




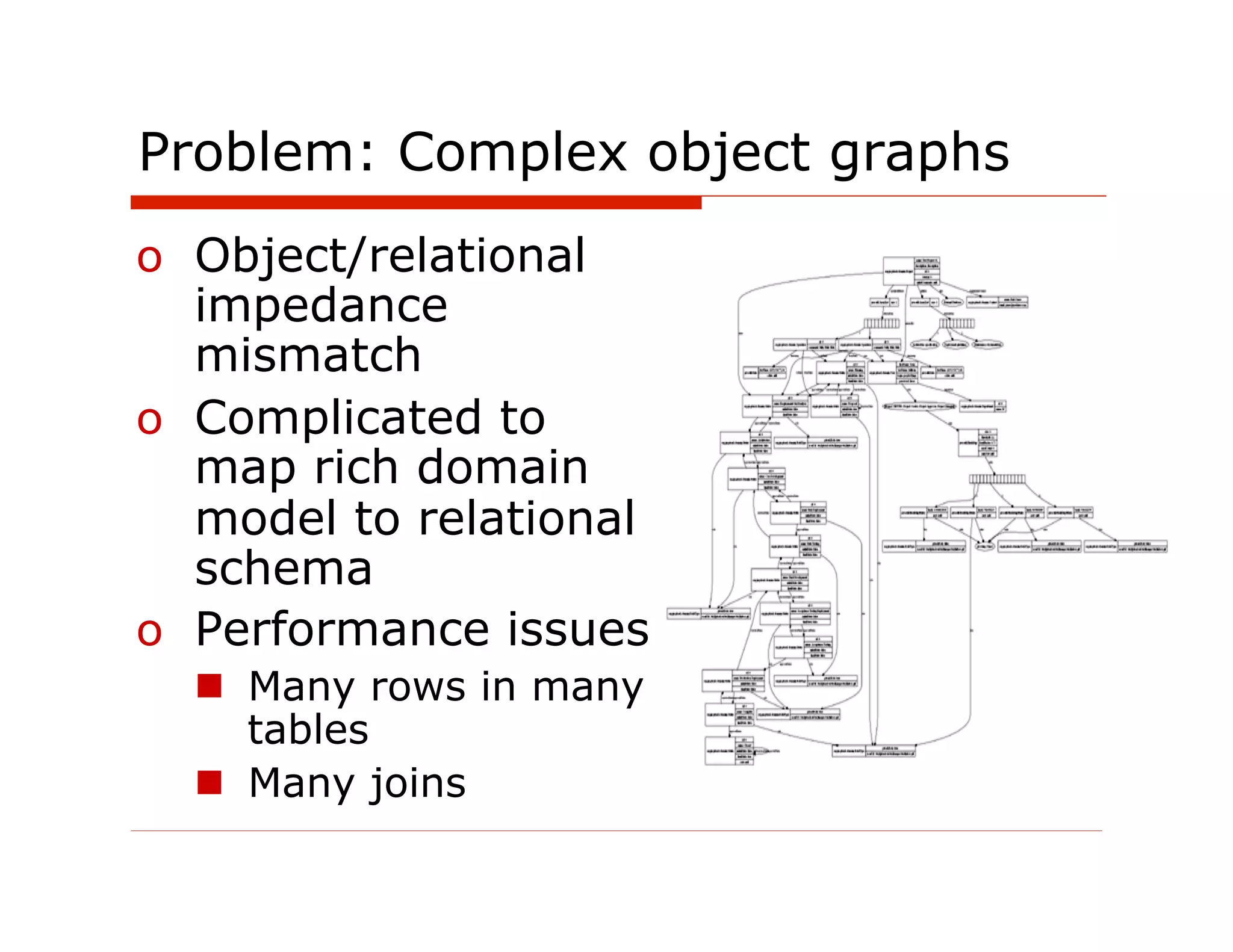













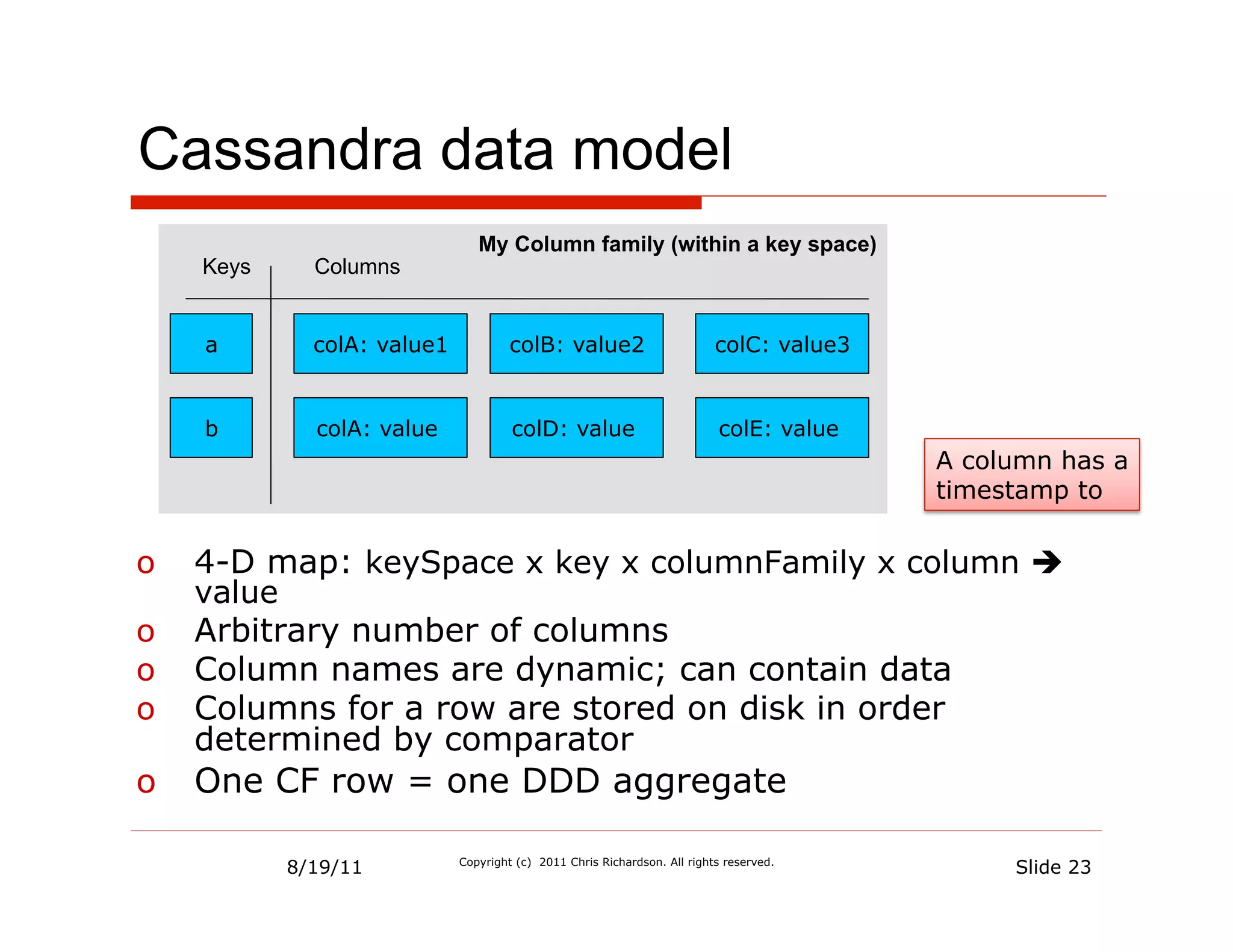
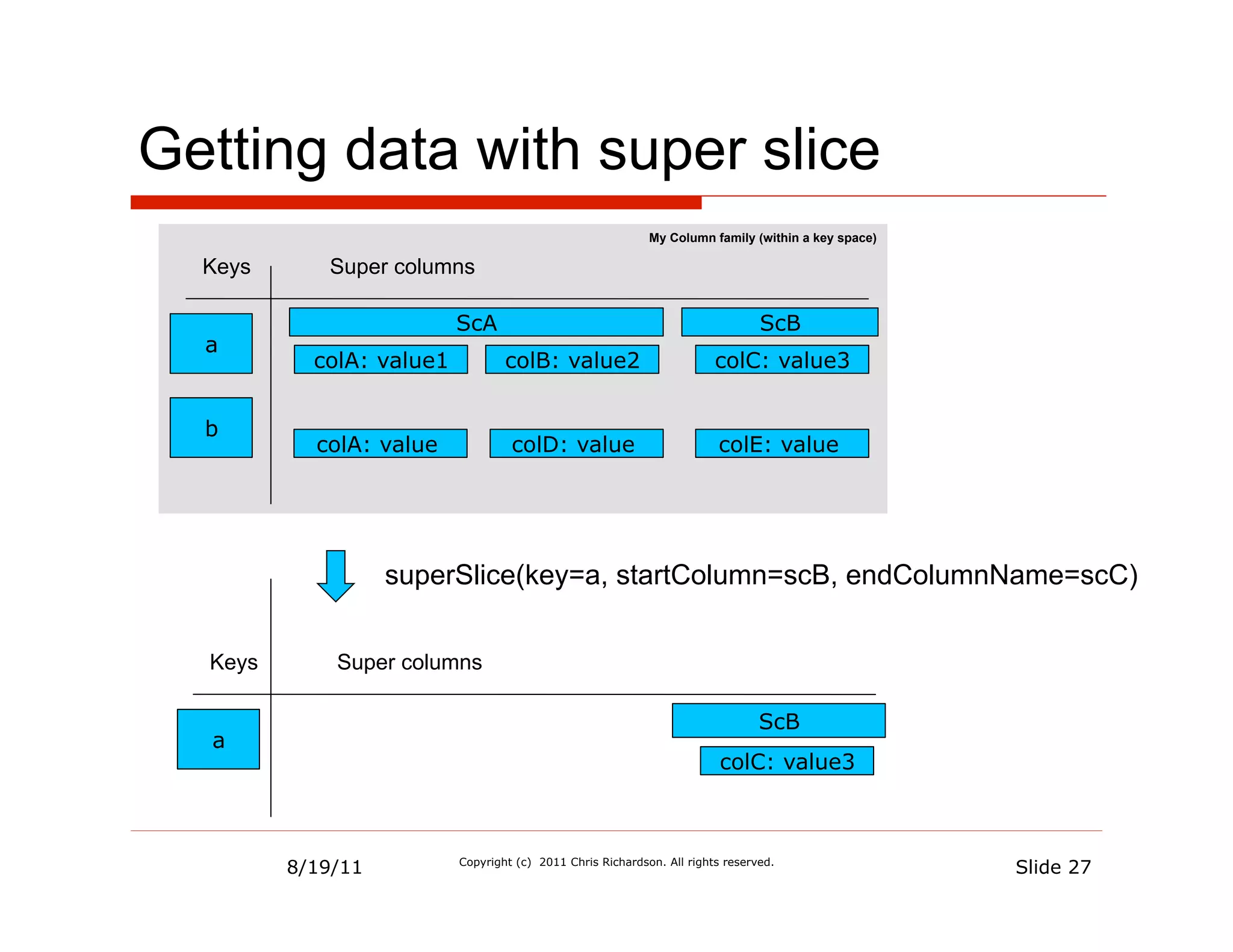
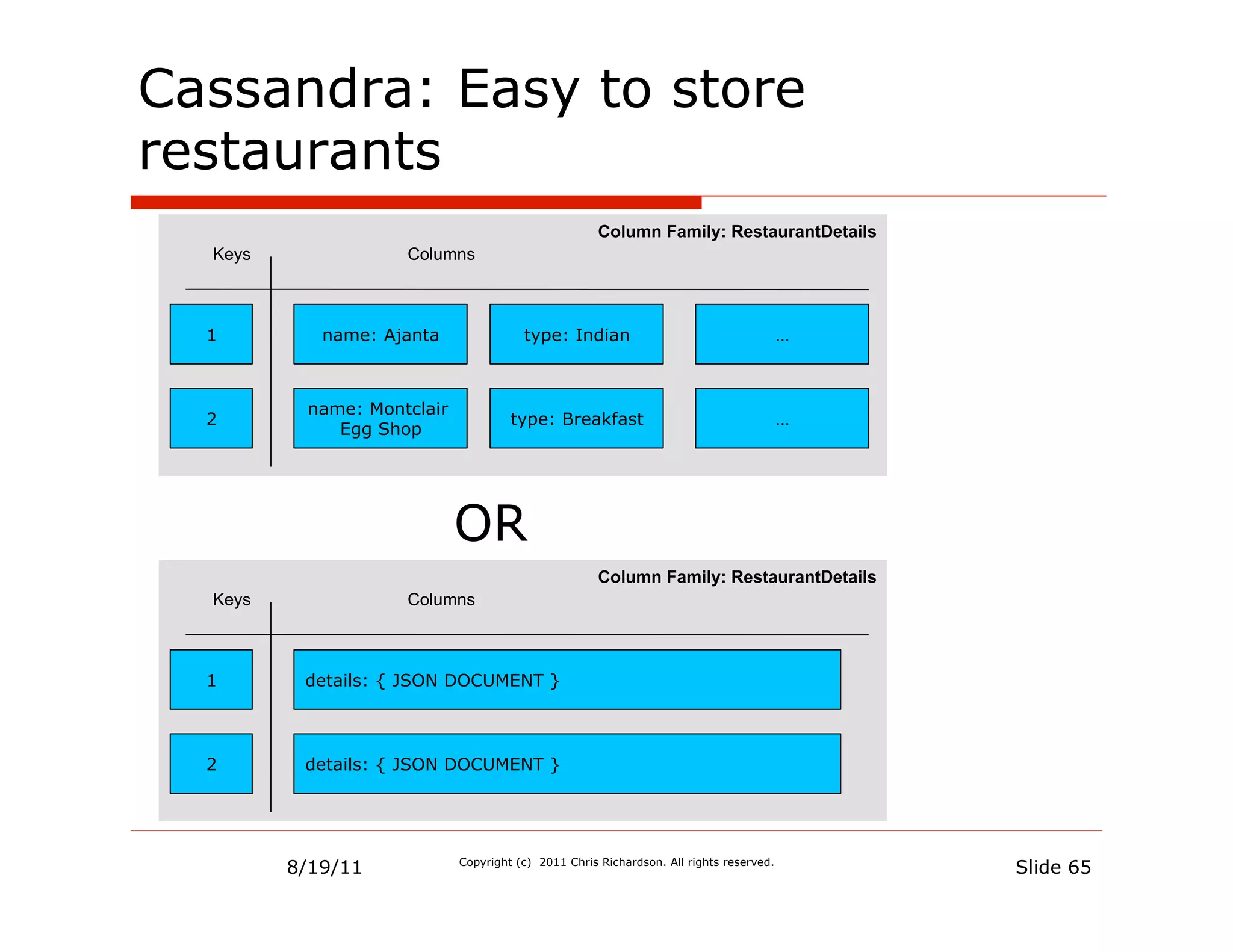
![Cassandra CLI
$ bin/cassandra-cli -h localhost
Connected to: "Test Cluster" on localhost/9160
Welcome to cassandra CLI.
[default@unknown] use Keyspace1;
Authenticated to keyspace: Keyspace1
[default@Keyspace1] list restaurantDetails;
Using default limit of 100
-------------------
RowKey: 1
=> (super_column=attributes,
(column=json, value={"id":
1,"name":"Ajanta","menuItems"....
[default@Keyspace1] get restaurantDetails['1']
['attributes’];
=> (column=json, value={"id":
1,"name":"Ajanta","menuItems"....
8/19/11 Copyright (c) 2011 Chris Richardson. All rights reserved.
Slide 28](https://image.slidesharecdn.com/polygotpersistenceforjavadevsoakjug2011-110821153343-phpapp02/75/Polygot-persistence-for-Java-Developers-August-2011-Oakjug-28-2048.jpg)
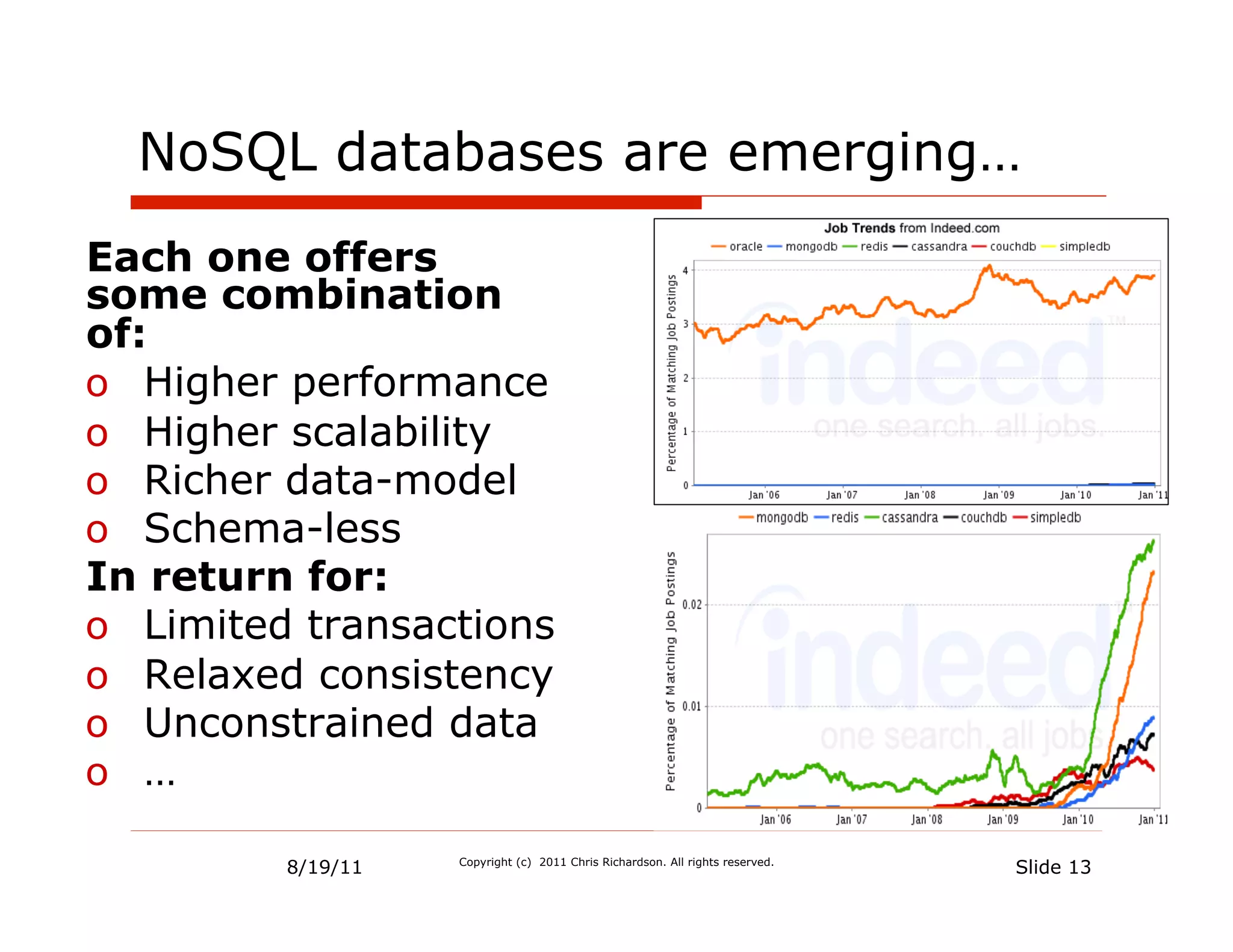
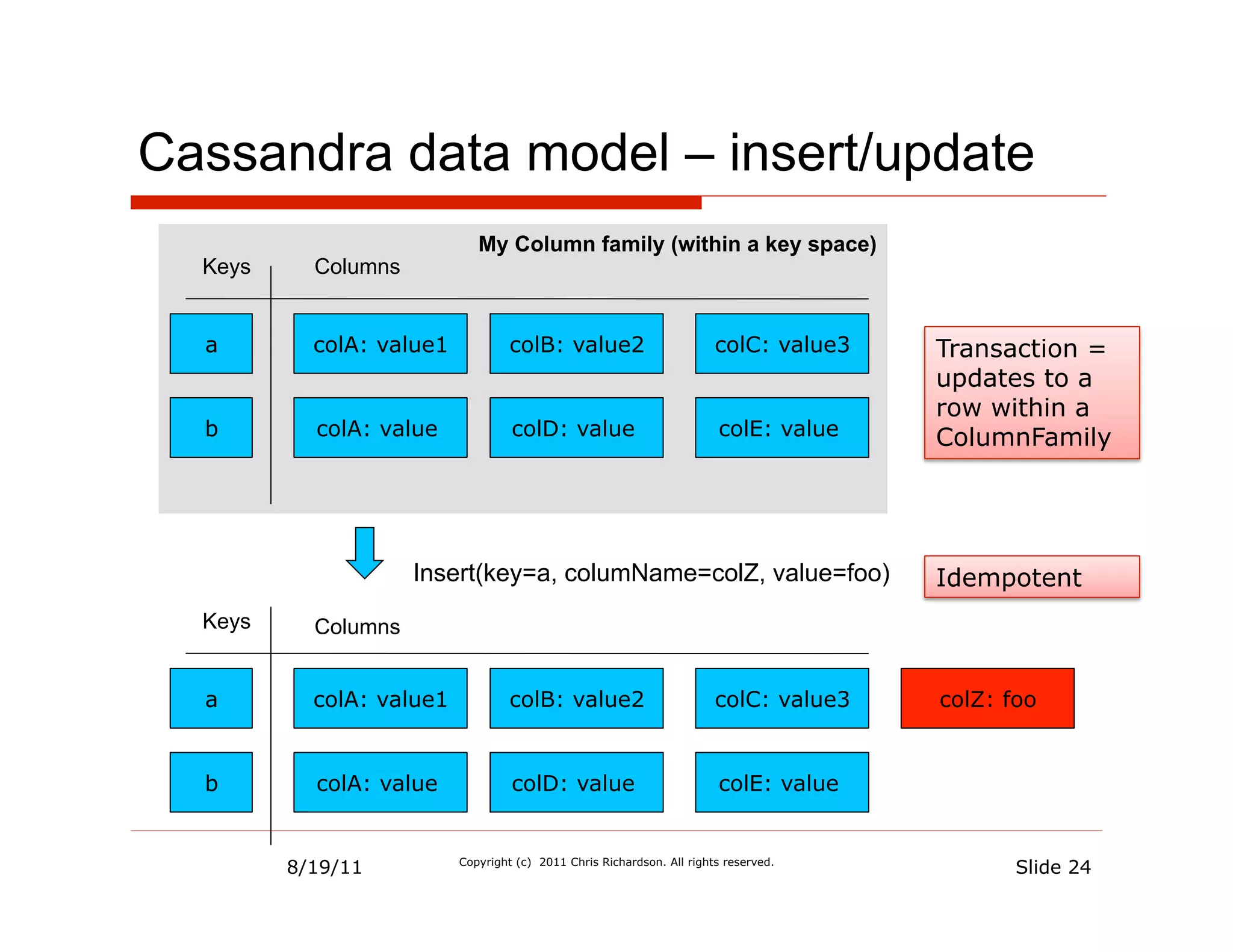
![Scaling Cassandra
• Client connects to any node
• Dynamically add/remove nodes
Keys = [D, A]
Node 1 • Reads/Writes specify how many nodes
• Configurable # of replicas
Token = A • adjacent nodes
• rack and data center aware
replicates replicates
Node 4 Node 2
Keys = [A, B]
Token = D Token = B
replicates
Keys = [C, D] replicates Replicates to
Node 3
Token = C
Keys = [B, C]
8/19/11 Copyright (c) 2011 Chris Richardson. All rights reserved.
Slide 29](https://image.slidesharecdn.com/polygotpersistenceforjavadevsoakjug2011-110821153343-phpapp02/75/Polygot-persistence-for-Java-Developers-August-2011-Oakjug-29-2048.jpg)



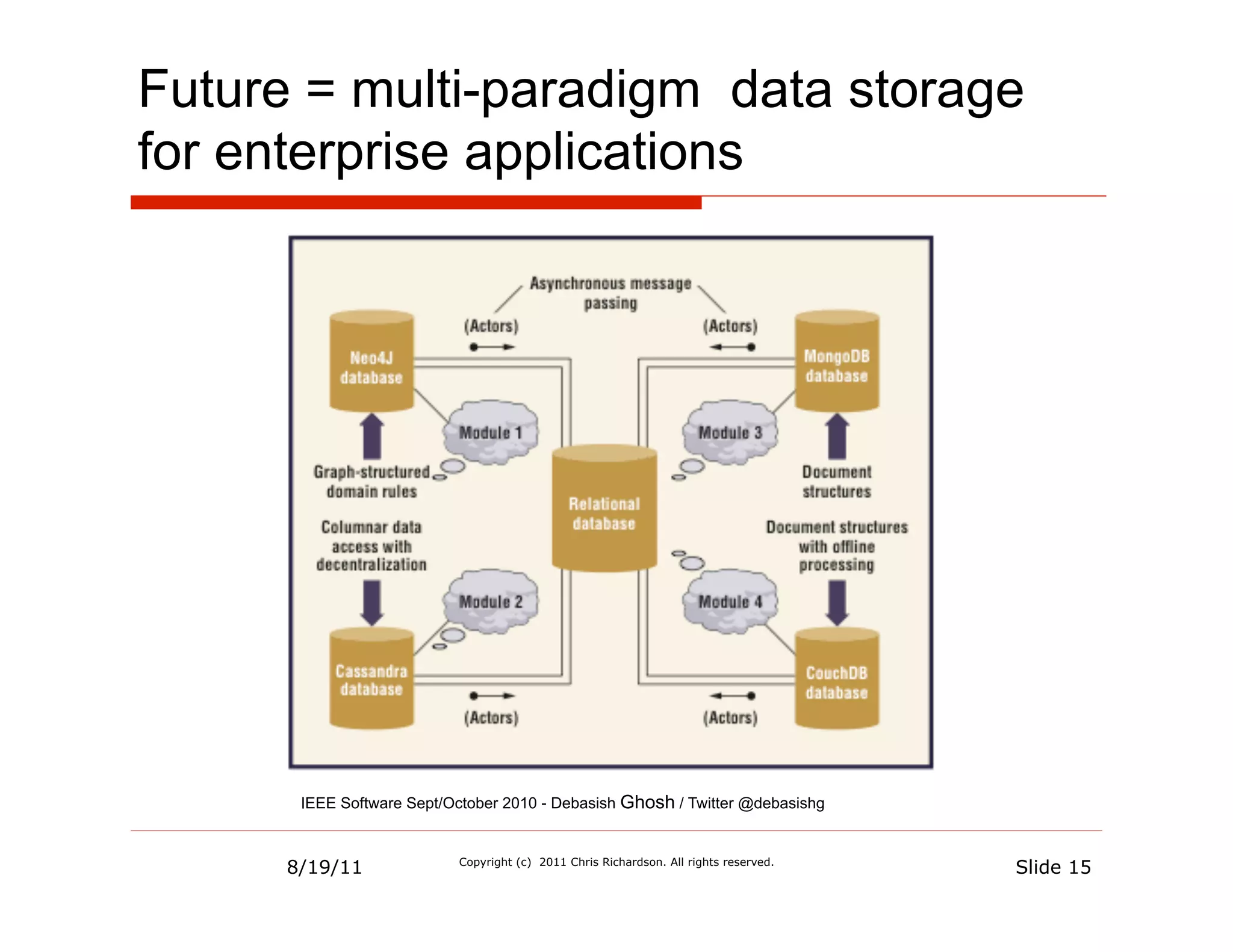
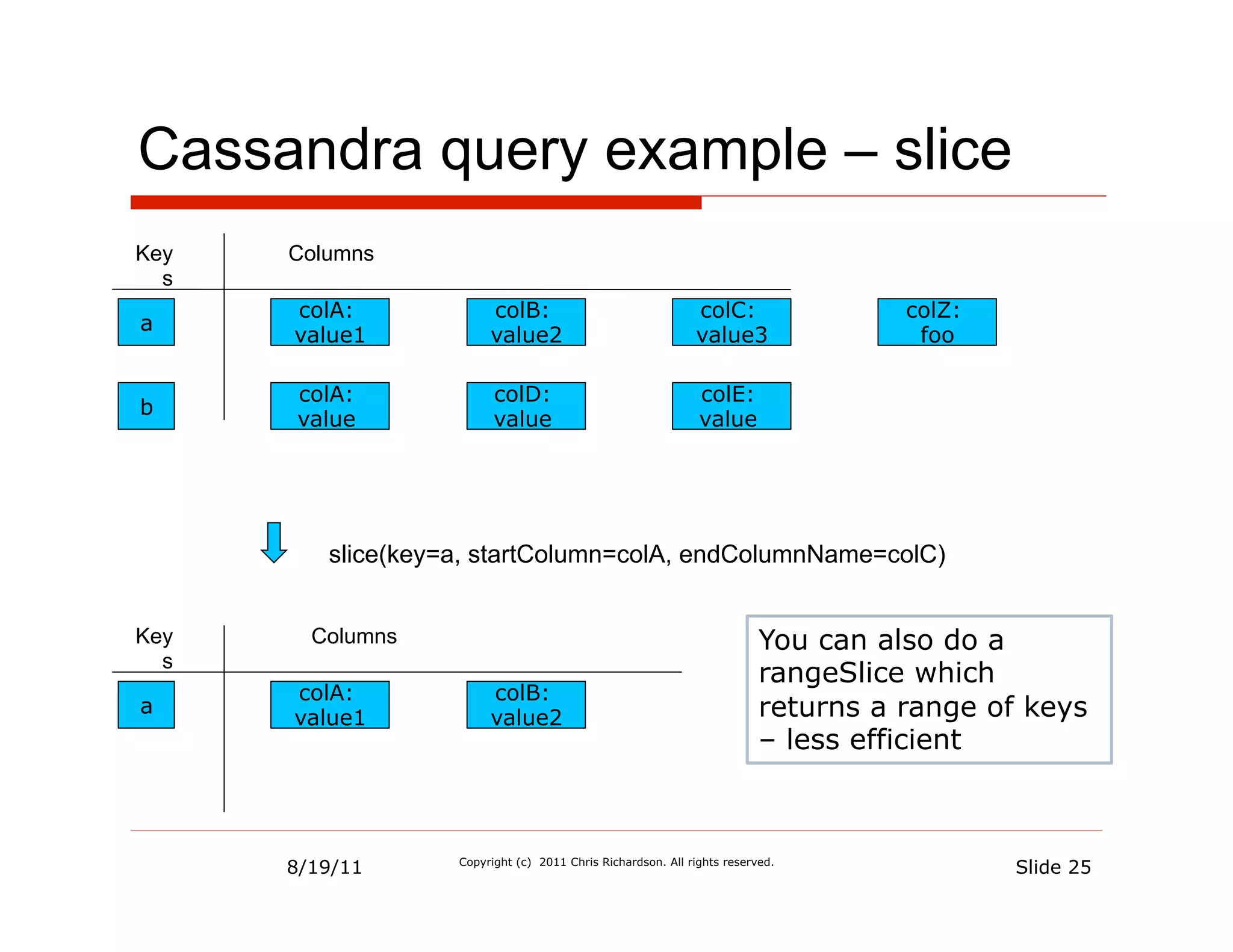
![Data Model = Binary JSON documents
{
"name" : "Sahn Maru", One document
"type" : ”Korean",
"serviceArea" : [ =
"94619",
"94618" one DDD aggregate
],
"openingHours" : [
{ DBObject o = new BasicDBObject();
"dayOfWeek" : "Wednesday", o.put("name", ”Sahn Maru");
"open" : 1730,
"close" : 2230 DBObject mi = new BasicDBObject();
} mi.put("name", "Daeji Bulgogi");
], …
"_id" : ObjectId("4bddc2f49d1505567c6220a0") List<DBObject> mis = Collections.singletonList(mi);
}
o.put("menuItems", mis);
o Sequence of bytes on disk = fast I/O
n No joins/seeks
n In-place updates when possible è no index updates
o Transaction = update of single document
8/19/11 Copyright (c) 2011 Chris Richardson. All rights reserved.
Slide 33](https://image.slidesharecdn.com/polygotpersistenceforjavadevsoakjug2011-110821153343-phpapp02/75/Polygot-persistence-for-Java-Developers-August-2011-Oakjug-33-2048.jpg)













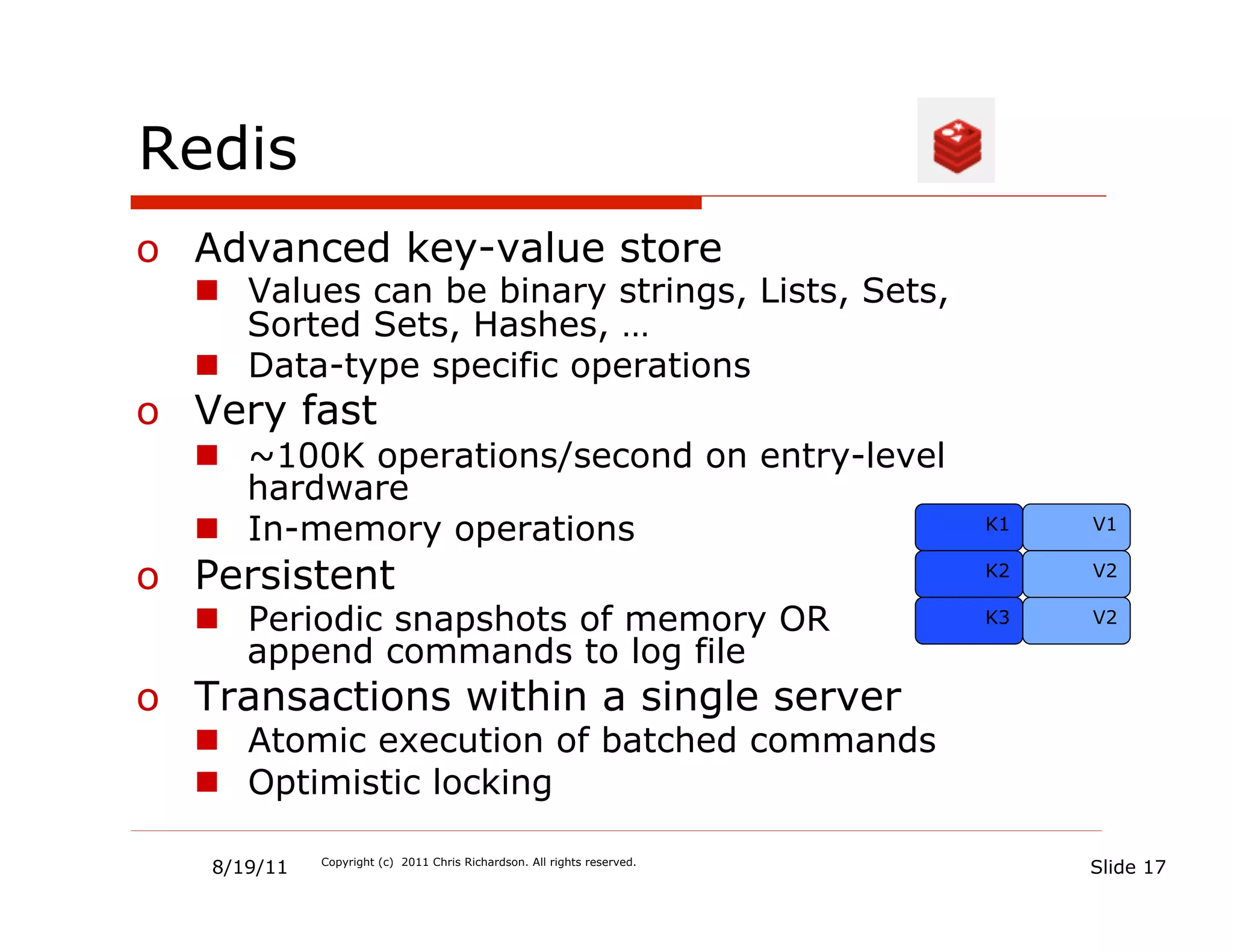
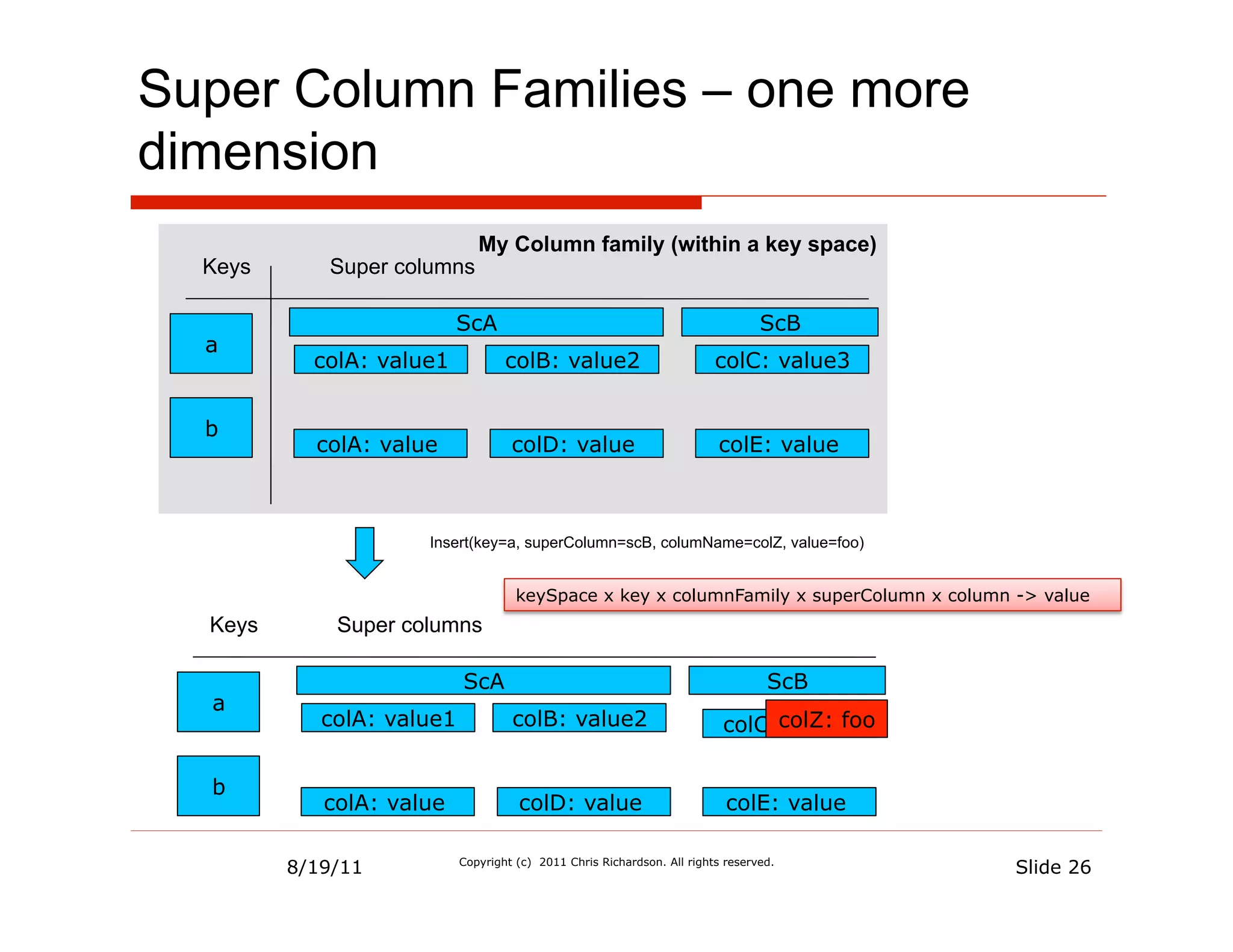
![Redis - Persisting restaurants is
“easy”
rest:1:details [ name: “Ajanta”, … ]
Multiple KV value
rest:1:serviceArea [ “94619”, “94611”, …]
pairs
rest:1:openingHours [10, 11]
timerange:10 [“dayOfWeek”: “Monday”, ..]
timerange:11 [“dayOfWeek”: “Tuesday”, ..]
Single KV hash
OR
rest:1 [ name: “Ajanta”,
“serviceArea:0” : “94611”, “serviceArea:1” : “94619”,
“menuItem:0:name”, “Chicken Vindaloo”,
…]
OR
Single KV String
rest:1 { .. A BIG STRING/BYTE ARRAY, E.G. JSON }
8/19/11 Copyright (c) 2011 Chris Richardson. All rights reserved.
Slide 55](https://image.slidesharecdn.com/polygotpersistenceforjavadevsoakjug2011-110821153343-phpapp02/75/Polygot-persistence-for-Java-Developers-August-2011-Oakjug-55-2048.jpg)

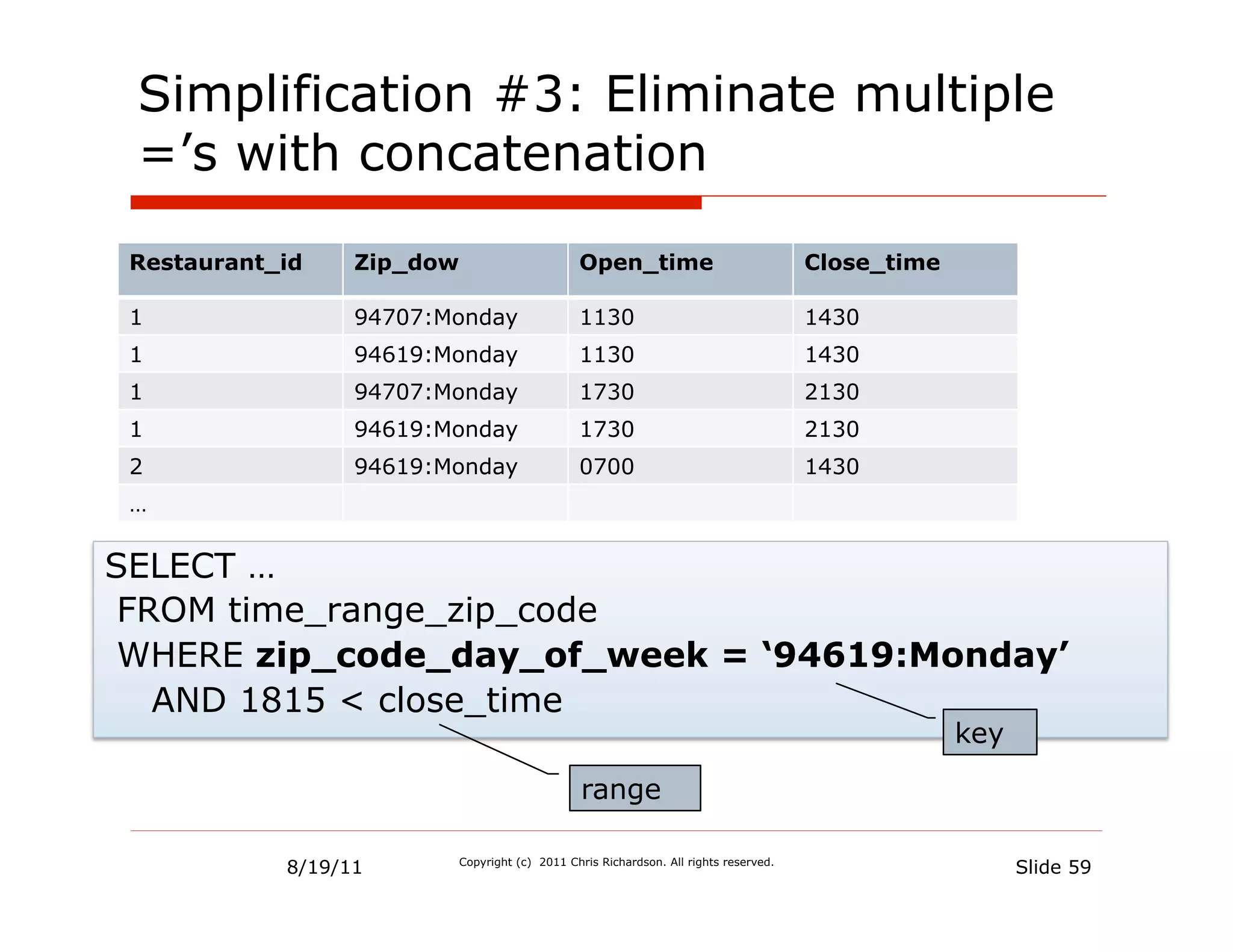
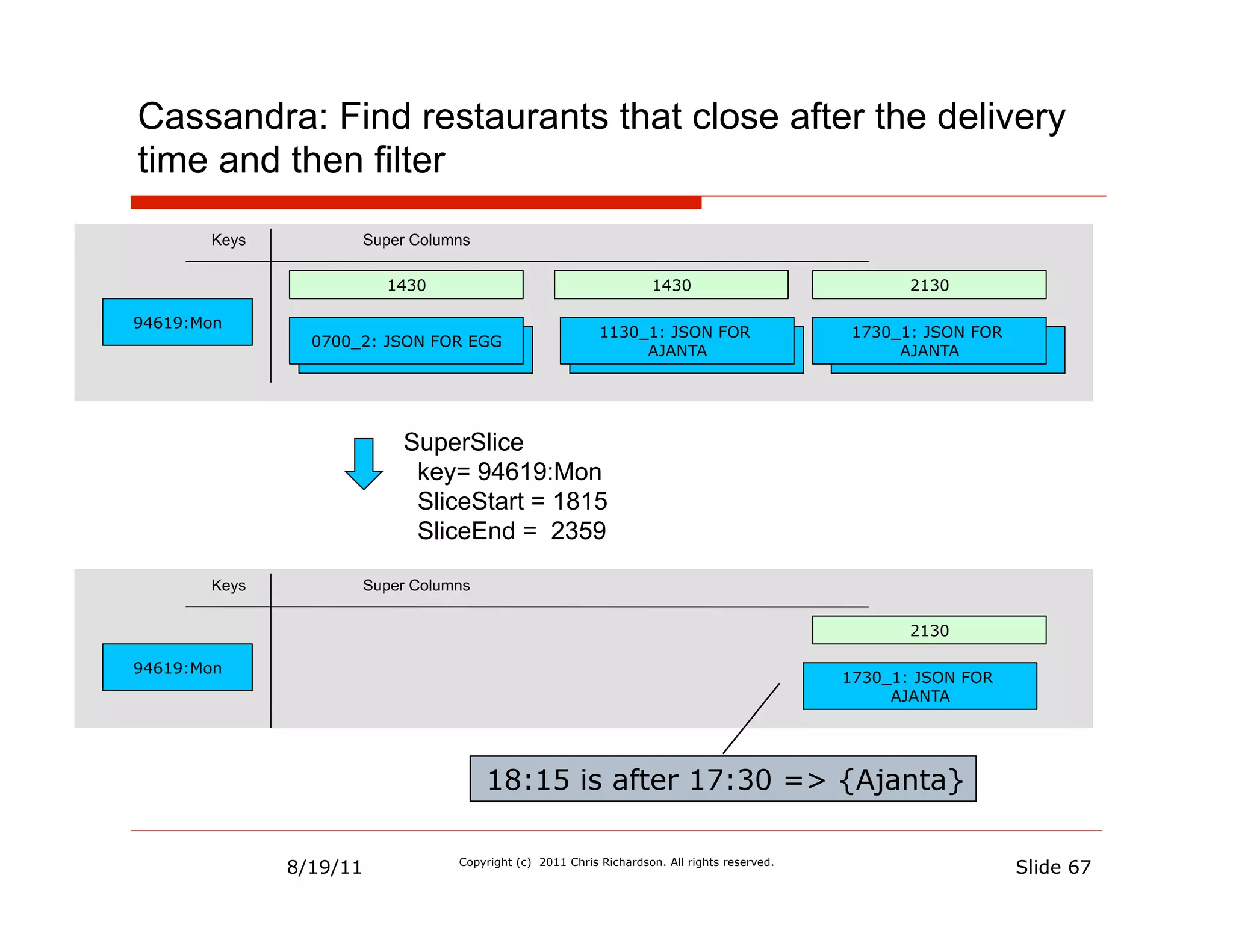
![Sorted sets support range queries
Key Sorted Set [ Entry:Score, …]
94707:Monday [1130_1:1430, 1730_1:2130]
94619:Monday [0700_2:1430, 1130_1:1430, 1730_1:2130]
zipCode:dayOfWeek Member: OpeningTime_RestaurantId
Score: ClosingTime
ZRANGEBYSCORE 94619:Monday 1815 2359
è
{1730_1}
1730 is before 1815 è Ajanta is open
8/19/11 Copyright (c) 2011 Chris Richardson. All rights reserved.
Slide 60](https://image.slidesharecdn.com/polygotpersistenceforjavadevsoakjug2011-110821153343-phpapp02/75/Polygot-persistence-for-Java-Developers-August-2011-Oakjug-60-2048.jpg)






![MongoDB = easy to store
{
"_id": "1234"
"name": "Ajanta",
"serviceArea": ["94619", "99999"],
"openingHours": [
{
"dayOfWeek": 1,
"open": 1130,
"close": 1430
},
{
"dayOfWeek": 2,
"open": 1130,
"close": 1430
},
…
]
}
8/19/11 Copyright (c) 2011 Chris Richardson. All rights reserved.
Slide 69](https://image.slidesharecdn.com/polygotpersistenceforjavadevsoakjug2011-110821153343-phpapp02/75/Polygot-persistence-for-Java-Developers-August-2011-Oakjug-69-2048.jpg)






This presentation by Chris Richardson discusses the challenges and opportunities Java developers face when transitioning to NoSQL databases, highlighting the limitations of traditional relational databases such as schema evolution and scaling issues. It explores various NoSQL solutions like Redis, Cassandra, and MongoDB, detailing their unique features, advantages, and potential downsides. The talk aims to provide insights into how these technologies can facilitate better performance and scalability for modern applications.







































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

