Downloaded 30 times








![SELECT SUM(price) as prices, SUM(cost) as costs, prices-costs, margin/price
FROM Balance
VS
function (key, values) {
var price = 0.0, cost = 0.0, margin = 0.0, marginPercent = 0.0;
for (var i = 0; i < values.length; i++) {
price += values[i].price;
cost += values[i].cost;
}
margin = price - cost;
marginPercent = margin / price;
return {
price: price,
cost: cost,
margin: margin,
marginPercent: marginPercent
};
}
www.orientechnologies.com](https://image.slidesharecdn.com/orientdbthegraphdatabase1-2-120522145308-phpapp02/75/OrientDB-the-graph-database-9-2048.jpg)



![Native
{
JSON
'@rid' = '26:10',
'@class' = 'Developer',
'name' : 'Luca',
'surname' : 'Garulli',
'out' : [ #10:33, #10:232 ]
}
www.orientechnologies.com](https://image.slidesharecdn.com/orientdbthegraphdatabase1-2-120522145308-phpapp02/75/OrientDB-the-graph-database-13-2048.jpg)











![Fetch plans
Load only the root vertex
Vertex = *:1
Luca
|
| lives city
+---------> Vertex ------------> Vertex
| 10th street Italy
| knows
+--------->* [Vertex Vertex Vertex ]
[ Marko John Nicholas]
www.orientechnologies.com](https://image.slidesharecdn.com/orientdbthegraphdatabase1-2-120522145308-phpapp02/75/OrientDB-the-graph-database-39-2048.jpg)
![Fetch plans
Load root + address
Vertex = *:1 lives:2
Luca
|
| lives city
+---------> Vertex ------------> Vertex
| 10th street Italy
| knows
+--------->* [Vertex Vertex Vertex ]
[ Marko John Nicholas]
www.orientechnologies.com](https://image.slidesharecdn.com/orientdbthegraphdatabase1-2-120522145308-phpapp02/75/OrientDB-the-graph-database-40-2048.jpg)
![Fetch plans
Load root + all known
Vertex = *:1 knows:1
Luca
|
| lives city
+---------> Vertex ------------> Vertex
| 10th street Italy
| knows
+--------->* [Vertex Vertex Vertex ]
[ Marko John Nicholas]
www.orientechnologies.com](https://image.slidesharecdn.com/orientdbthegraphdatabase1-2-120522145308-phpapp02/75/OrientDB-the-graph-database-41-2048.jpg)
![Fetch plans
Load up 3rd level of depth
Vertex = *:3
Luca
|
| lives city
+---------> Vertex ------------> Vertex
| 10th street Italy
| knows
+--------->* [Vertex Vertex Vertex ]
[ Marko John Nicholas]
www.orientechnologies.com](https://image.slidesharecdn.com/orientdbthegraphdatabase1-2-120522145308-phpapp02/75/OrientDB-the-graph-database-42-2048.jpg)
![Console
ORIENT database v.1.0.0 www.orientechnologies.com
Type 'help' to display all the commands supported.
> connect remote:localhost/demo admin admin
Connecting to database [remote:localhost/demo] with user 'admin'...OK
> select from profile where nick.startsWith('L')
---+--------+--------------------+--------------------+--------------------+
#| REC ID |NICK |SEX |AGE |
---+--------+--------------------+--------------------+--------------------+
0| 10:0|Lvca |male |34
1| 10:3|Leo |male |22
2| 10:7|Luisa |female |27
3 item(s) found. Query executed in 0.013 sec(s).
> close
Disconnecting from the database [demo]...OK
> quit
www.orientechnologies.com](https://image.slidesharecdn.com/orientdbthegraphdatabase1-2-120522145308-phpapp02/75/OrientDB-the-graph-database-43-2048.jpg)




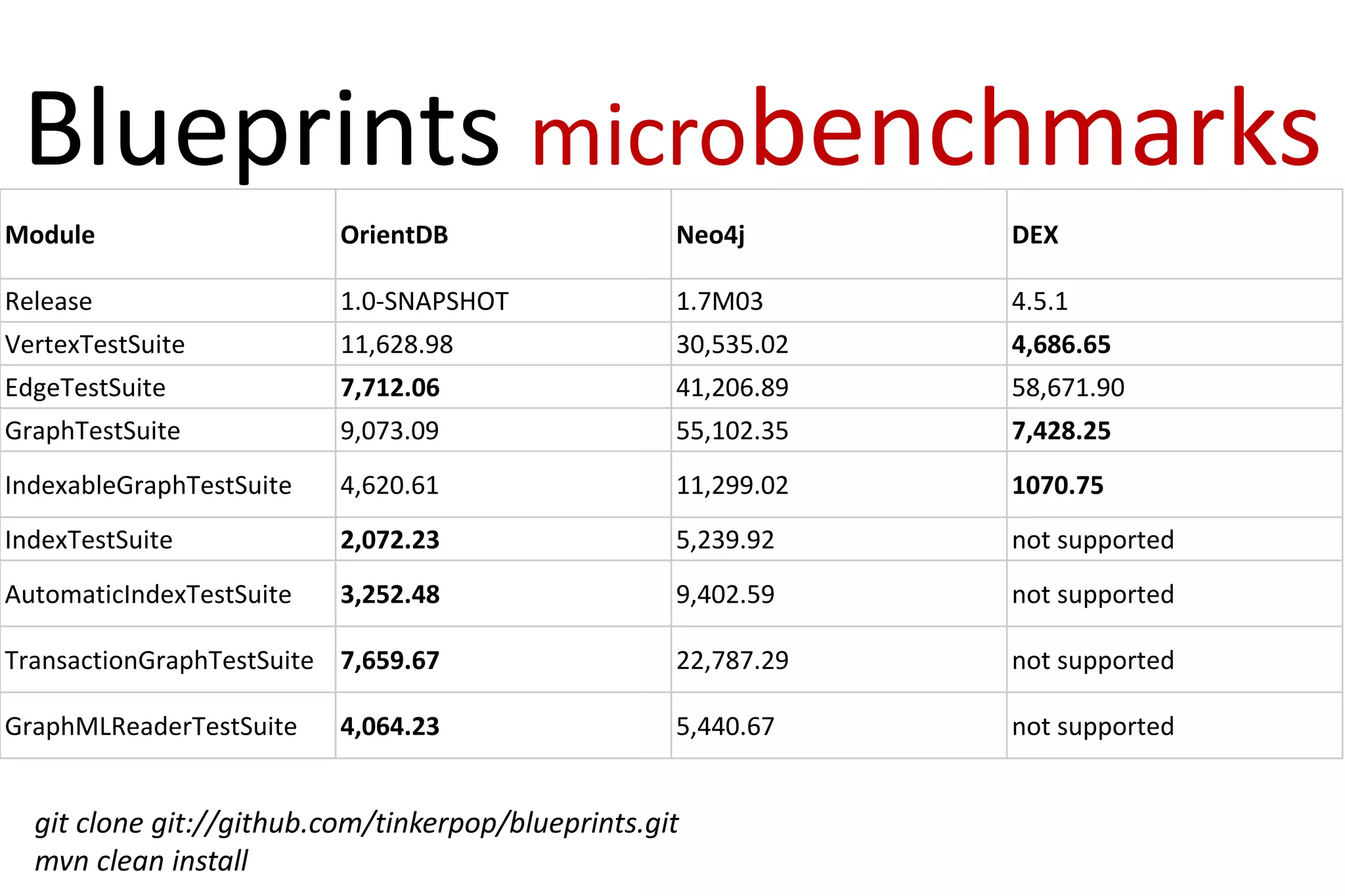





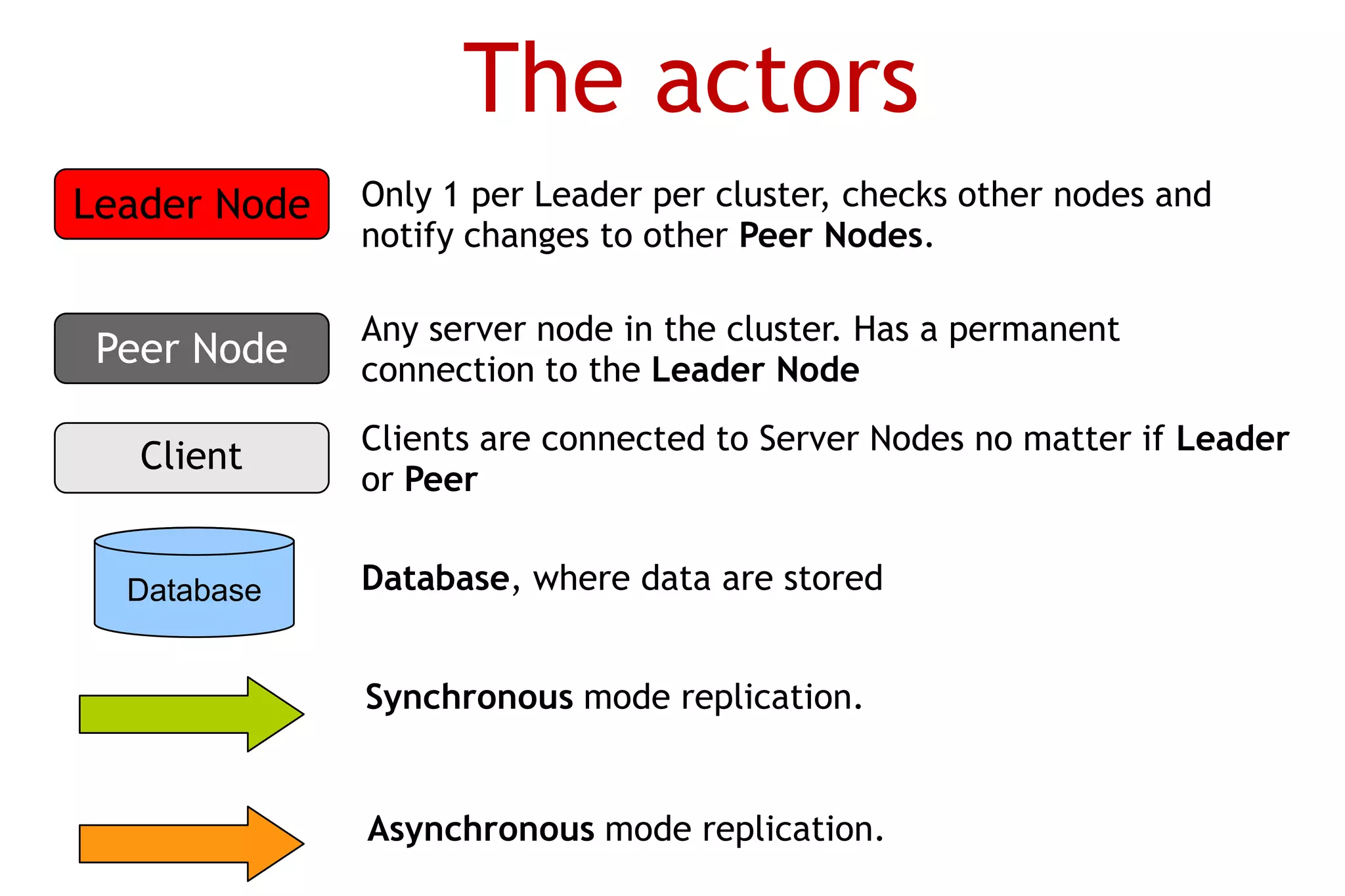
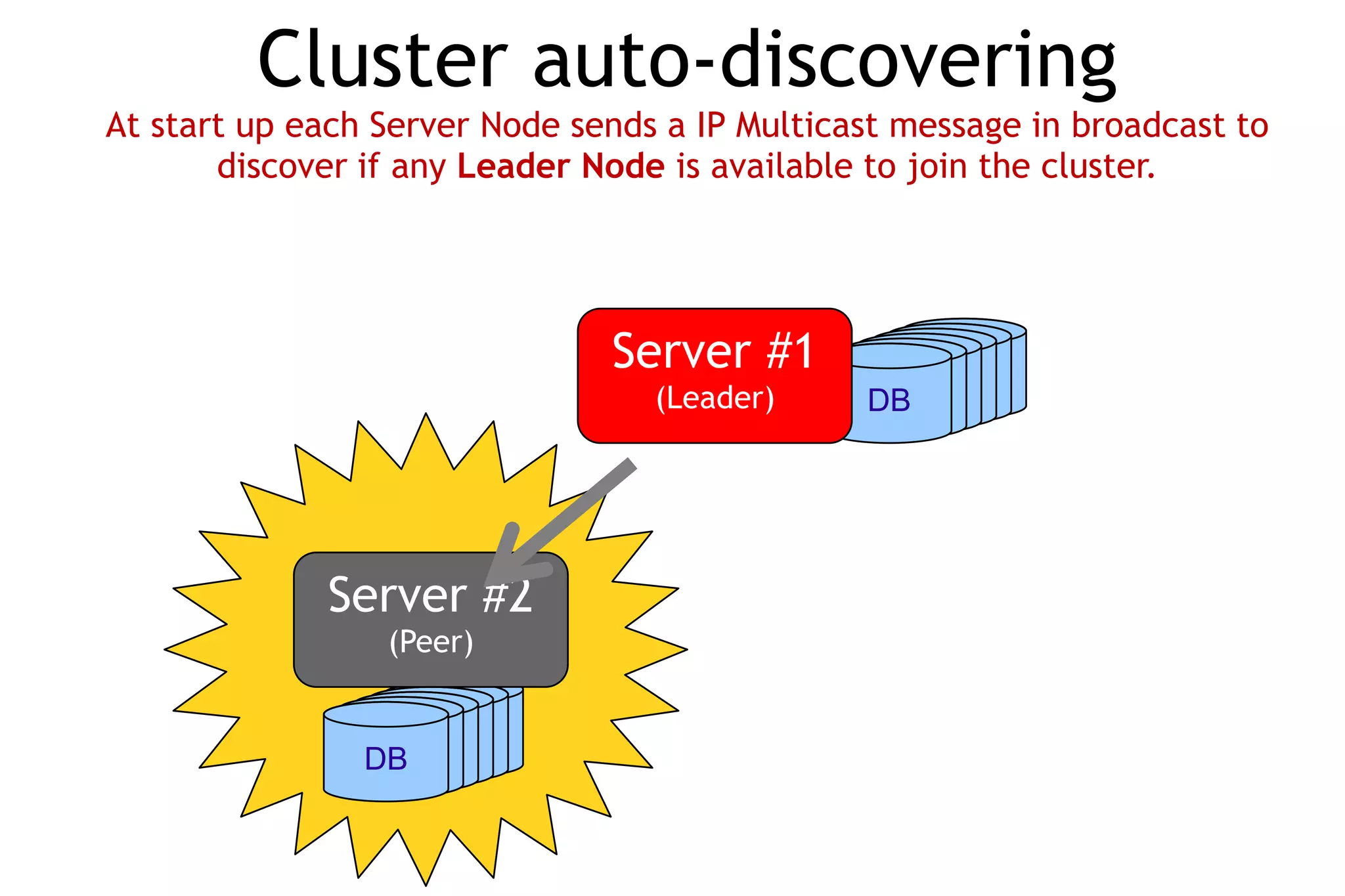
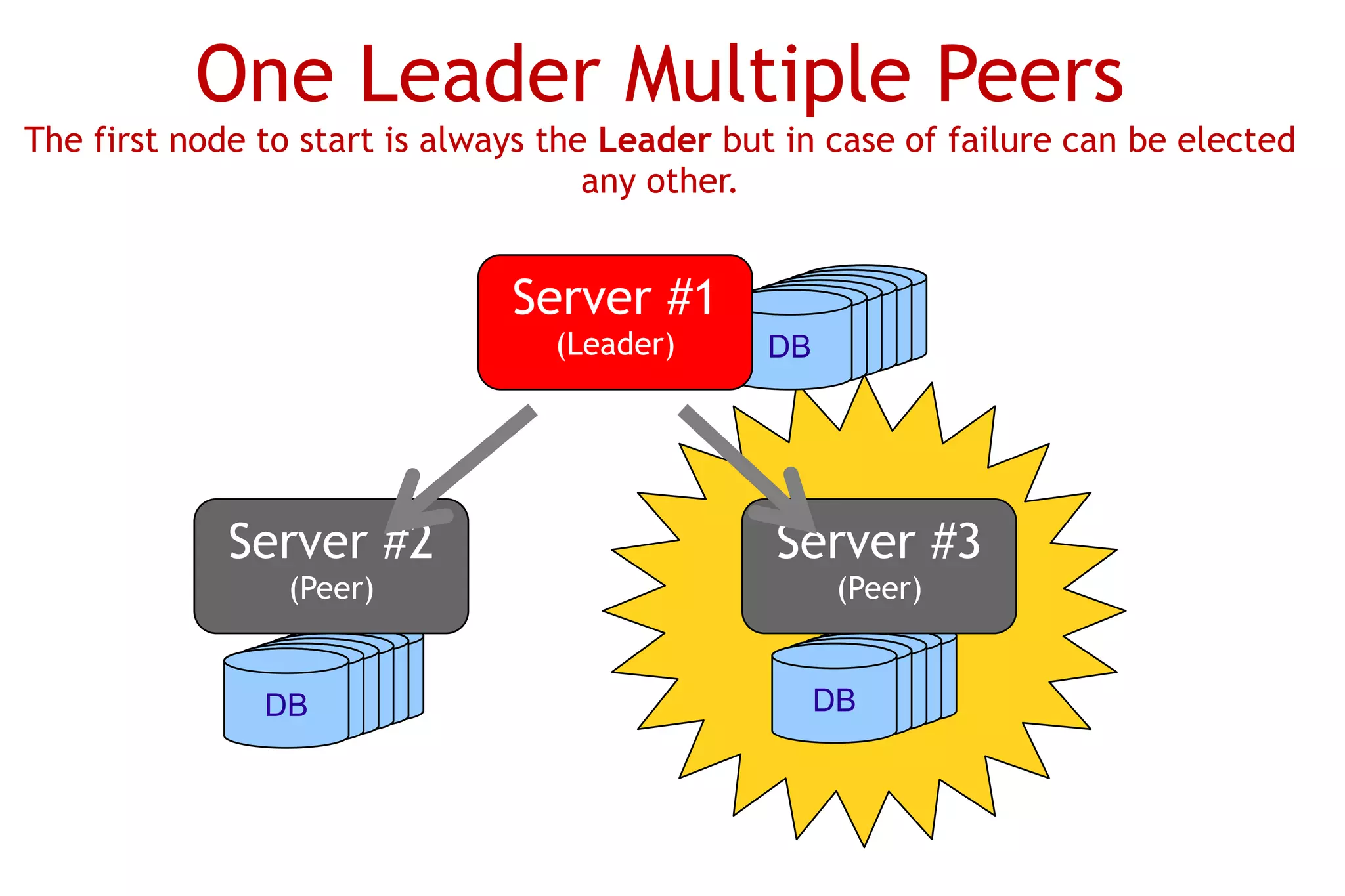
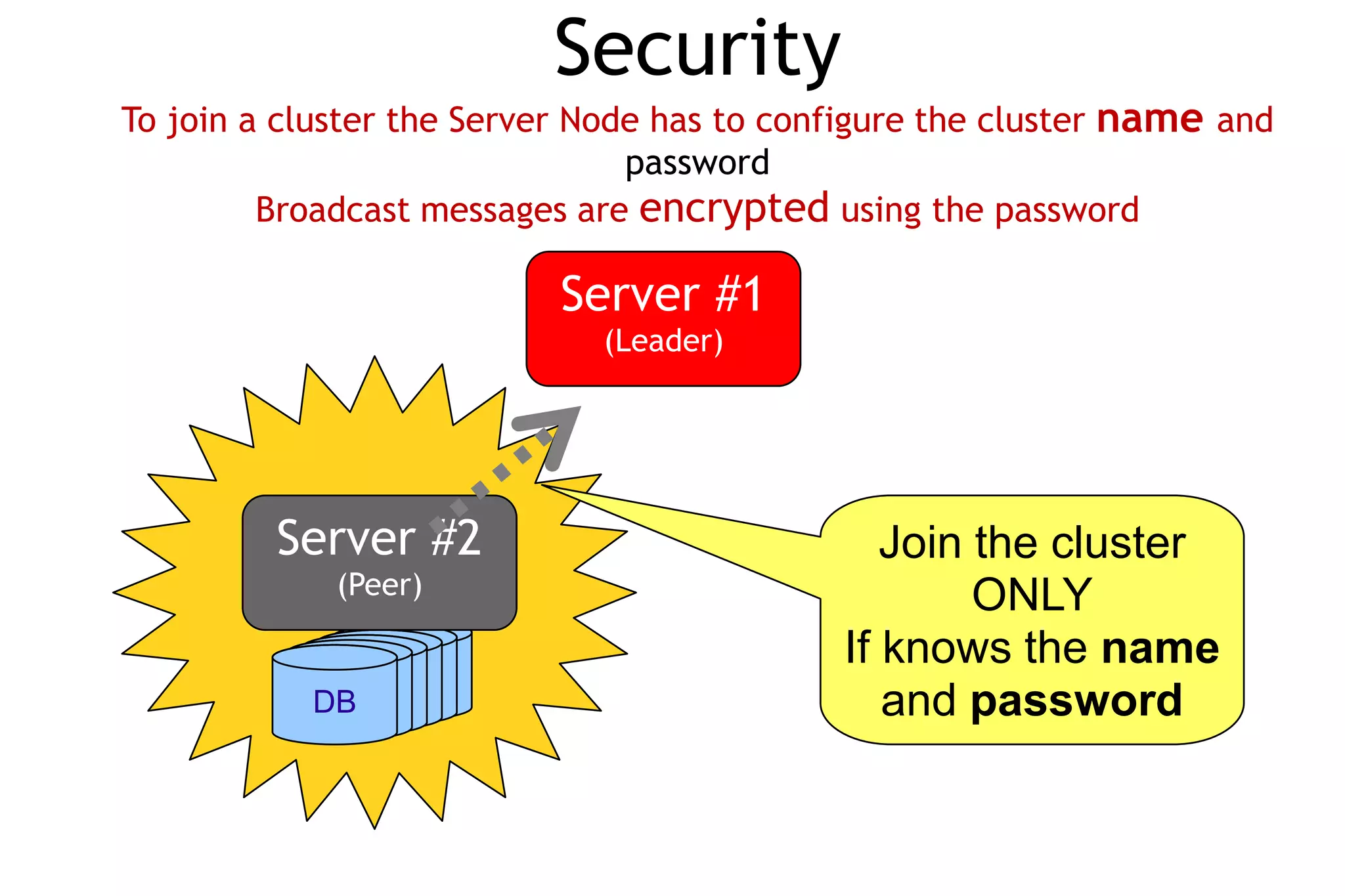
The document discusses OrientDB, a multi-model NoSQL database that supports document, key-value, and graph structures. It highlights several of OrientDB's features, including its support for relationships without joins, complex types, ACID transactions, and its RESTful HTTP interface. The document also briefly describes OrientDB's indexing, security, multi-master replication, and use of a graph database model.

































![Biomolekul 1[1]](https://cdn.slidesharecdn.com/ss_thumbnails/biomolekul-11-150905162241-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)






































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








