


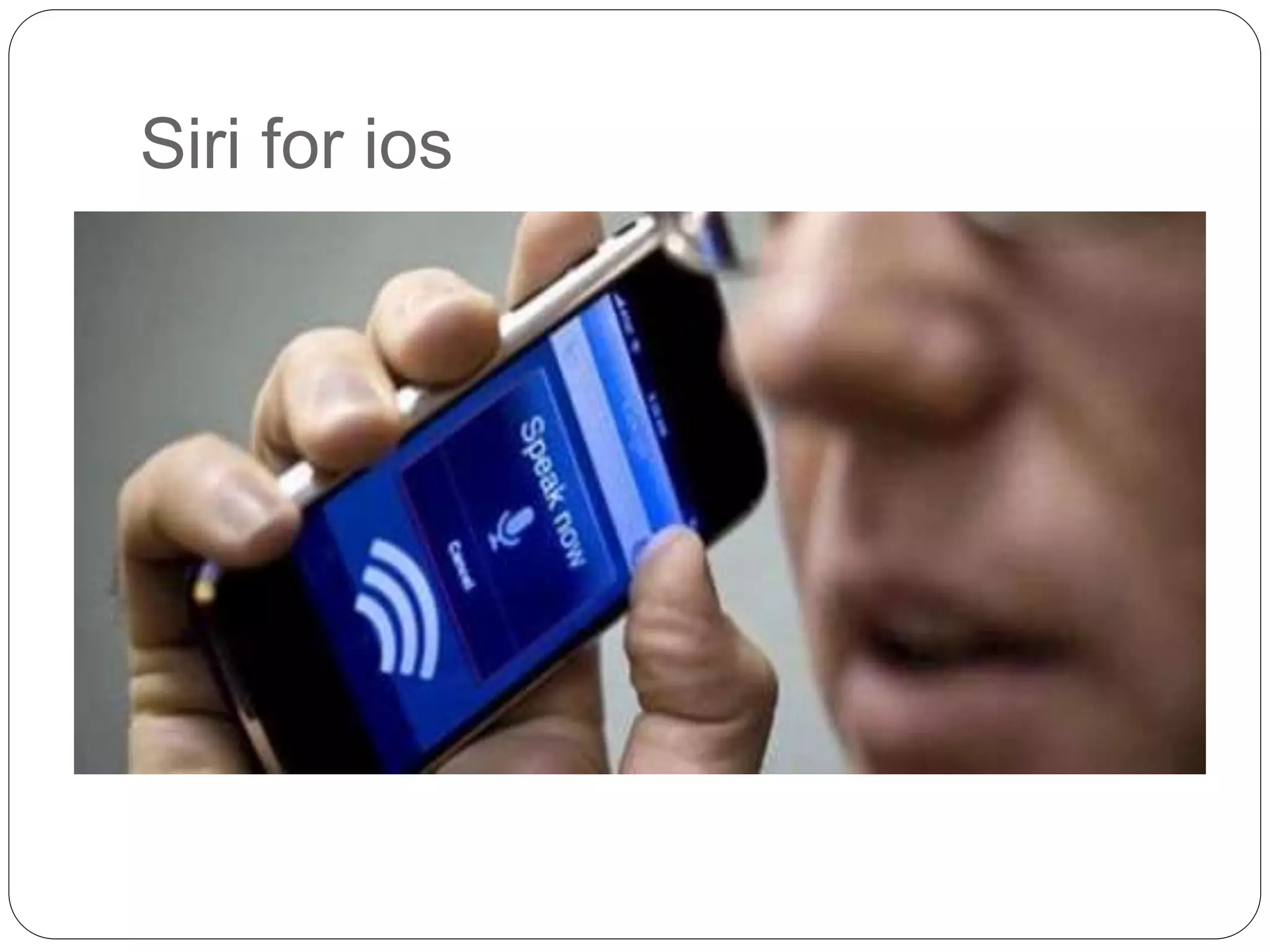

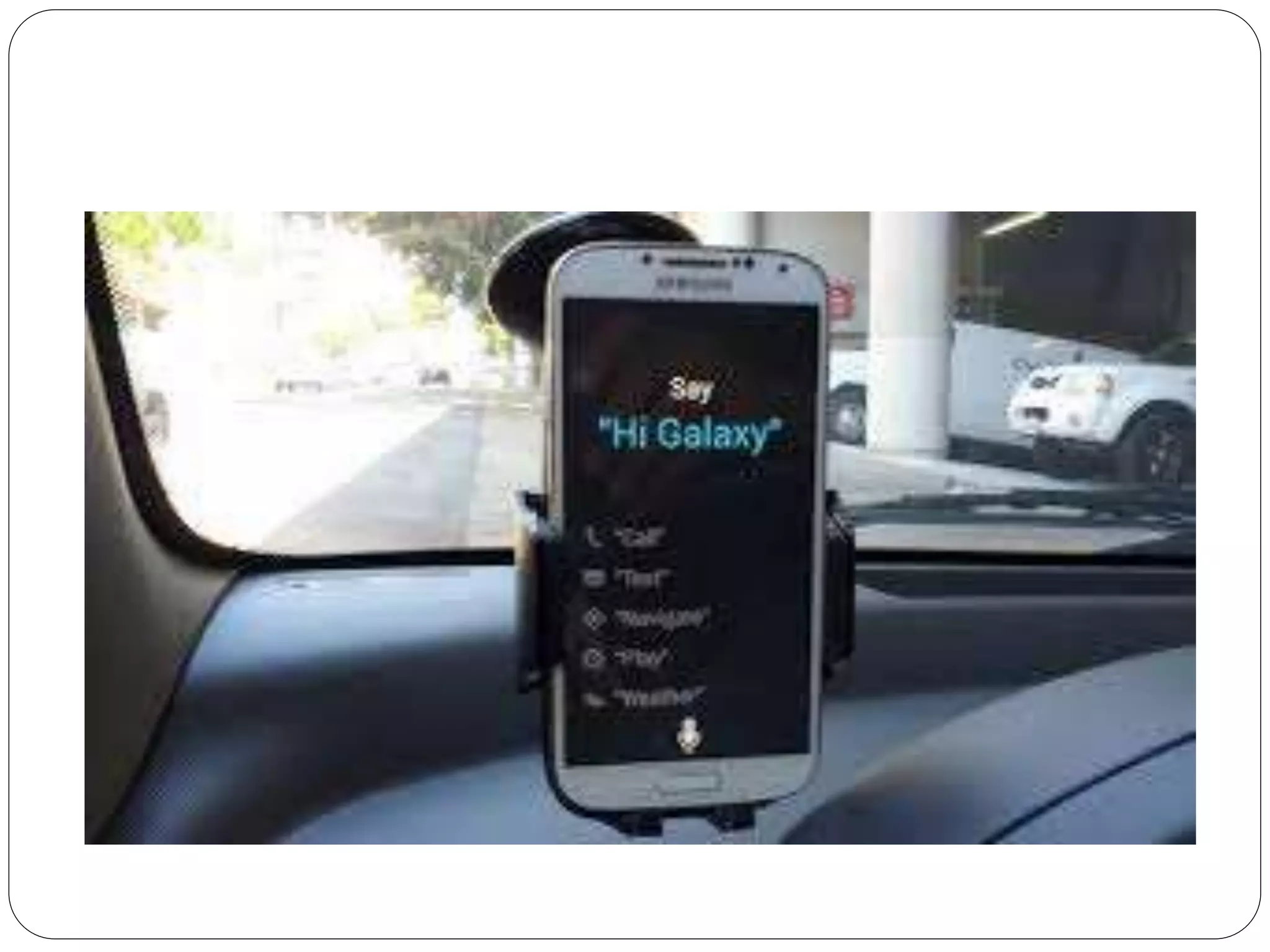

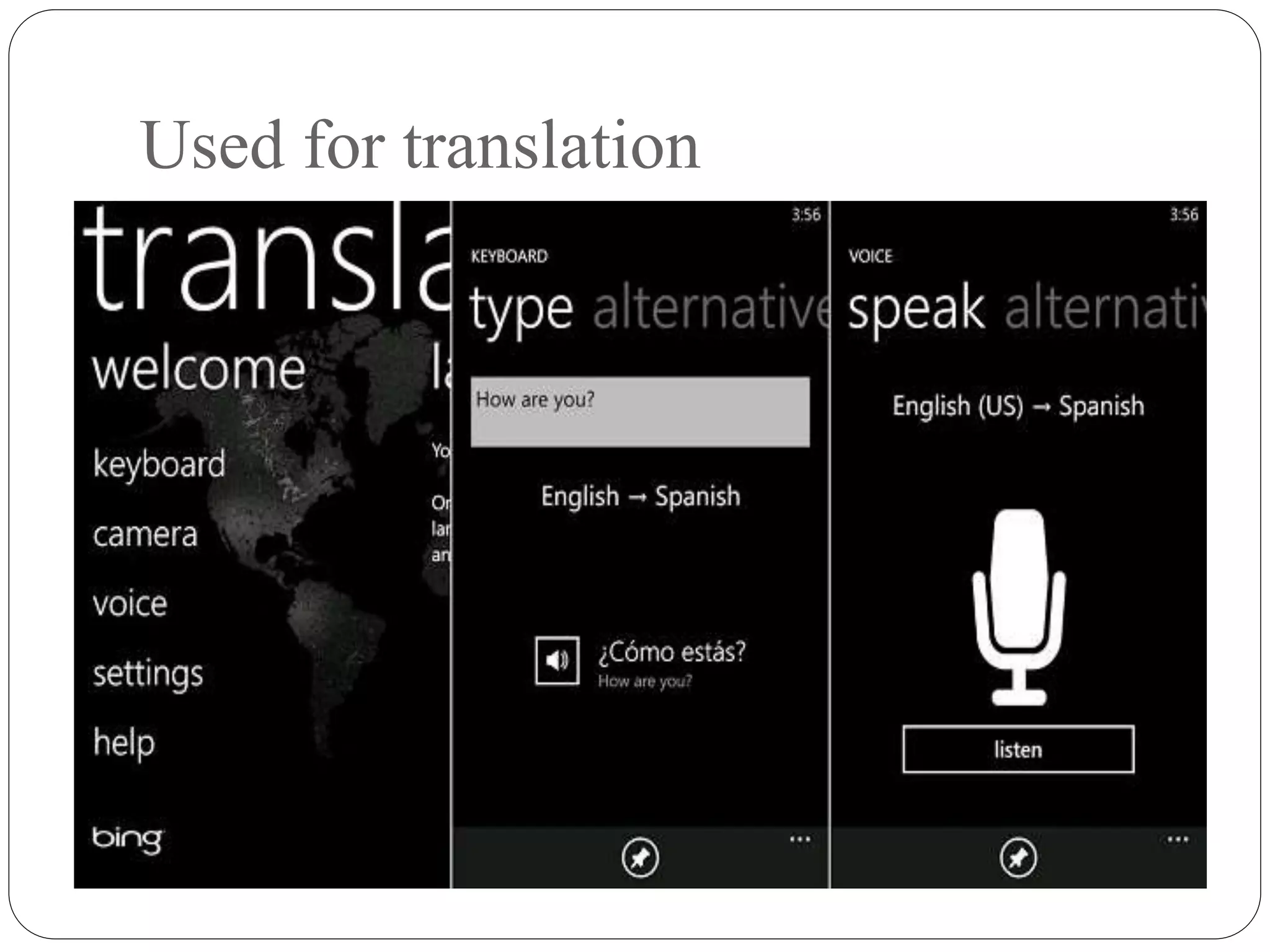

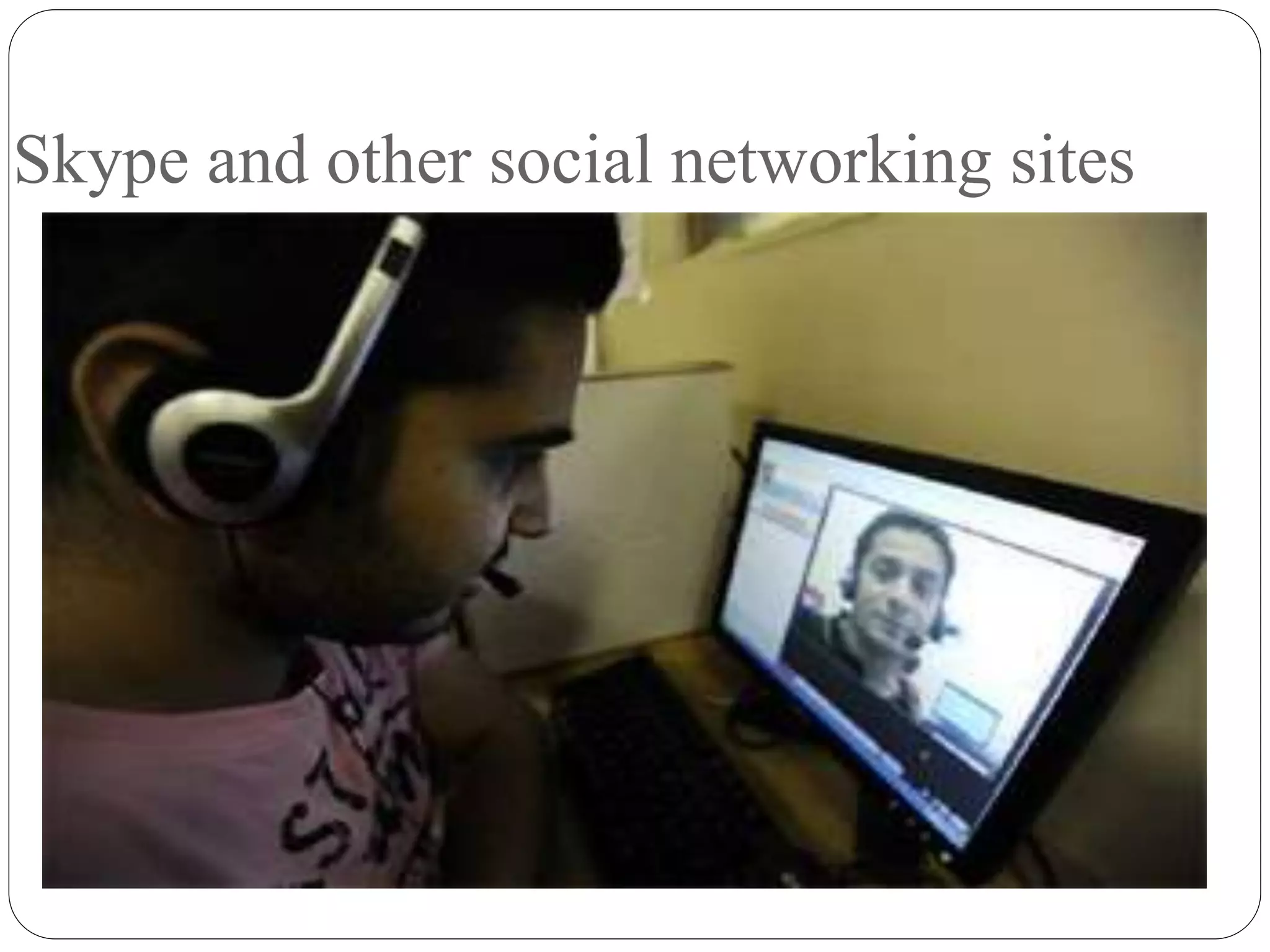




Voice input devices allow users to input data or commands using speech instead of other input methods like keyboards. Some voice input devices recognize words from a predefined vocabulary while others need to be trained for a specific speaker. When a word is spoken, the matching input is displayed on screen for verification. Speech recognition is the process of converting spoken language to text using computer programs. It draws from linguistics, computer science, and electrical engineering. Applications include voice assistants, dictation software, call routing, and more. Accuracy depends on factors like vocabulary size, presence of similar sounding words, whether the system is designed for one speaker or many, and whether speech is isolated, connected or continuous.
Definition and significance of speech recognition technology and its interdisciplinary applications.
Examples of speech recognition devices and applications including Siri, GPS, and social networking.
Overview of advancements in speech recognition technology, key players, and its applications in translation.
Examples of speech recognition devices and applications including Siri, GPS, and social networking.
Discussion on factors affecting the accuracy of speech recognition technology, challenges faced, and common errors.
Final remarks on the complexity of speech recognition and its importance in modern technology.











































































































