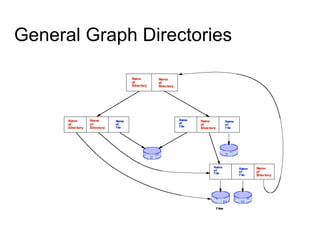
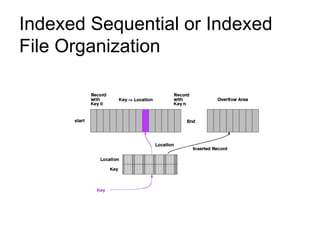
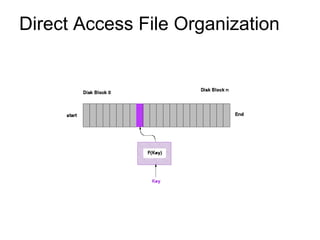
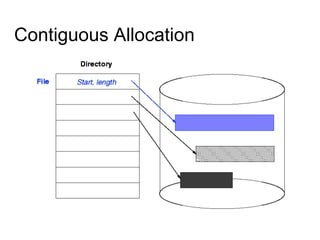
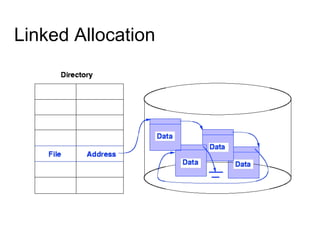
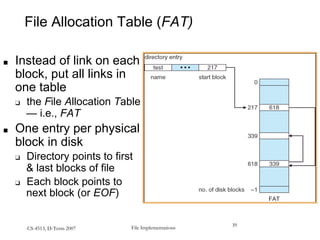
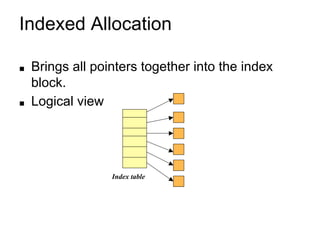
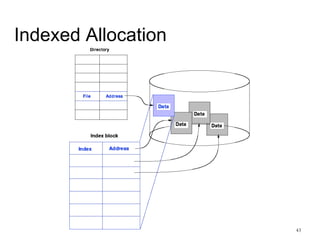
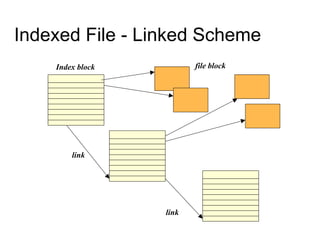
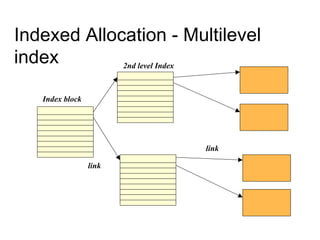
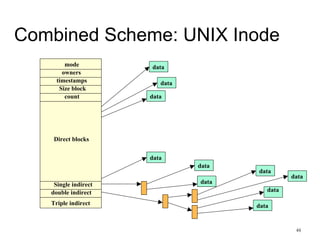
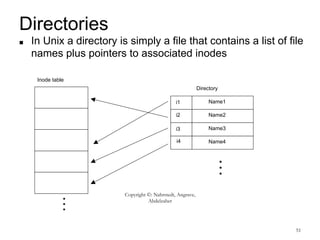
This document provides an overview of file systems and their implementation in operating systems. It discusses key concepts like file structure, attributes, operations, directory structures including tree and graph organizations, allocation methods like contiguous, linked and indexed, access methods, protection, and efficiency techniques. The document also describes UNIX inodes which combine different allocation schemes and provide metadata for files.



































![Free Space Management
■ Bit Vector (n blocks) - bit map of free blocks
■ Block number calculation
(number of bits per word) *
(number of 0-value words) +
offset of 1st bit
■ Bit map requires extra space.
❑ Eg. Block size = 2^12 bytes, Disk size = 2^30 bytes
n = 2^30/2^12 = 2^18 bits ( or 32K bytes)
■ Easy to get contiguous files
■ Example: BSD File system
bit[i] =
0 1 2 n-1
0 implies block[i] occupied
1 implies block[i] free
{](https://image.slidesharecdn.com/oslectureset7-221109060638-fd45c0c1/85/oslectureset7-pdf-52-320.jpg)

![Free Space Management
■ Need to protect
■ pointer to free list
■ Bit map
❑ Must be kept on disk
❑ Copy in memory and disk may differ.
❑ Cannot allow for block[i] to have a situation where bit[i] = 1
in memory and bit[i] = 0 on disk
■ Solution
❑ Set bit[i] = 1 in disk
❑ Allocate block[i]
❑ Set bit[i] = 1 in memory.](https://image.slidesharecdn.com/oslectureset7-221109060638-fd45c0c1/85/oslectureset7-pdf-54-320.jpg)


















































