Downloaded 1,340 times








































This document discusses various aspects of file systems including: 1. It defines what a file is and lists some common file attributes like name, size, and timestamps. 2. It describes different file operations like create, read, write, delete and different methods to access and store files like sequential, random, and index access. 3. It discusses file system implementation techniques like contiguous allocation, linked lists, and i-nodes and how free space is managed through approaches like bitmaps and linked lists.
Storing information long-term is crucial for accessibility and sharing among processes. Large data requires appropriate storage devices.
A file consists of logical records (bits/bytes) with attributes like name, type, location, size, creation date, etc.
File naming comprises the file name and extension (e.g., Student.doc where 'Student' is the name and 'doc' is the extension).
Overview of common file extensions used for various file types.
Files possess attributes including name, data, creation date, and current size.
Operations on files include CREATE, DELETE, OPEN, CLOSE, READ, WRITE, APPEND, and RENAME.
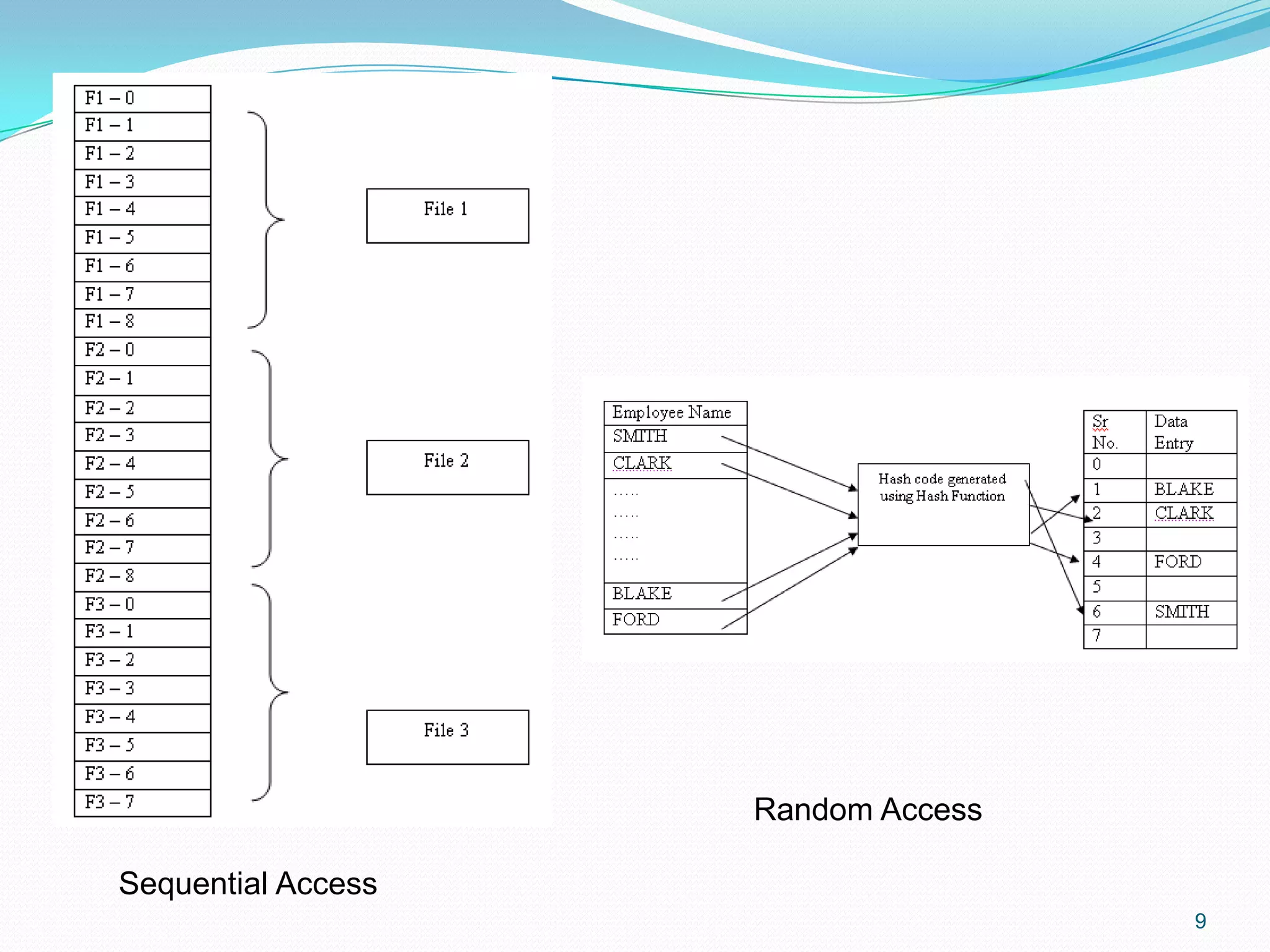
Data retrieval methods include Sequential Access (records in store order) and Random Access (direct address search).
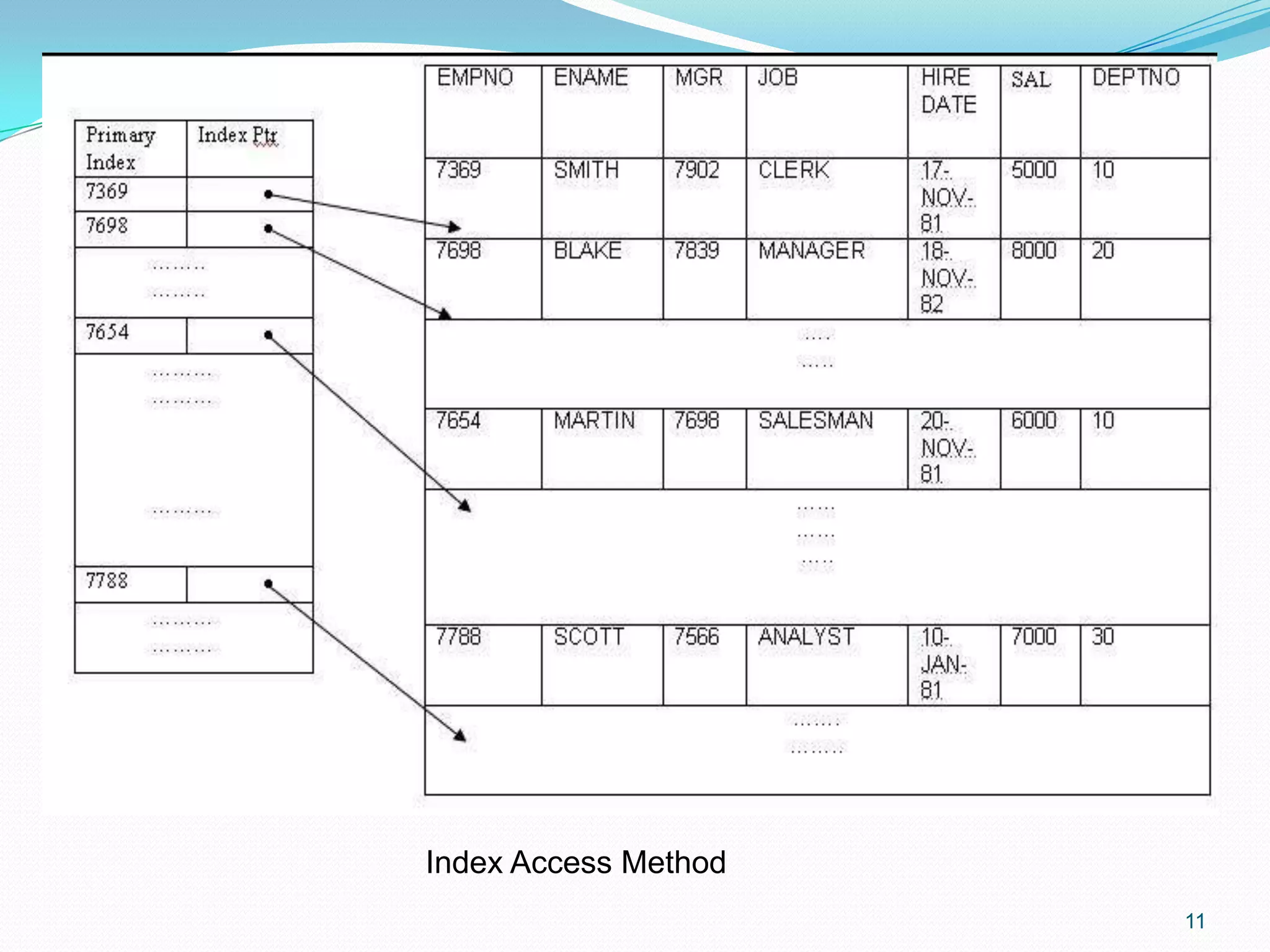
An indexed file uses keys associated with fields for query efficiency, enhancing data retrieval.
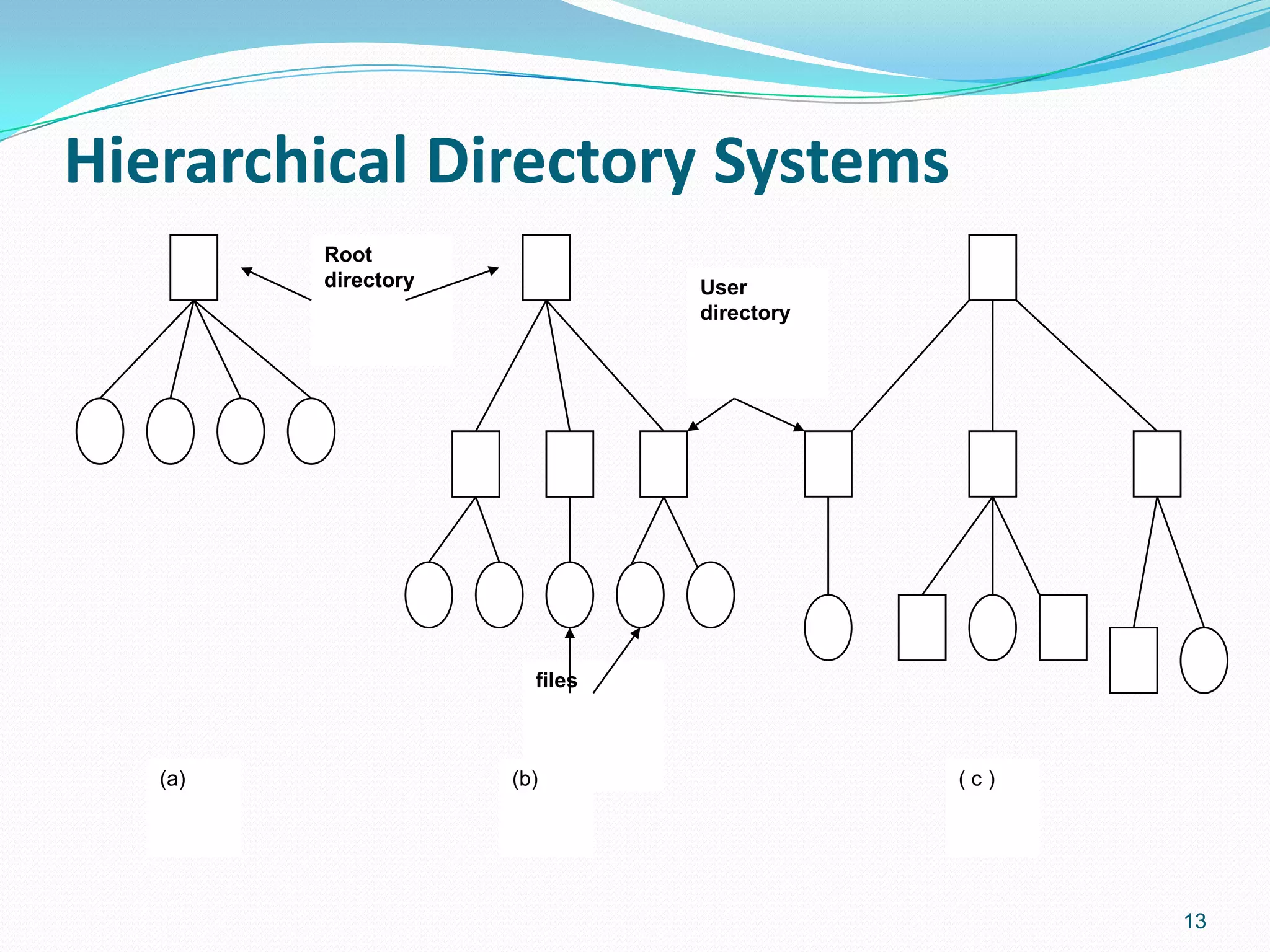
Directories group files and provide a structure for accessing them.
Hierarchical systems organize directories, with a root directory containing user directories.
Absolute path specifies full directories to the file, while relative path uses the current working directory.
Directory management includes creating, deleting, opening, closing, and renaming directories.
Protecting file systems from unauthorized access is vital for safeguarding valuable information.
Access control for file operations is crucial, including user classification (Owner, Group, Universe) and password protection.
Four implementation methods include Contiguous allocation, Linked list allocation, Indexed allocation, and I-nodes.
Four techniques for managing free disk space: Bit map, Linked list, Grouping, and Counting.
Security involves protecting against data theft, unauthorized modifications, and destruction; can be physical or human-related.
Authentication involves user IDs, passwords, artifacts, and biometric techniques for verifying identities.
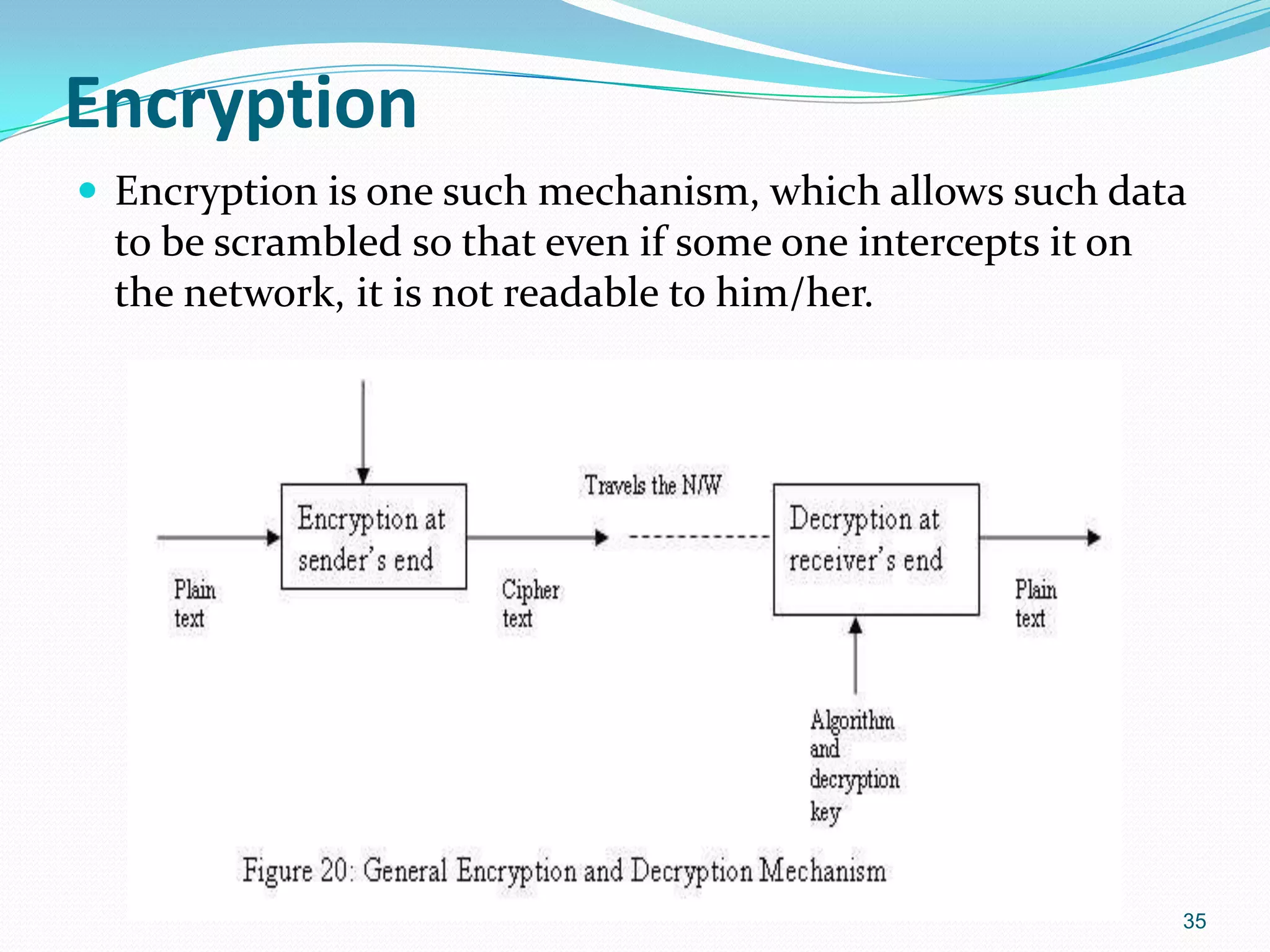
Encryption safeguards data in transit through Symmetric and Asymmetric methods for secure communication.
Types of malware include viruses, worms, and Trojan horses, each with distinct methods and impacts.
Threat monitoring involves tracking incorrect password attempts, maintaining audit logs, scanning for security holes, and firewall use.
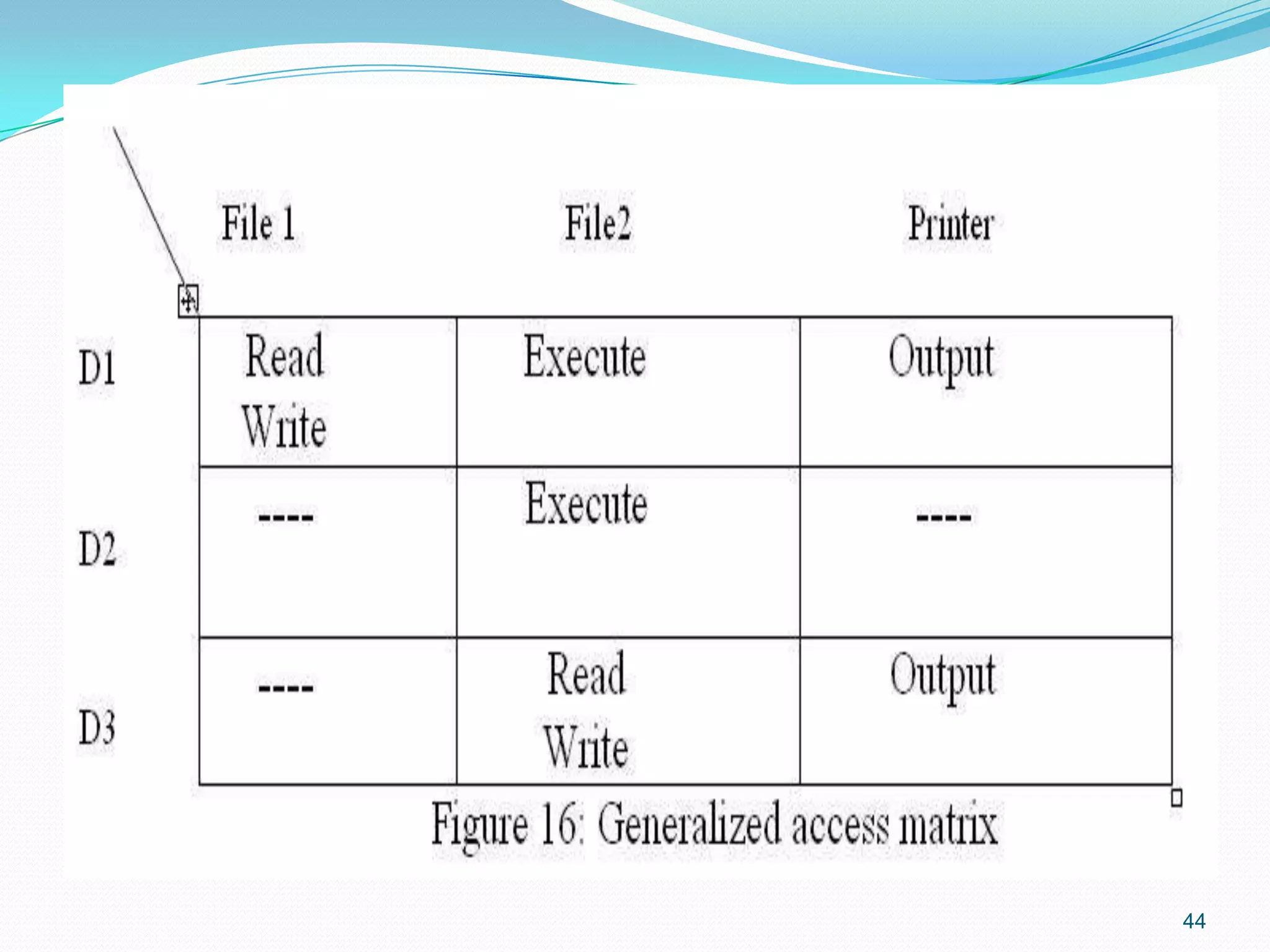
Protection focuses on regulating access to system resources by programs, processes, and users.
Enforcement methods for resource protection include Access rights (defining operations) and Access matrix (user-resource permissions).























































































