Downloaded 467 times





![{"schema": {
The Mixer Word Count "type": "record",
"name": "WordCount",
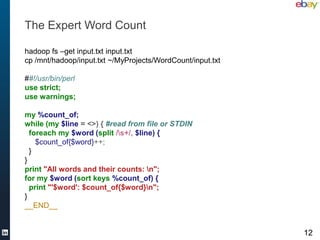
#wordcount.py "fields": [
from org.apache.pig.scripting import * {
"name": "word",
@outputSchema("b: bag{ w: chararray}") "type": "string"
def tokenize(words): },
return words.split(" ") {
"name": "count",
script = """ "type": "int"
A = load './input.txt'; }]}}
B = foreach A generate flatten(tokenize((chararray)$0)) as word;
C = group B by word;
D = foreach C generate group, COUNT(B);
store D into './wordcount’ using AvroStorage("schema");
"""
Pig.compile(script).bind().runSingle()
8](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-8-320.jpg)





![The Craftsman Word Count
package org.myorg; public static class Reduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
import java.io.IOException;
import java.util.*; public void reduce(Text key, Iterable<IntWritable> values, Context
context)
throws IOException, InterruptedException {
import org.apache.hadoop.fs.Path;
int sum = 0;
import org.apache.hadoop.conf.*;
for (IntWritable val : values) {
import org.apache.hadoop.io.*;
sum += val.get();
import org.apache.hadoop.mapreduce.*;
}
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
context.write(key, new IntWritable(sum));
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
}
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
}
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public static void main(String[] args) throws Exception {
public class WordCount {
Configuration conf = new Configuration();
public static class Map extends Mapper<LongWritable, Text, Text,
IntWritable> { Job job = new Job(conf, "wordcount");
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { job.setMapperClass(Map.class);
String line = value.toString(); job.setReducerClass(Reduce.class);
StringTokenizer tokenizer = new StringTokenizer(line); job.setInputFormatClass(TextInputFormat.class);
while (tokenizer.hasMoreTokens()) { job.setOutputFormatClass(TextOutputFormat.class);
word.set(tokenizer.nextToken()); FileInputFormat.addInputPath(job, new Path(args[0]));
context.write(word, one); FileOutputFormat.setOutputPath(job, new Path(args[1]));
}
} job.waitForCompletion(true);
} }
15](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-15-320.jpg)





![Agility – Try before you buy
scala> 1 to 10
res0: Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> 1 until 10
res1: Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)
scala> res0.slice(3, 5)
res3: scala.collection.immutable.IndexedSeq[Int] = Vector(4, 5)
scala> res0.groupBy(_ % 2)
res4: Map[Int, IndexedSeq[Int]] =
Map(1 -> Vector(1, 3, 5, 7, 9), 0 -> Vector(2, 4, 6, 8, 10))
21](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-21-320.jpg)




![Simplicity
Paco Nathan, Evil Mad Scientist, Concurrent Inc., @pacoid, says:
– “[Scalding] code is compact, simple to understand”
– “nearly 1:1 between elements of conceptual flow diagram and function
calls”
– “Cascalog and Scalding DSLs leverage the functional aspects of
MapReduce, helping to limit complexity in process”
Scala is a functional tool for a fundamentally functional job
26](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-26-320.jpg)

![Let’s count some words
This is the “Hello, World!” of anything tangentially related to
Hadoop.
Let’s try it in Scala first without any Hadoop stuff.
val myLines : Seq[String] = ... // get some stuff
val myWords = myLines.flatMap(w => w.split("s+"))
val myWordsGrouped = myWords.groupBy(identity)
val countedWords = myWordsGrouped.mapValues(x=>x.size)
Now write out the words somehow
val countedWords = myLines.flatMap(_.split("s+"))
.groupBy(identity)
.mapValues(_.size)
28](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-28-320.jpg)
![Let’s count a lot of words
I’ve gone to the trouble of rewriting this example to run in Hadoop.
Here it is:
val myLines : TypedPipe[String] = TextLine(args("input"))
val myWords = myLines.flatMap(w => w.split("s+"))
val myWordsGrouped = myWords.groupBy(identity)
val countedWords = myWordsGrouped.mapValueStream(x =>
Iterator(x.size))
We can make this even better.
val countedWords = myWordsGrouped.size
countedWords.write(TypedTsv[(String,Long)](output))
29](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-29-320.jpg)



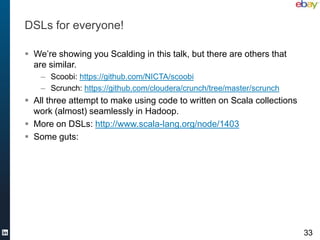

![Typed DSL
From com.twitter.scalding.TDsl
/** implicits for the type-safe DSL
* import TDsl._ to get the implicit conversions from
Grouping/CoGrouping to Pipe,
* to get the .toTypedPipe method on standard cascading Pipes.
* to get automatic conversion of Mappable[T] to TypedPipe[T]
*/
object TDsl extends Serializable with GeneratedTupleAdders {
implicit def pipeTExtensions(pipe : Pipe) : PipeTExtensions = new
PipeTExtensions(pipe)
implicit def mappableToTypedPipe[T](mappable : Mappable[T])
(implicit flowDef : FlowDef, mode : Mode, conv :
TupleConverter[T]) : TypedPipe[T] = {
TypedPipe.from(mappable)(flowDef, mode, conv)
}
}
35](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-35-320.jpg)
![Algebird – It’s like algebra and a bird
We did something fancy in the previous example:
val countedWords = myGroupedWords.size
val countedWords = myGroupedWords.mapValues(x =>
1L).sum
val countedWords = myGroupedWords.mapValues(x =>
1L).reduce(implicit mon: Monoid[Long])((l,r) => mon.plus(l,r))
Scalding uses Algebird extensively to make your life easier.
Algebird can also be used outside of Scalding with no trouble.
Algebird has your favorite things like monoids, monads, bloom
filters, count-min sketches, hyperloglogs, etc.
36](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-36-320.jpg)

![More code
case class MyAvroOutput(word: String, count: Long,
entropy: Double) extends AvroRecord
TypedTsv[(String,Int)]
.flatMap{case(line,cat) => line.split("s+").map(x =>
(x,Map(cat->1L))}
.group
.sum
.map{ case(word, dist) =>
val total: Double = dist.values.sum
val entropy = (-1)*dist.values.map{ count =>
(count/total)*math.log(count/total)}.sum
MyAvroOutput(word,total.toLong,entropy)
}
.write(PackedAvroSource[MyAvroOutput](output))
Math is great
38](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-38-320.jpg)




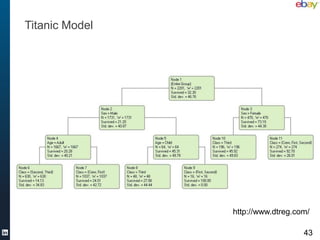
![Classifier code
object Titanic {
def main(args: Array[String]) = {
// parse data
val reader = new CSVReader(new FileReader(
"src/main/data/titanic.csv"))
val passengers = reader.readAll.tail.map(Passenger(_))
val instances = passengers.map(_.getInstance).toSet
// build tree
val treeBuilder = new TreeBuilder
val tree = treeBuilder.buildTree(instances)
// print tree
tree.dump(System.out)
}
}
44](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-44-320.jpg)
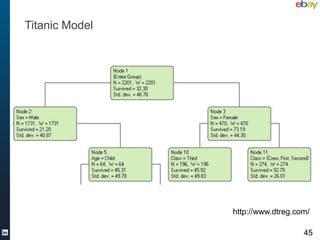



![Let’s use Mahout, inside Scalding
lazy val clust = new StreamingKMeans(new FastProjectionSearch(new
EuclideanDistanceMeasure,5,10),
args("sloppyclusters").toInt, (10e-6).asInstanceOf[Float])
var count = 0;
val sloppyClusters =
TextLine(args("input"))
.map{ str =>
val vec = str.split("t").map(_.toDouble)
val cent = new Centroid(count, new DenseVector(vec))
count += 1
cent
}
.toPipe('centroids)
// This won't work with the current build, coming soon though
.unorderedFoldTo[StreamingKMeans,Centroid]('centroids->’clusters)(clust){(cl,cent) =>
cl.cluster(cent); cl}
.toTypedPipe[StreamingKMeans](Dsl.intFields(Seq(0)))
.flatMap(c => c.iterator.asScala.toIterable)
49](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-49-320.jpg)
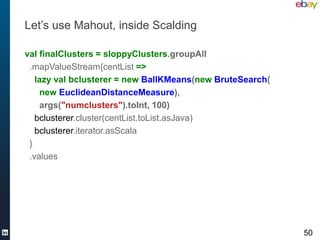





.filter(_.skill == "Scala")
.map(e => (e.sender, e.recipient, 1))
.write(TSV(”edges"))
}
def getDominantEigenVector = { … } // outputs to “ranks” (memberId, rank)
def getMembers = {
// get Bay Area members
val members = readLatest[Member]("members")
.filter(_.getRegionCode == 84)
.groupBy(_.getMemberId.toLong)
// join ranks and members
readFile[Ranks](”ranks”).withReducers(10).join(members).toTypedPipe
.map{ case (id, ((_, rank), m)) =>
(rank, m.getMemberId, m.getFirstName, m.getLastName, m.getHeadline) }
.groupAll.sortBy(_._1).reverse.values
.write(TextLine("talk/scalaRanks"))
} 56](https://image.slidesharecdn.com/basemeetup-final-130312160738-phpapp01/85/Scalable-and-Flexible-Machine-Learning-With-Scala-LinkedIn-56-320.jpg)

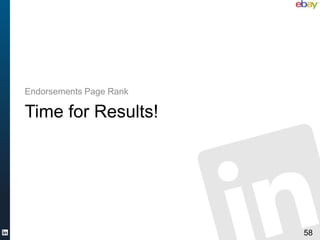
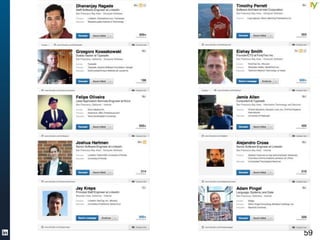




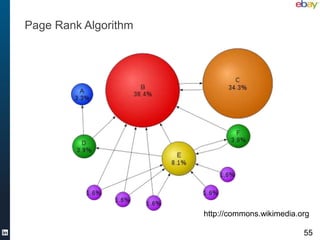
The document discusses various aspects of scalable machine learning using Scala, emphasizing its advantages over traditional options like Pig and Java MapReduce. It highlights the importance of clean data and presents practical examples, such as word counting and classification tasks, using libraries like Scalding and Mahout. Ultimately, it advocates for a pragmatic, productive approach to data science that emphasizes agility, correctness, scalability, and simplicity.


![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)