Download to read offline














![24 © Hortonworks Inc. 2011 – 2017 All Rights Reserved
S3A Committer writing ORC and Parquet to S3A
val orcDataS3 = new Path(ireland, "orcData")
orcWasbDataframe.write.
partitionBy("year", "month").
mode(SaveMode.Append).orc(orcDataS3.toString)
val orcS3DF = spark.read.orc(orcData.toString).as[LandsatImage]
val parquetS3 = new Path(ireland, "parquetData")
orcDF.write.
partitionBy("year", "month").
mode(SaveMode.Append).parquet(parquetData.toString)
cat(new Path(parquetData, "_SUCCESS"))](https://image.slidesharecdn.com/2018-08-21-what-does-rename-do2018-180916201725/75/What-does-Rename-Do-detailed-version-22-2048.jpg)



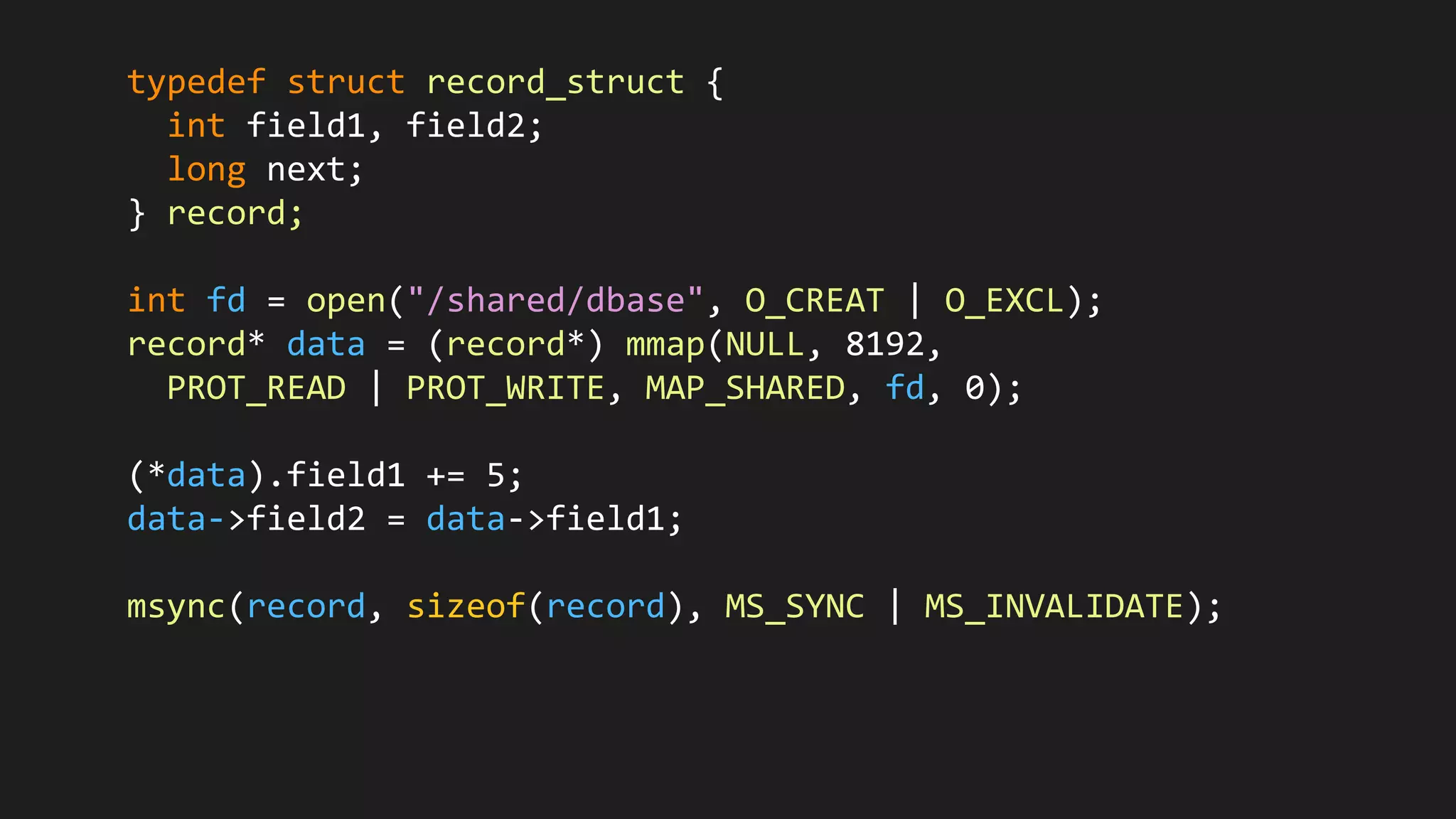

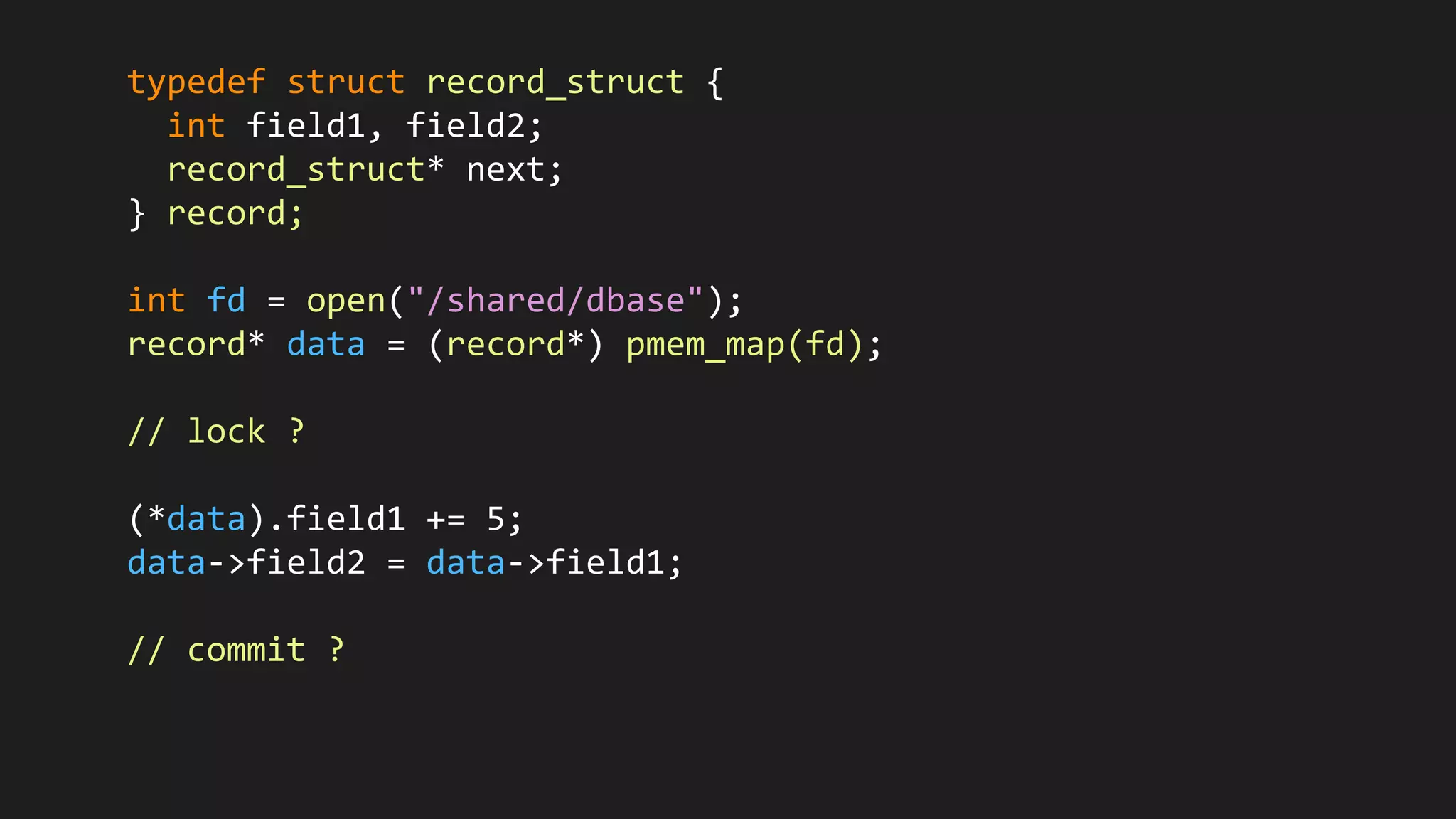




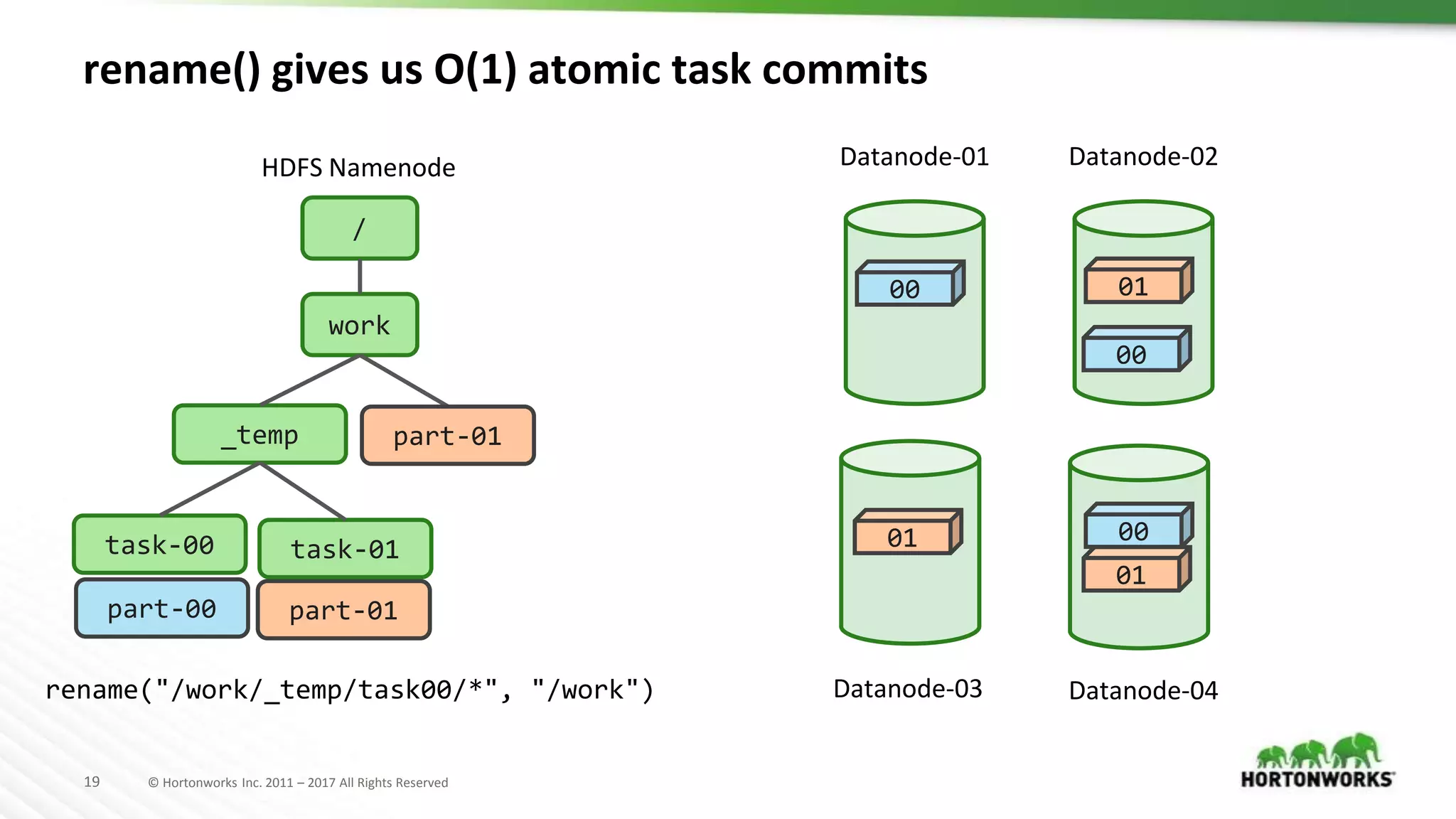
The document discusses the challenges and methodologies related to state persistence and recovery in Hadoop and cloud storage systems, particularly focusing on the `rename()` function and its implications for efficient data management. It highlights the need for a more streamlined approach to handle state in distributed environments and the potential shifts towards new data storage paradigms, including non-volatile memory. Furthermore, it raises questions about the future of file and data handling APIs in light of changing technology landscapes.












![[db tech showcase Tokyo 2017] C23: Lessons from SQLite4 by SQLite.org - Richa...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-sqlite4-20170906-170911071410-thumbnail.jpg?width=640&height=640&fit=bounds)










































































