Downloaded 23 times



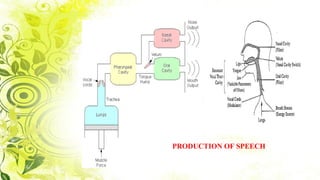






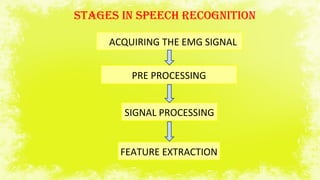

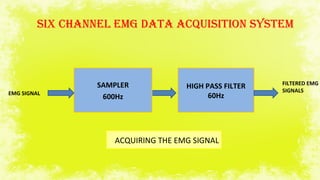





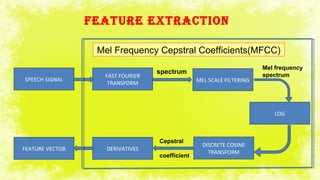
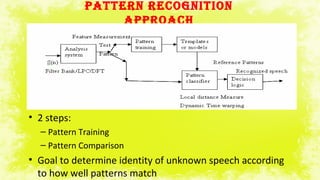


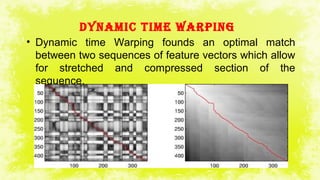

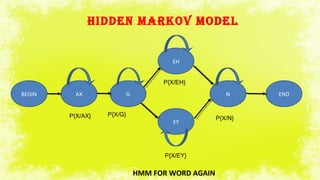













This document summarizes a study on electromyography (EMG)-based speech recognition using silent speech interface (SSI). EMG detects muscle cell electric potentials during activation. The study examines techniques for each stage of speech recognition and compares matching techniques. SSI uses EMG sensors on the face to record muscle signals during speech, which are converted to electric pulses and translated to speech without sound. Future prospects include incorporating EMG electrodes directly into systems and adding lip reading and translation to more languages.


















































![Silent_Sound_Technology_using _electromyography & image processing [1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/silentsoundtechnology1-241229054536-72f88f0d-thumbnail.jpg?width=640&height=640&fit=bounds)




































