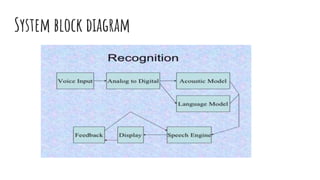
This document summarizes Google Voice-to-text technology and its applications. It discusses how speech recognition can help those with disabilities interact with computers using voice. It then outlines several applications of speech recognition including in cars, healthcare, the military, air traffic control, education, and entertainment. The document also discusses key performance metrics and factors that influence accuracy such as vocabulary size, speaker dependence, and speech type. It provides an overview of the system block diagram and its main components: the acoustic model, language model, and speech engine. Finally, it describes Google Cloud Speech API and how it can be used to transcribe audio and create subtitles for videos.