Downloaded 200 times










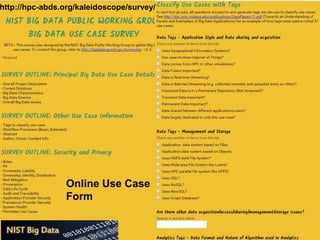








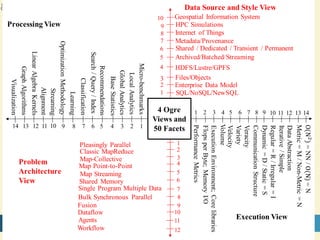


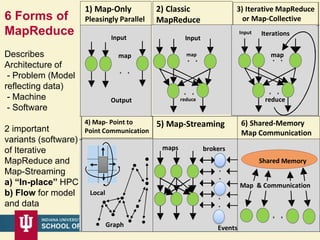











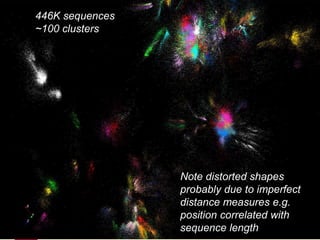
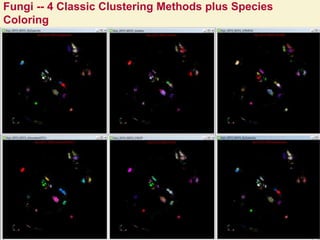
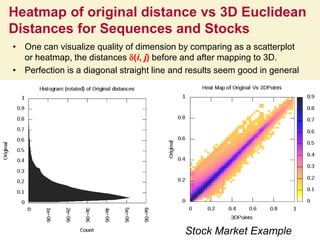

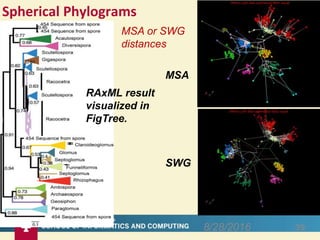
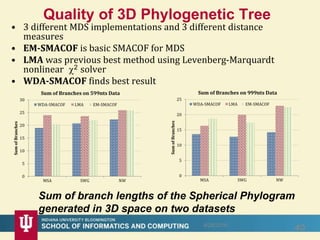
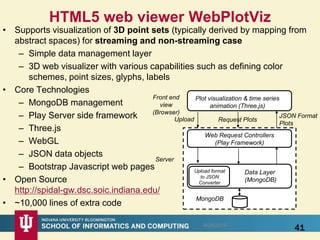

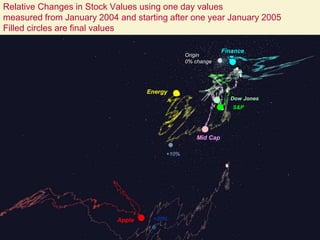
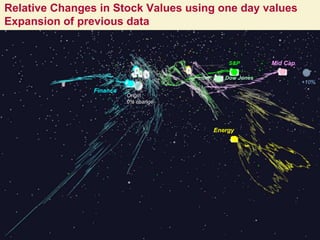

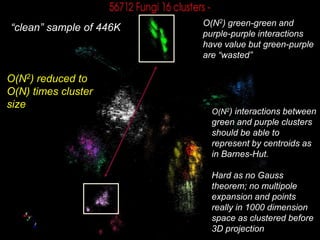





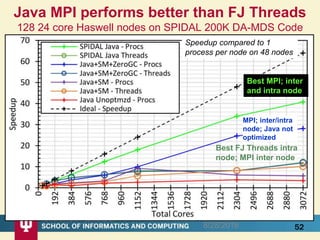
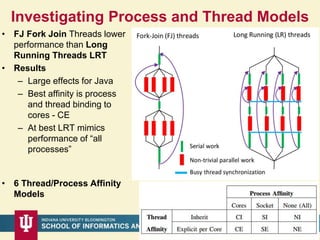
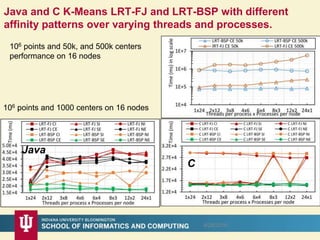
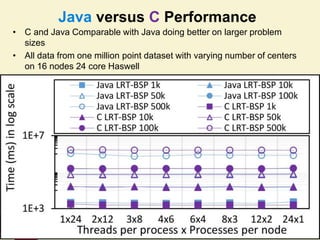
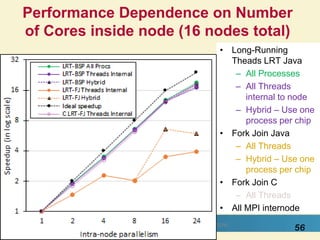


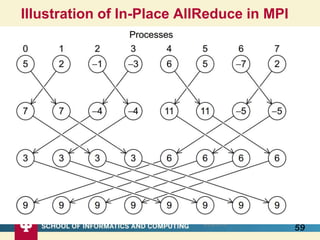
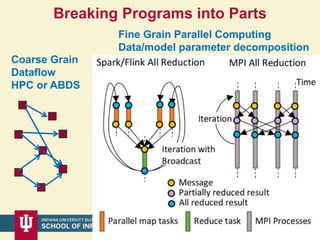
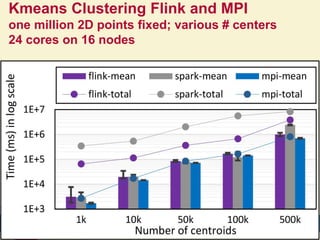



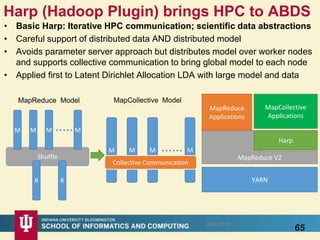
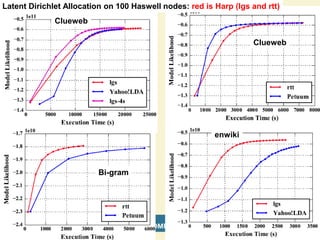
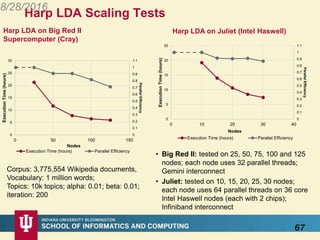


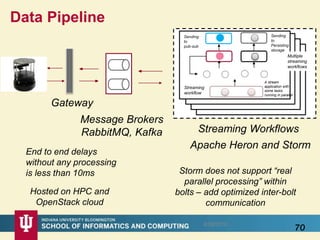
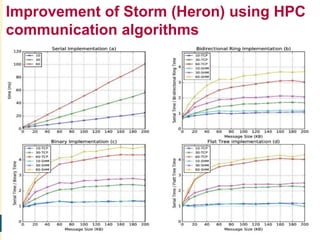






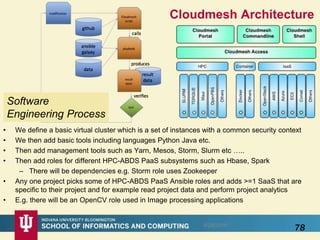




This document proposes a hybrid software stack that combines large-scale data systems from both research and commercial applications. It runs the commodity Apache Big Data Stack (ABDS) using enhancements from High Performance Computing (HPC) to improve performance. Examples are given from bioinformatics and financial informatics. Parallel and distributed runtimes like MPI, Storm, Heron, Spark and Flink are discussed, distinguishing between parallel (tightly-coupled) and distributed (loosely-coupled) systems. The document also discusses optimizing Java performance and differences between capacity and capability computing. Finally, it explains how this HPC-ABDS concept allows convergence of big data, big simulation, cloud and HPC systems.






































































































