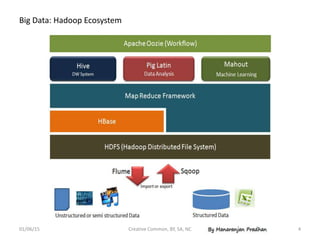
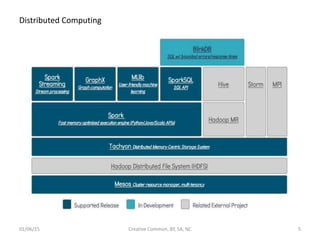
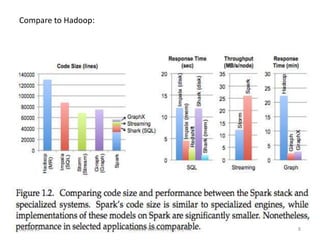
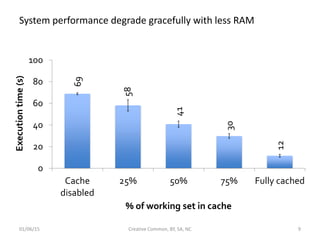
Downloaded 57 times






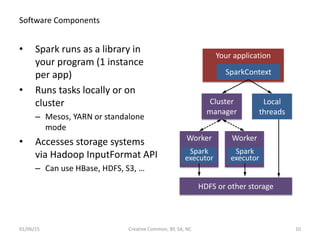
![Spark Architecture
• [Spark
Standalone
• |Mesos
• |Yarn]
Node
Client
01/06/15 Creative Common, BY, SA, NC 11](https://image.slidesharecdn.com/spark20150106f-150105131829-conversion-gate02/85/Spark-Study-Notes-11-320.jpg)

![Fault Recovery
RDDs track the series of transformations used to build
them (their lineage) to re-compute lost data, no data
replication across wire.
val lines = sc.textFile(...)
lines.filter(x => x.contains(“ERROR”)).count()
msgs = textFile.filter(lambda s: s.startsWith(“ERROR”))
.map(lambda s: s.split(“t”)[2])
01/06/15 Creative Common, BY, SA, NC 13
HDFS File Filtered RDD Mapped RDD
filter
(func = startsWith(…))
map
(func = split(...))](https://image.slidesharecdn.com/spark20150106f-150105131829-conversion-gate02/85/Spark-Study-Notes-13-320.jpg)



![Spark Streaming: Word Count
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.storage.StorageLevel
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
01/06/15 Creative Common, BY, SA, NC 20
Create Spark Context
Create, map, reduce
Output
Start](https://image.slidesharecdn.com/spark20150106f-150105131829-conversion-gate02/85/Spark-Study-Notes-20-320.jpg)
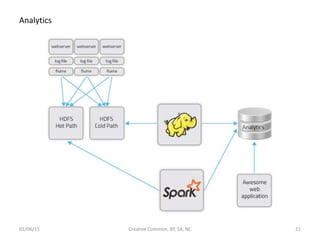




This document discusses Apache Spark, an open-source cluster computing framework. It provides an overview of Spark, including its main concepts like RDDs (Resilient Distributed Datasets) and transformations. Spark is presented as a faster alternative to Hadoop for iterative jobs and machine learning through its ability to keep data in-memory. Example code is shown for Spark's programming model in Scala and Python. The document concludes that Spark offers a rich API to make data analytics fast, achieving speedups of up to 100x over Hadoop in real applications.
































































































