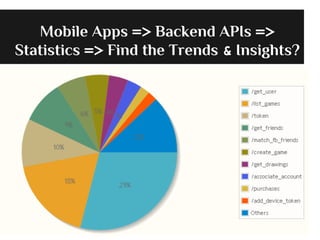





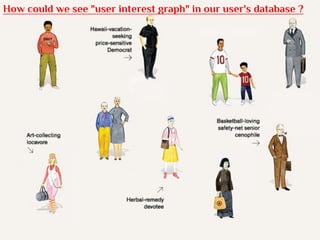
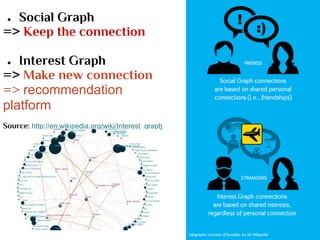






- The document discusses the Lambda Architecture, a system designed by Nathan Marz for building real-time big data applications. It is based on three principles: human fault-tolerance, data immutability, and recomputation. - The document provides two case studies of applying Lambda Architecture - at Greengar Studios for API monitoring and statistics, and at eClick for real-time data analytics on streaming user event data. - Key lessons discussed are keeping solutions simple, asking the right questions to enable deep analytics and profit, using reactive and functional approaches, and turning data into useful insights.





































![[USI] Lambda-Architecture : comment réconcilier BigData et temps-réel](https://cdn.slidesharecdn.com/ss_thumbnails/preslambdaarch-v3-slideshare-140617091602-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[Notes] Customer 360 Analytics with LEO CDP](https://cdn.slidesharecdn.com/ss_thumbnails/notescustomer360analyticswithleocdp-220126053232-thumbnail.jpg?width=640&height=640&fit=bounds)


































