Downloaded 19 times



![© Hortonworks Inc. 2011 – 2017 All Rights Reserved
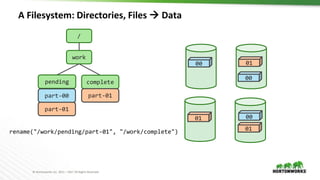
Object Store: hash(name)⇒data
00
00
00
01
01
s01 s02
s03 s04
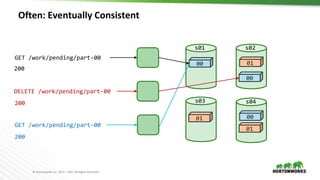
hash("/work/pending/part-01")
["s02", "s03", "s04"]
copy("/work/pending/part-01",
"/work/complete/part01")
01
01
01
01
delete("/work/pending/part-01")
hash("/work/pending/part-00")
["s01", "s02", "s04"]](https://image.slidesharecdn.com/2017-04-04-dancingelephantsfinal-170405211257/85/Dancing-Elephants-Working-with-Object-Storage-in-Apache-Spark-and-Hive-10-320.jpg)


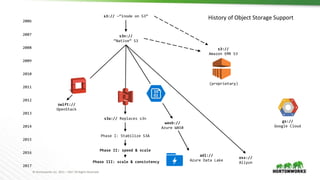


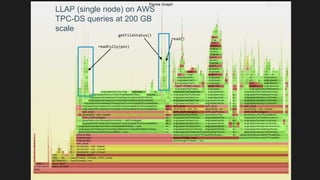


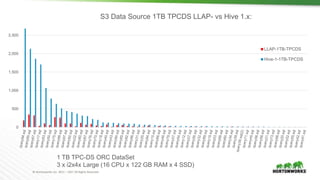




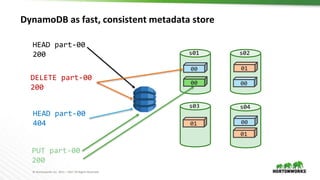





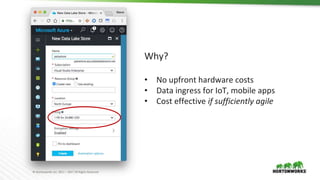
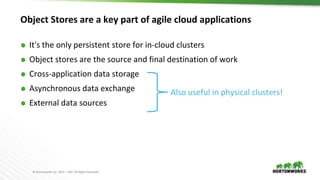
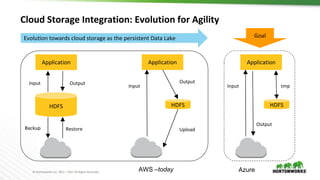
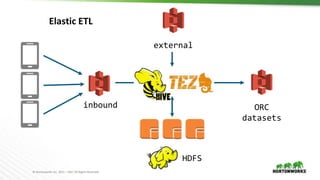
The document discusses the integration of object storage with Apache Spark and Hive, emphasizing its significance for agile cloud applications and data management. It highlights the evolution of cloud storage, the challenges posed by eventual consistency, and performance issues related to S3. Additionally, it addresses the improvements in Hadoop's performance on Azure and the implementation of various optimizations for better handling of object storage in data processing.























































































