Downloaded 94 times














![© Hortonworks Inc
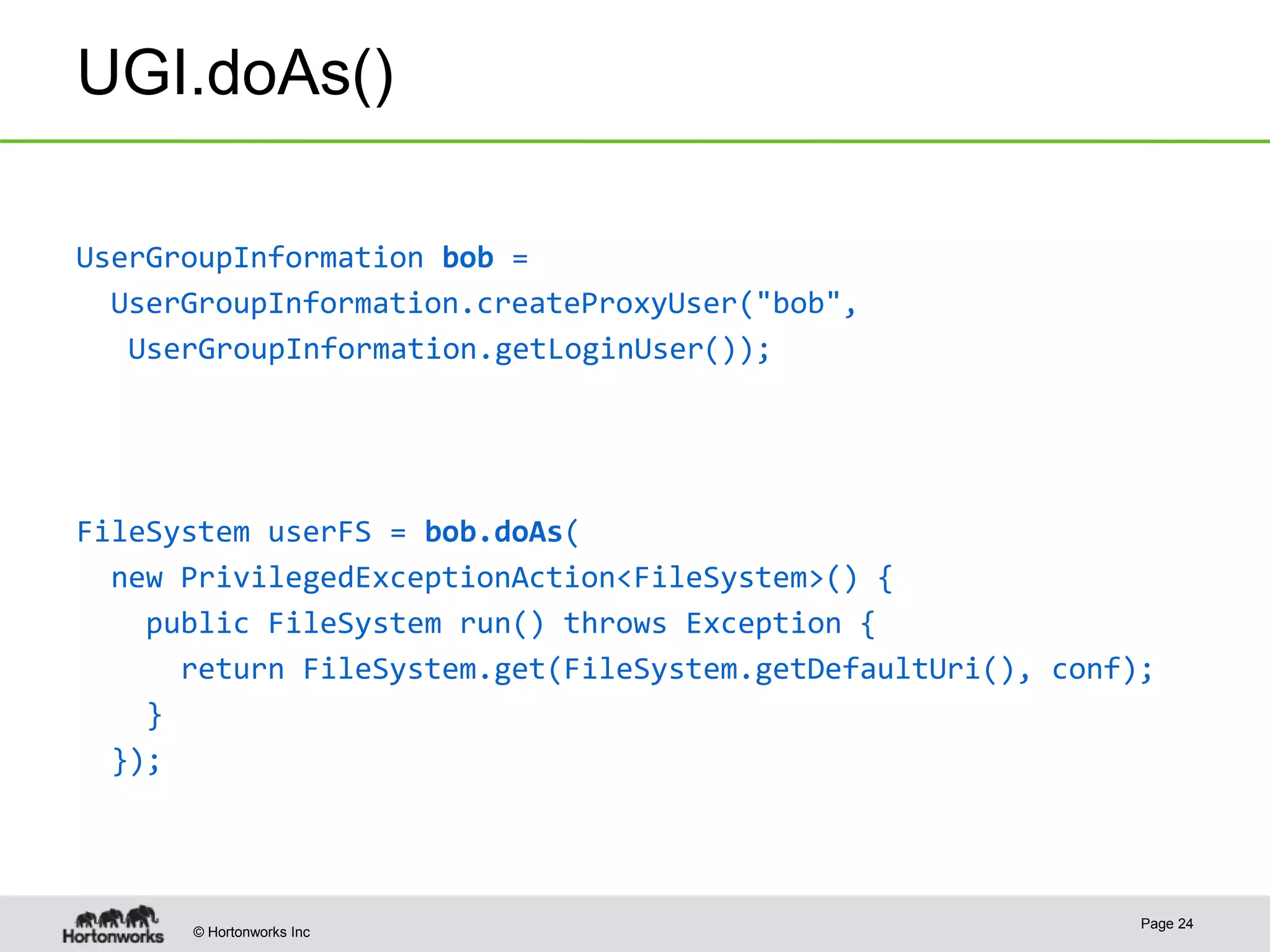
Hadoop RPC
@KerberosInfo(serverPrincipal = "my.kerberos.principal")
public interface MyRpc extends VersionedProtocol { … }
public class MyRpcPolicyProvider extends PolicyProvider {
public Service[] getServices() {
return new Service[] {
new Service("my.protocol.acl", MyRpc.class)
};
}
}
public class MyRpcSecurityInfo extends SecurityInfo { … }
META-INF/services/org.apache.hadoop.security.SecurityInfo
org.example.rpc.MyRpcSecurityInfo
Page 26](https://image.slidesharecdn.com/2016-01-22-kerberos-the-madness-160123050700/75/Hadoop-and-Kerberos-the-Madness-Beyond-the-Gate-January-2016-edition-24-2048.jpg)
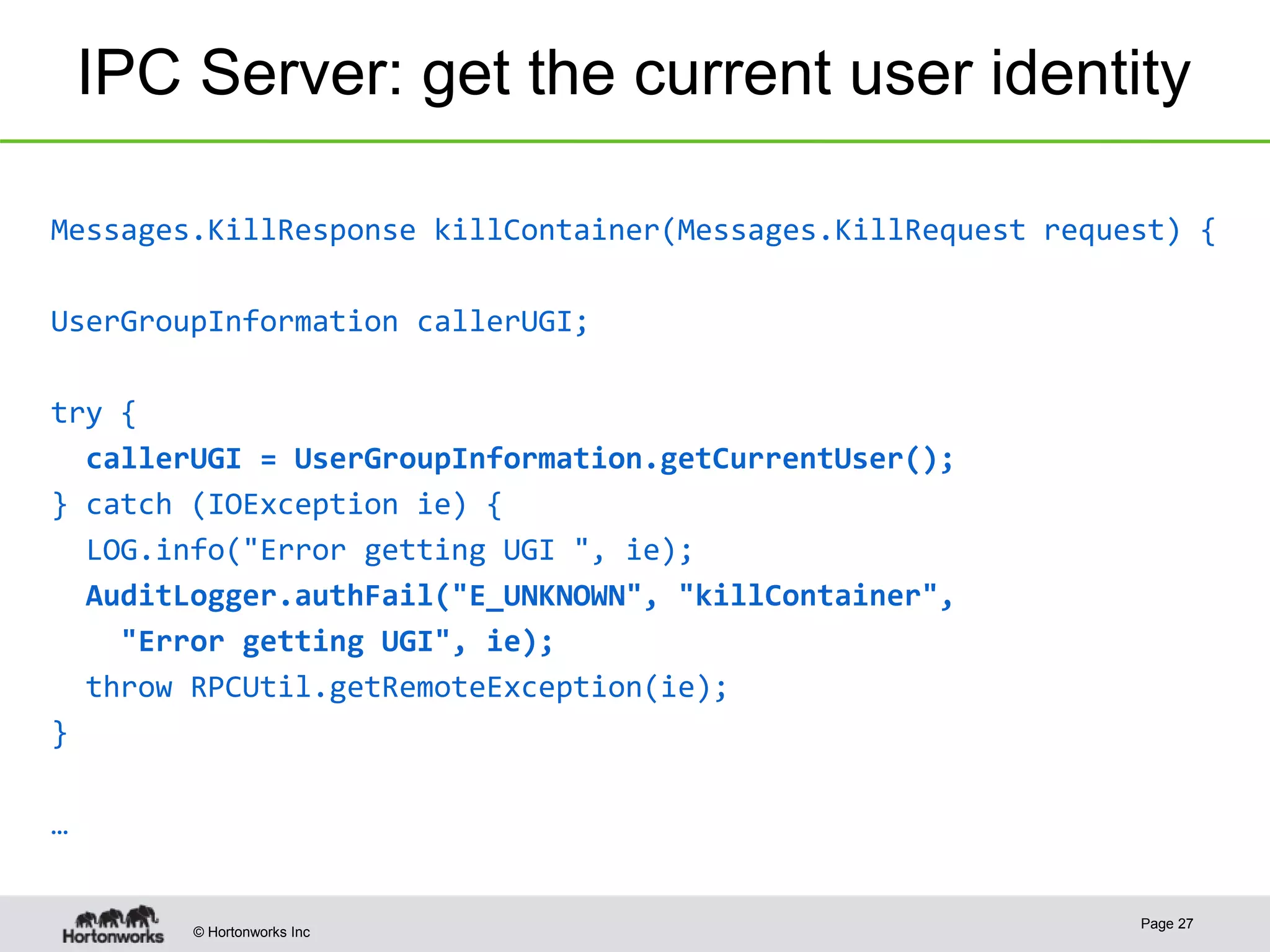
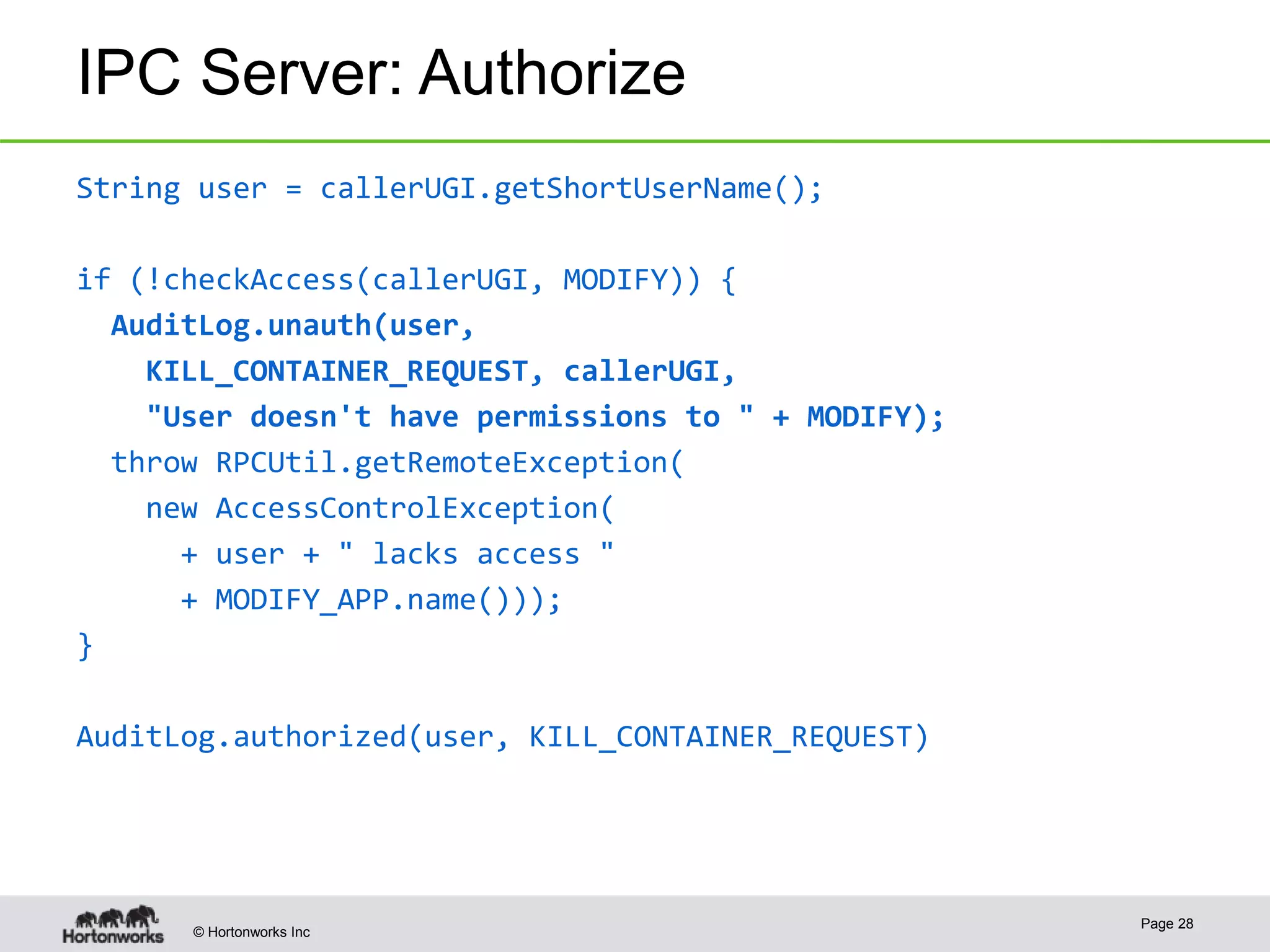


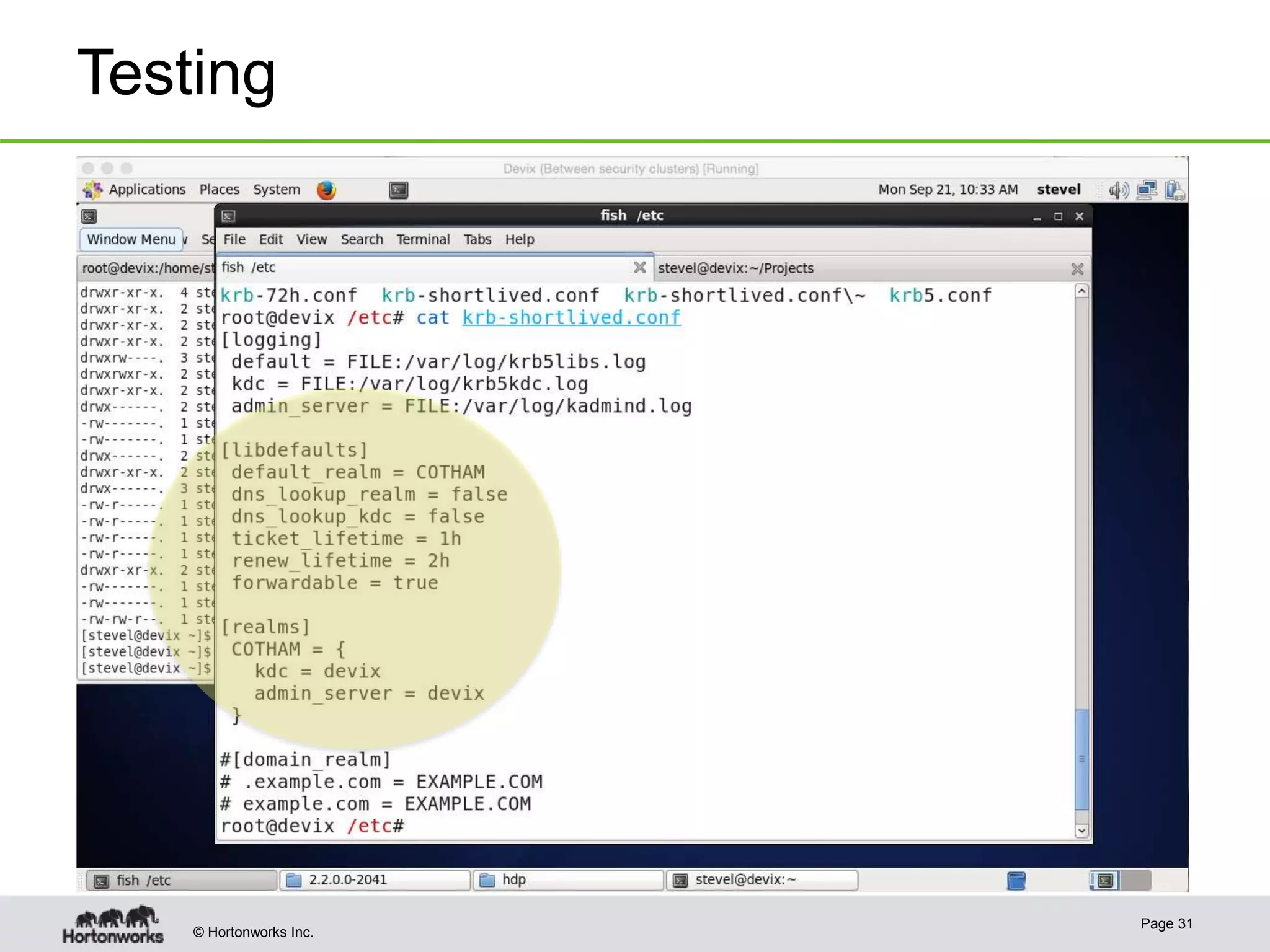









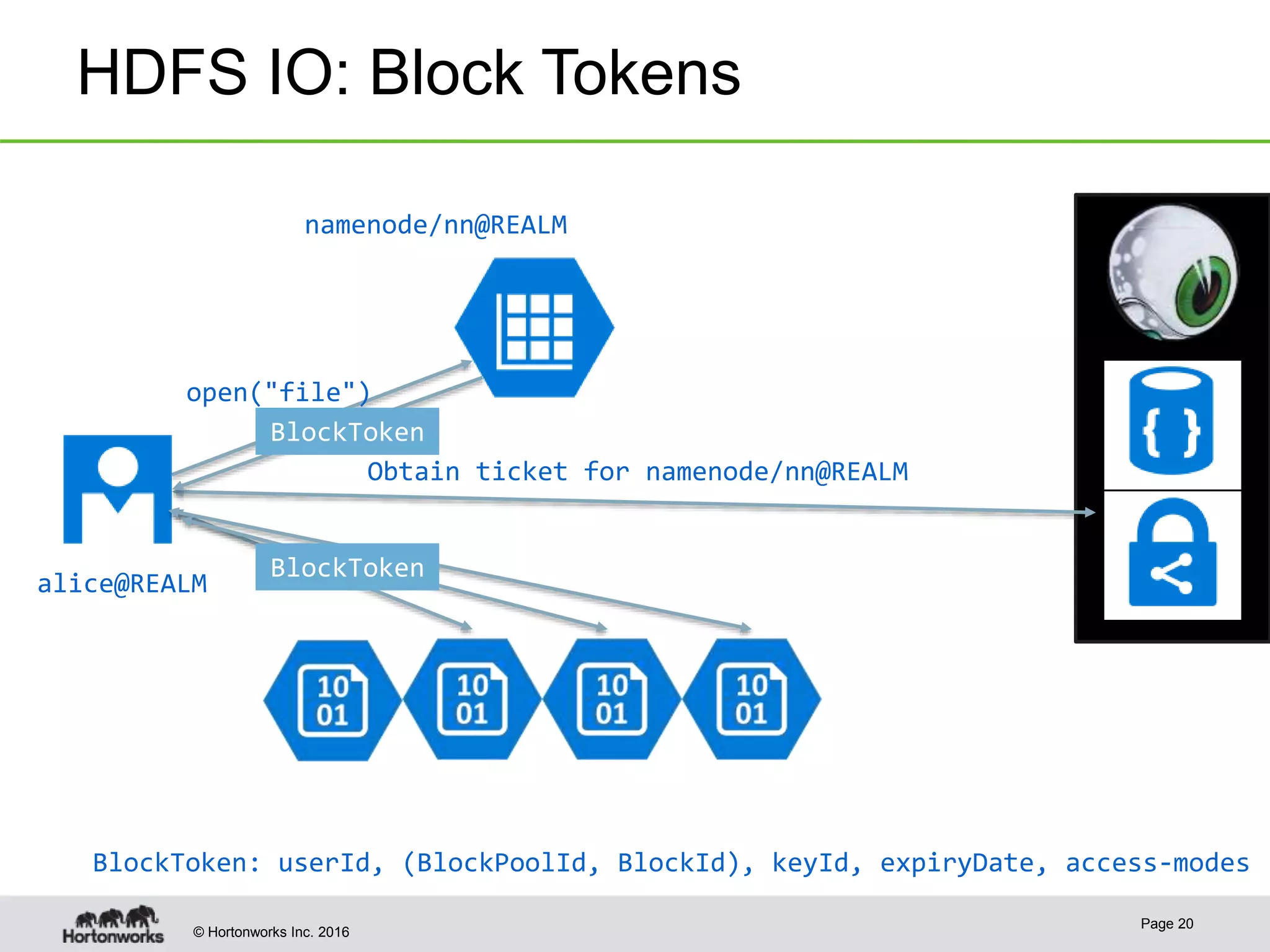
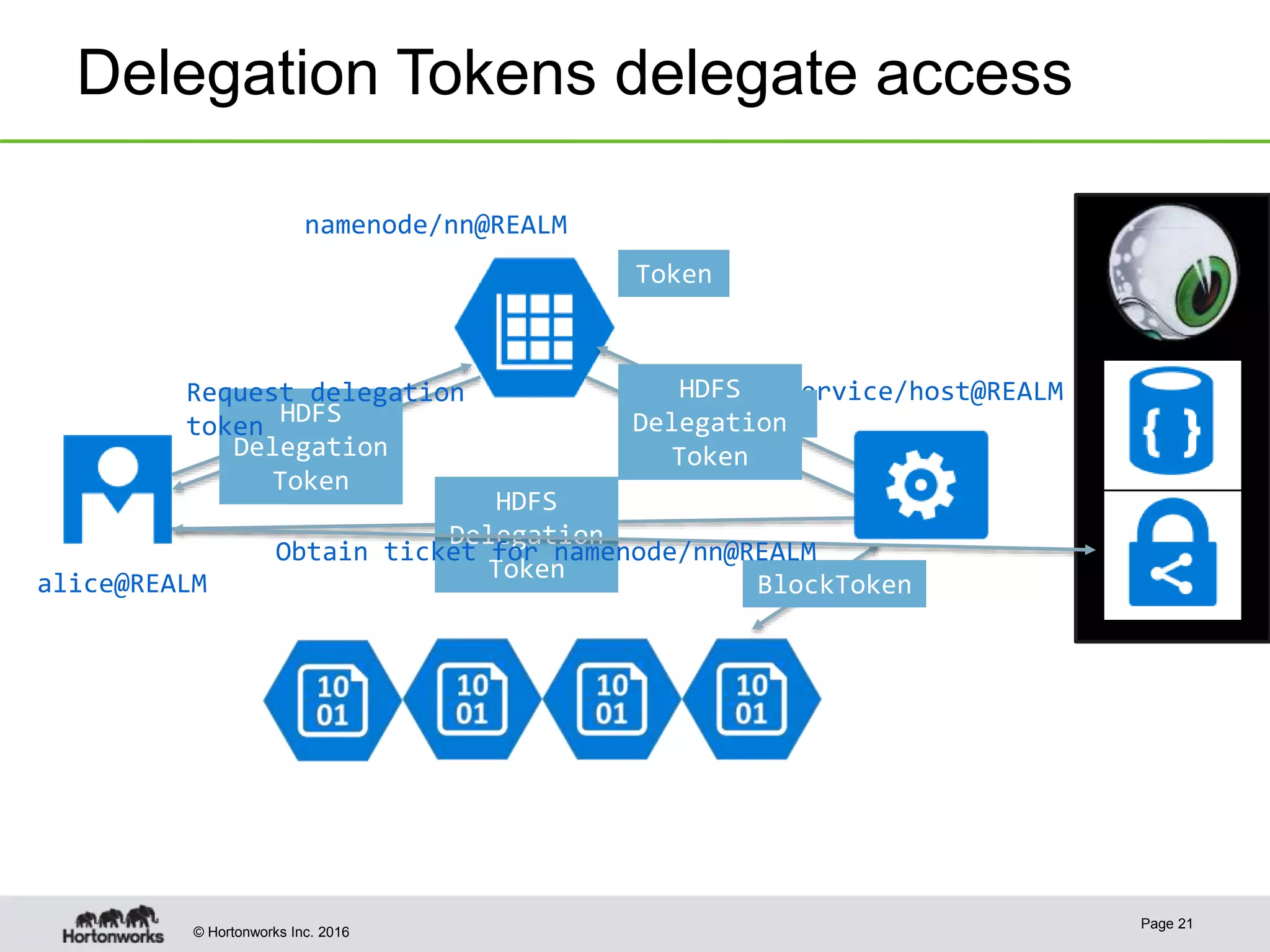
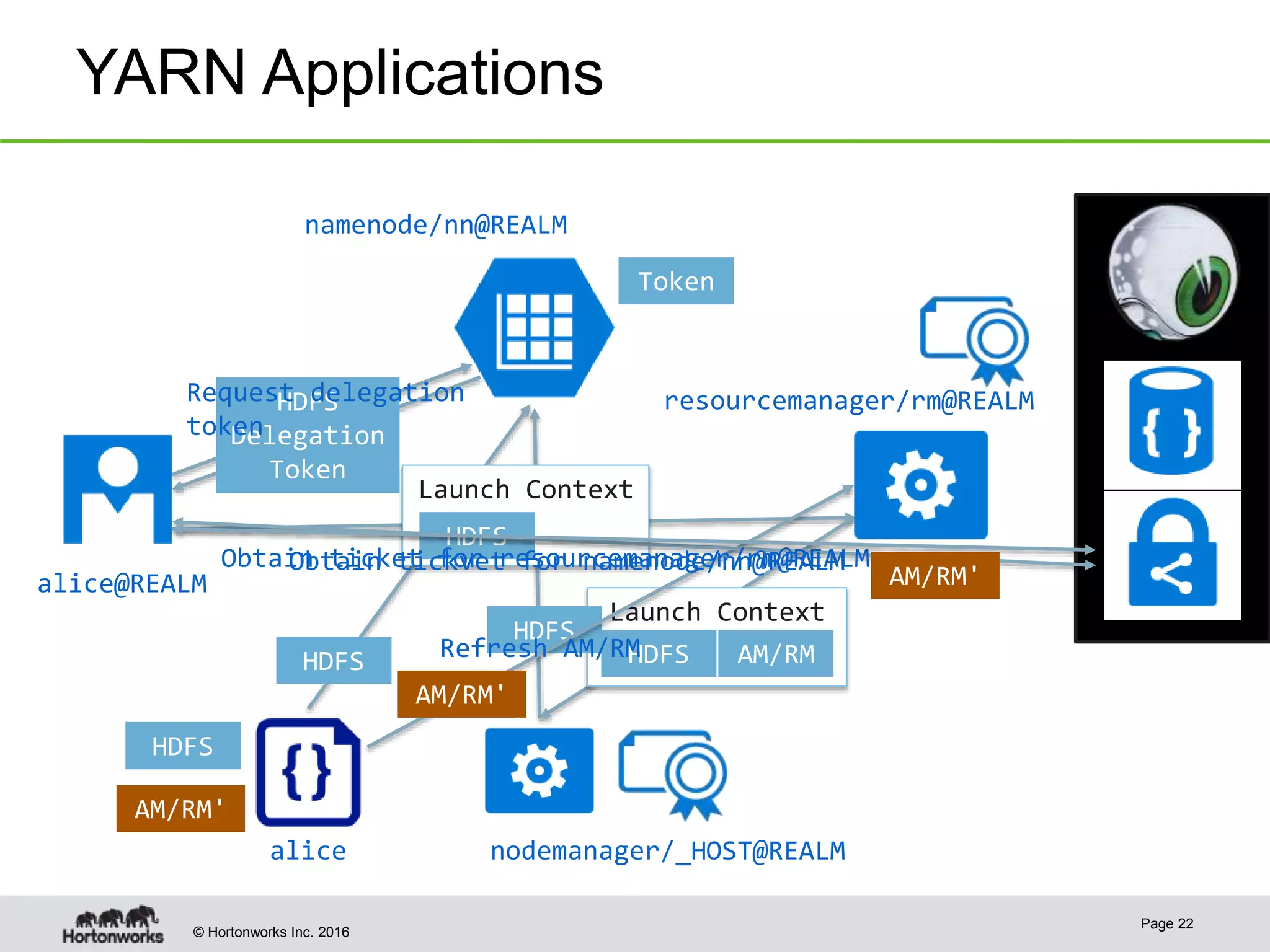
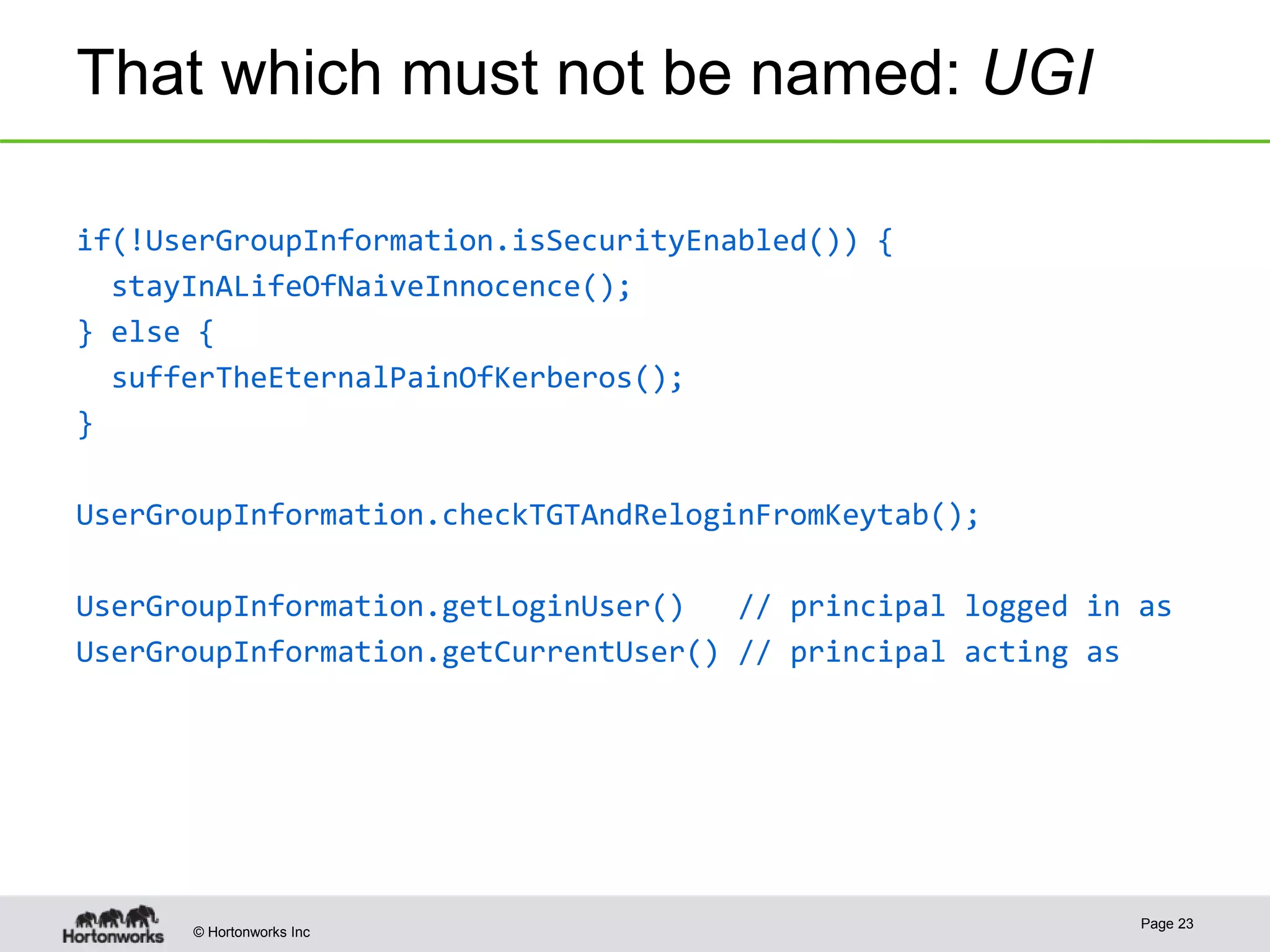
The document discusses the integration of Kerberos authentication in modern Hadoop clusters, emphasizing its role in securing access to services through various ticket and token mechanisms. It explains how user authentication and access control are managed via principals and delegation tokens, as well as the underlying architecture necessary for secure communication. Additionally, it touches on challenges and error handling associated with utilizing Kerberos in Hadoop environments.









































































































