Download as PDF, PPTX
















The document discusses research issues in speech processing. It covers topics like speech production, speech processing tasks, speech measurements, speech signal components, automatic speech recognition, speaker recognition, text-to-speech systems, speech coding, and a proposed speech-assisted translation corrector system. The key challenges in speech processing research are modeling the human auditory system, developing large multilingual speech databases, and generating natural sounding synthetic speech.
Overview of research issues in speech processing by Dr. M. Sabarimalai Manikandan.
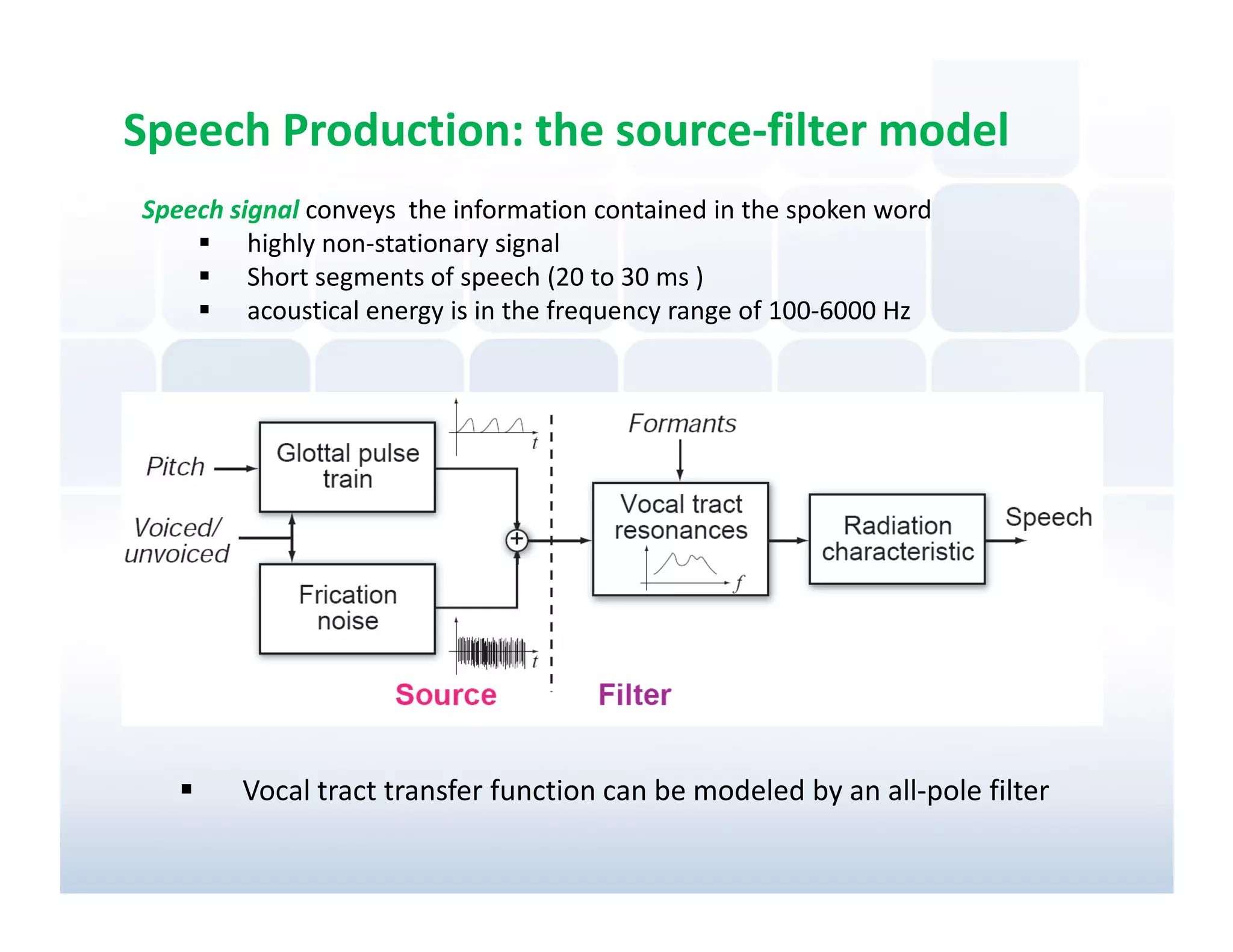
Explanation of the source-filter model in speech production, focusing on the non-stationary nature of speech signals and vocal tract modeling.
Description of various tasks in speech processing including recognition, synthesis, and enhancement.
Insights into speech measurements like Short-time energy and zero crossing rate, and classification of speech signal components.
Discussion of speech signal representations, including temporal and spectral features, highlighting methods like LPC and MFCC.
Introduction to phonemes as speech sound units, their classification into vowels and consonants, and the structure of syllables and words.
Overview of applications of speech recognition systems including dictation and computer control, and types of systems.
Diverse applications of speech recognition spanning automatic translation, navigation systems, and assistance for people with disabilities.
Breakdown of key processes in speech recognition systems including acoustic signal processing and phoneme recognition.
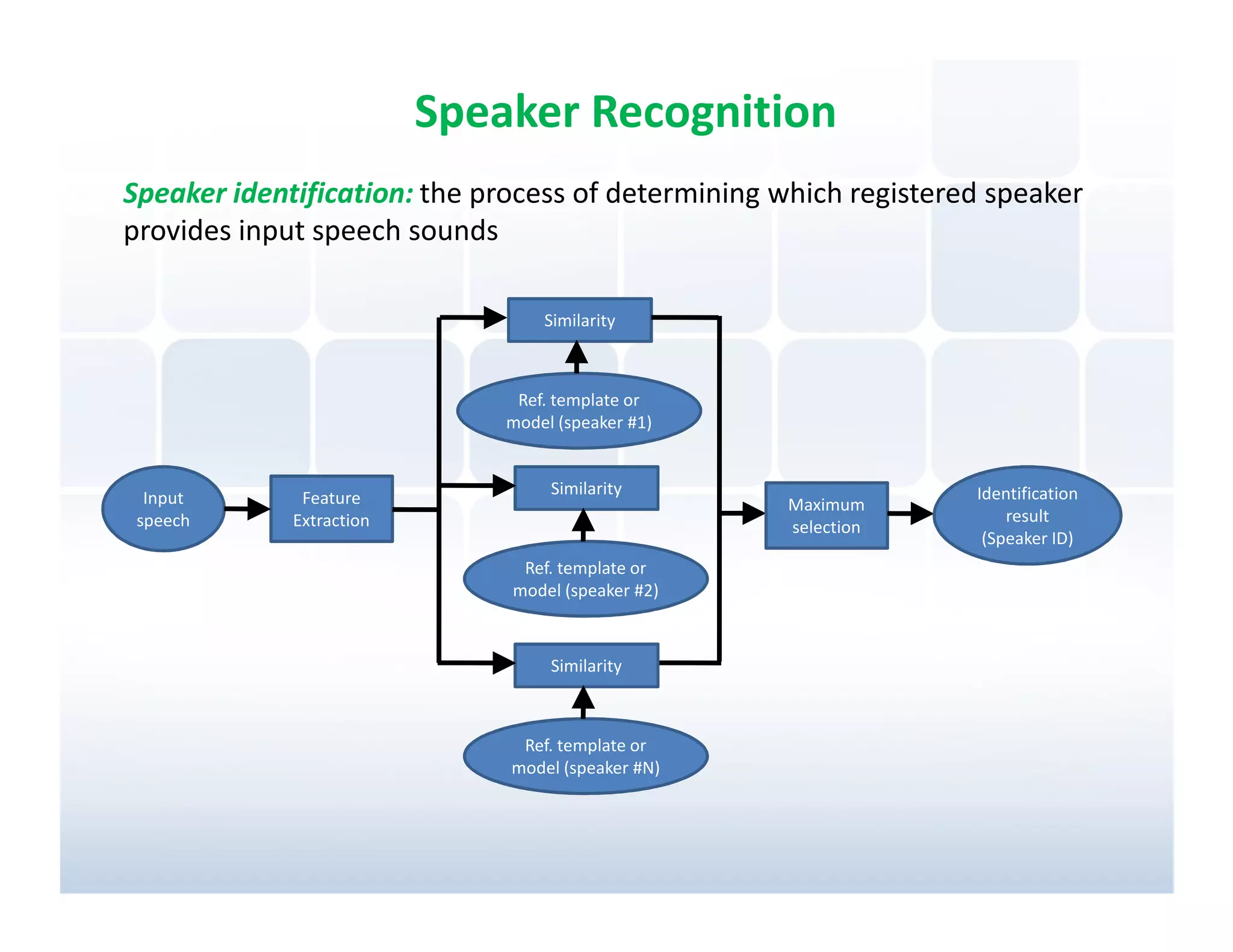
Explanation of speaker recognition, focusing on speaker identity, and physiological characteristics of speech production.
Details on speaker identification processes using feature extraction and template matching for recognizing speech inputs.
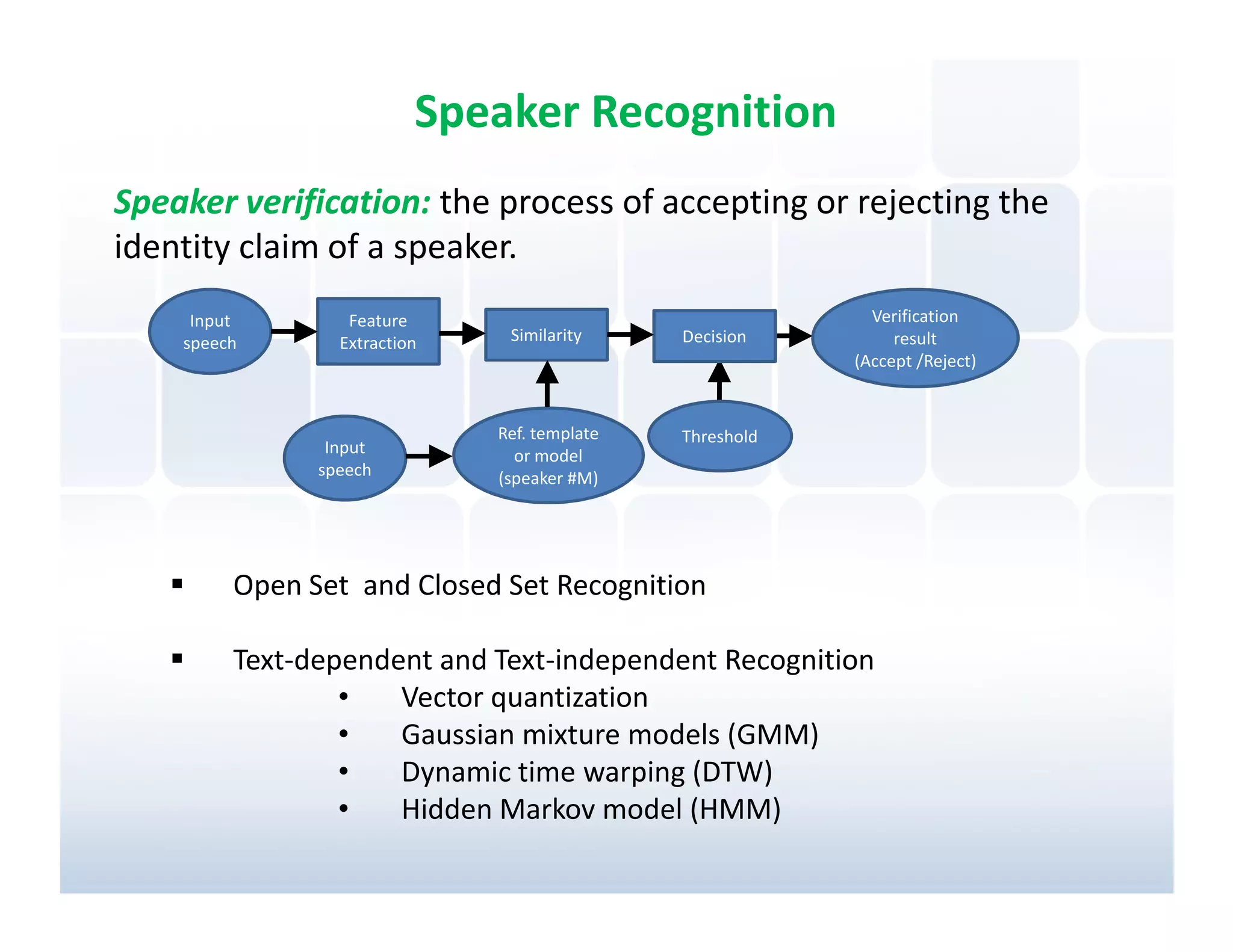
Discussion on speaker verification to validate identity claims and methodologies employed in recognition systems.
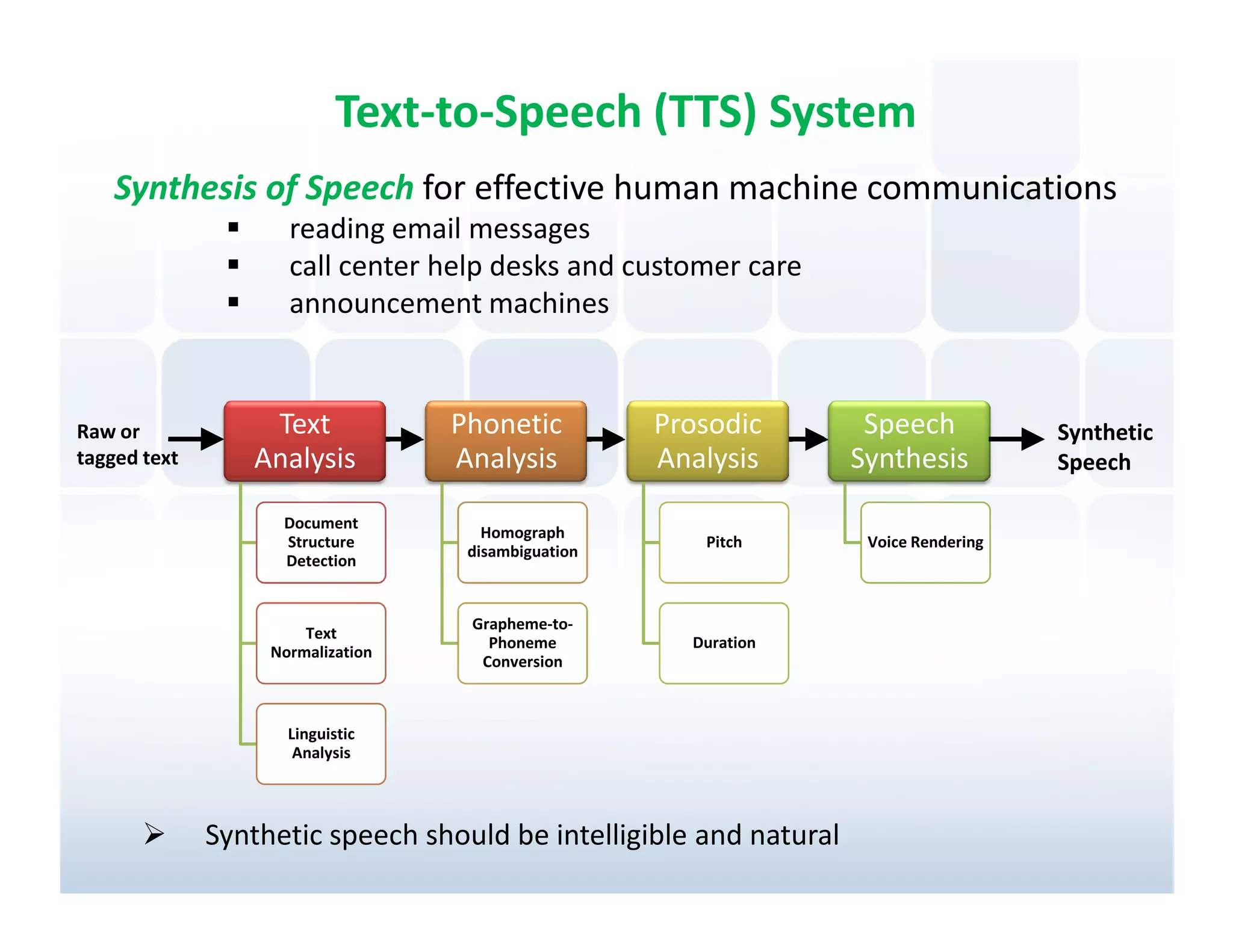
Overview of TTS systems and their application in communication and customer service, emphasizing intelligibility and naturalness.
Evaluation measures for TTS systems focusing on synthetic speech intelligibility and naturalness with specific tests.
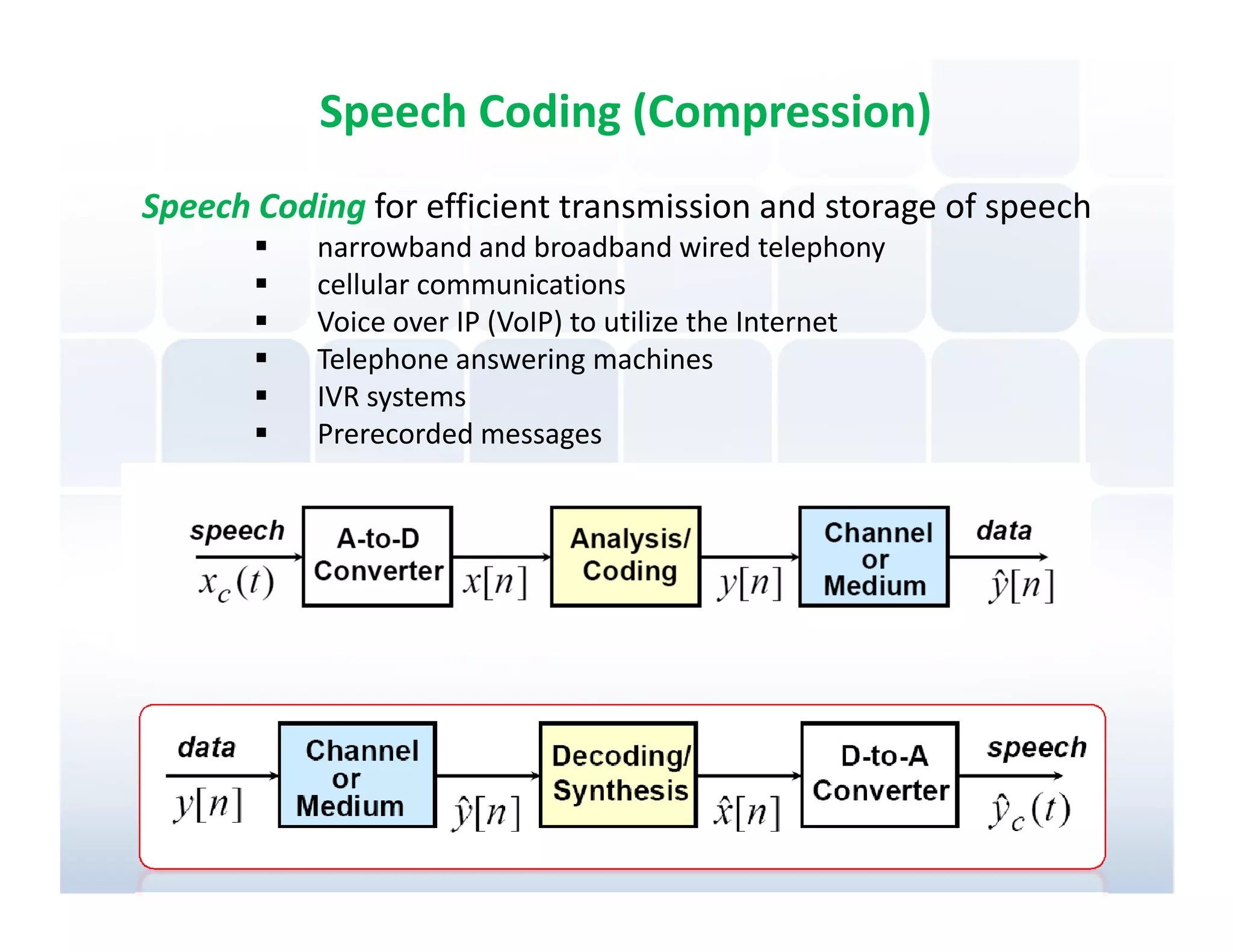
Importance of speech coding for efficient transmission and storage in various communication systems.
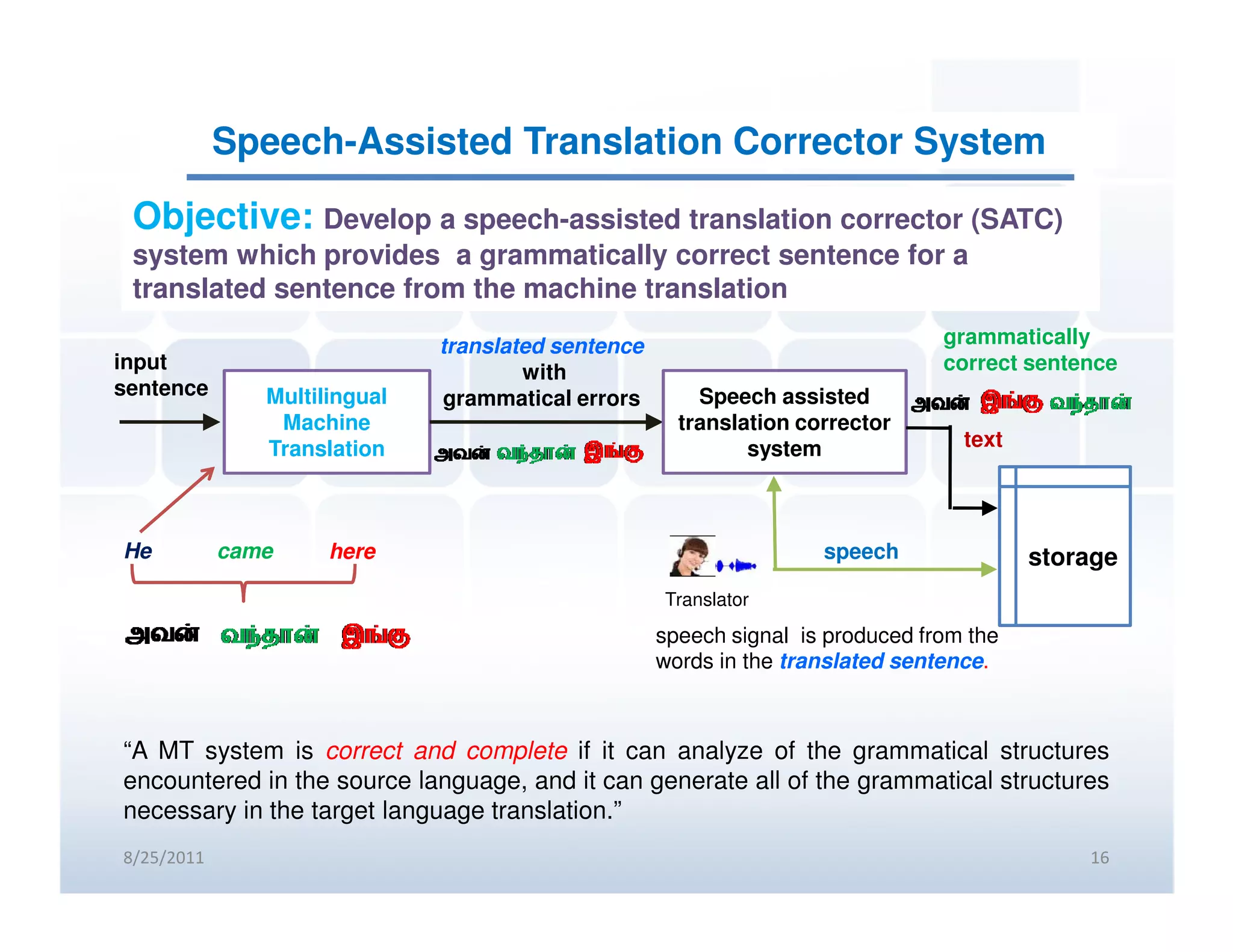
Objective and functionality of SATC systems to enhance machine translations to grammatically correct sentences.
Challenges in developing multilingual speech databases, including speaker diversity and audio specifications.
Acoustic variability issues affecting speech recognition, including environmental factors and speaker characteristics.
Challenges in speech processing due to linguistic and phonetic variability arising from accents and expressions.
Difficulties in recognizing continuous speech due to connected words affecting phoneme production.
List of academic references related to speech synthesis and processing technologies.












































































