Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Ken Urano
PDF, PPTX
55,698 views
有意性と効果量について しっかり考えてみよう
外国語教育メディア学会第53回 全国研究大会ワークショップ 2013.08.07.
Education
◦
Read more
36
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 84
2
/ 84
3
/ 84
4
/ 84
5
/ 84
6
/ 84
7
/ 84
8
/ 84
9
/ 84
10
/ 84
11
/ 84
12
/ 84
13
/ 84
14
/ 84
15
/ 84
16
/ 84
17
/ 84
18
/ 84
19
/ 84
20
/ 84
21
/ 84
22
/ 84
23
/ 84
24
/ 84
25
/ 84
26
/ 84
27
/ 84
28
/ 84
29
/ 84
30
/ 84
31
/ 84
32
/ 84
33
/ 84
34
/ 84
35
/ 84
36
/ 84
37
/ 84
38
/ 84
39
/ 84
40
/ 84
41
/ 84
42
/ 84
43
/ 84
44
/ 84
45
/ 84
46
/ 84
47
/ 84
48
/ 84
49
/ 84
50
/ 84
51
/ 84
52
/ 84
53
/ 84
54
/ 84
55
/ 84
56
/ 84
57
/ 84
58
/ 84
59
/ 84
60
/ 84
61
/ 84
62
/ 84
63
/ 84
64
/ 84
65
/ 84
66
/ 84
67
/ 84
68
/ 84
69
/ 84
70
/ 84
71
/ 84
72
/ 84
73
/ 84
74
/ 84
75
/ 84
76
/ 84
77
/ 84
78
/ 84
79
/ 84
80
/ 84
81
/ 84
82
/ 84
83
/ 84
84
/ 84
More Related Content
PPTX
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
PDF
潜在クラス分析
by
Yoshitake Takebayashi
PPTX
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
PDF
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
PDF
1 4.回帰分析と分散分析
by
logics-of-blue
PDF
統計的学習の基礎 5章前半(~5.6)
by
Kota Mori
PPTX
重回帰分析で交互作用効果
by
Makoto Hirakawa
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
潜在クラス分析
by
Yoshitake Takebayashi
GEE(一般化推定方程式)の理論
by
Koichiro Gibo
因果探索: 基本から最近の発展までを概説
by
Shiga University, RIKEN
1 4.回帰分析と分散分析
by
logics-of-blue
統計的学習の基礎 5章前半(~5.6)
by
Kota Mori
重回帰分析で交互作用効果
by
Makoto Hirakawa
What's hot
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PDF
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
PDF
スペクトラルグラフ理論入門
by
irrrrr
PDF
明日から読めるメタ・アナリシス
by
Yasuyuki Okumura
PDF
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
PDF
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
PDF
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
PDF
多重代入法の書き方 公開用
by
Koichiro Gibo
PPTX
ベイズファクターとモデル選択
by
kazutantan
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
単一事例研究法と統計的推測:ベイズ流アプローチを架け橋として (文字飛び回避版はこちら -> https://www.slideshare.net/yos...
by
Yoshitake Takebayashi
PDF
最適化超入門
by
Takami Sato
PPTX
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PPTX
【解説】 一般逆行列
by
Kenjiro Sugimoto
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
PDF
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」
by
Takashi J OZAKI
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
『バックドア基準の入門』@統数研研究集会
by
takehikoihayashi
スペクトラルグラフ理論入門
by
irrrrr
明日から読めるメタ・アナリシス
by
Yasuyuki Okumura
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
統計的因果推論への招待 -因果構造探索を中心に-
by
Shiga University, RIKEN
多重代入法の書き方 公開用
by
Koichiro Gibo
ベイズファクターとモデル選択
by
kazutantan
階層ベイズとWAIC
by
Hiroshi Shimizu
単一事例研究法と統計的推測:ベイズ流アプローチを架け橋として (文字飛び回避版はこちら -> https://www.slideshare.net/yos...
by
Yoshitake Takebayashi
最適化超入門
by
Takami Sato
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展
by
Shiga University, RIKEN
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
【解説】 一般逆行列
by
Kenjiro Sugimoto
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
20180118 一般化線形モデル(glm)
by
Masakazu Shinoda
星野「調査観察データの統計科学」第3章
by
Shuyo Nakatani
Similar to 有意性と効果量について しっかり考えてみよう
PDF
20170225_Sample size determination
by
Takanori Hiroe
PDF
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PPTX
T検定と相関分析概要
by
Junko Yamada
PDF
Rm20130515 5key
by
youwatari
PPTX
Darm3(samplesize)
by
Yoshitake Takebayashi
PDF
2013全国英語教育学会WS公開用スライド
by
Mizumoto Atsushi
PDF
傾向スコア:その概念とRによる実装
by
takehikoihayashi
PDF
Rm20140514 5key
by
youwatari
KEY
LS for Reinforcement Learning
by
imlschedules
PDF
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
PDF
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
PDF
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
PDF
2015-1003 英語コーパス学会ワークショップ使用スライド
by
Mizumoto Atsushi
PDF
推計学のすすめ4の2順位相関係数
by
nozma
PDF
Rm20150708 10key
by
youwatari
PDF
第4回DARM勉強会 (多母集団同時分析)
by
Masaru Tokuoka
PDF
JPA2019 Symposium 3
by
Jun Kashihara
PDF
LET関西メソ研20140915公開版
by
youwatari
PDF
社会心理学とGlmm
by
Hiroshi Shimizu
20170225_Sample size determination
by
Takanori Hiroe
星野「調査観察データの統計科学」第1&2章
by
Shuyo Nakatani
一般化線形混合モデル入門の入門
by
Yu Tamura
T検定と相関分析概要
by
Junko Yamada
Rm20130515 5key
by
youwatari
Darm3(samplesize)
by
Yoshitake Takebayashi
2013全国英語教育学会WS公開用スライド
by
Mizumoto Atsushi
傾向スコア:その概念とRによる実装
by
takehikoihayashi
Rm20140514 5key
by
youwatari
LS for Reinforcement Learning
by
imlschedules
第2回DARM勉強会.preacherによるmoderatorの検討
by
Masaru Tokuoka
相関と因果について考える:統計的因果推論、その(不)可能性の中心
by
takehikoihayashi
構造方程式モデルによる因果探索と非ガウス性
by
Shiga University, RIKEN
2015-1003 英語コーパス学会ワークショップ使用スライド
by
Mizumoto Atsushi
推計学のすすめ4の2順位相関係数
by
nozma
Rm20150708 10key
by
youwatari
第4回DARM勉強会 (多母集団同時分析)
by
Masaru Tokuoka
JPA2019 Symposium 3
by
Jun Kashihara
LET関西メソ研20140915公開版
by
youwatari
社会心理学とGlmm
by
Hiroshi Shimizu
More from Ken Urano
PDF
目標言語を使った外国語の授業: 効果的なインプット・インタラクション・フィードバック
by
Ken Urano
PDF
Task-based syllabus design and task sequencing
by
Ken Urano
PDF
TBLT in Japan: In search of the middle ground
by
Ken Urano
PDF
Types of L2 morphosyntactic knowledge that can and cannot be observed in lea...
by
Ken Urano
PDF
ESPカリキュラム開発のためのタスクに基づいたニーズ分析
by
Ken Urano
PDF
英語授業を見つめ直す方法: テストデータの見方を知ろう
by
Ken Urano
PDF
研究会をひとりでも多くに届ける: ライブ中継や資料共有の方法
by
Ken Urano
PDF
タスクを中心にした英語教育は日本で実現可能か—大学におけるライティング授業の事例—
by
Ken Urano
PDF
英語オーラル系授業の教室外活動での PoodLLの利用
by
Ken Urano
PDF
目的に応じたLMSプラットフォームの選択と利用: 何ができるかではなく何をすべきかを考える
by
Ken Urano
PDF
英語教育研究における追試(replication)の必要性
by
Ken Urano
PDF
大学の英語ライティング授業における TBLTの導入
by
Ken Urano
PDF
Input, interaction, and the roles of Japanese teachers of English: A second l...
by
Ken Urano
PDF
英語教育実践と研究の接点 ―研究の在り方と手法―
by
Ken Urano
PDF
大学でのオーラル系授業における Glexa の導入
by
Ken Urano
PDF
Roles of assistant language teachers and Japanese teachers of English for a s...
by
Ken Urano
目標言語を使った外国語の授業: 効果的なインプット・インタラクション・フィードバック
by
Ken Urano
Task-based syllabus design and task sequencing
by
Ken Urano
TBLT in Japan: In search of the middle ground
by
Ken Urano
Types of L2 morphosyntactic knowledge that can and cannot be observed in lea...
by
Ken Urano
ESPカリキュラム開発のためのタスクに基づいたニーズ分析
by
Ken Urano
英語授業を見つめ直す方法: テストデータの見方を知ろう
by
Ken Urano
研究会をひとりでも多くに届ける: ライブ中継や資料共有の方法
by
Ken Urano
タスクを中心にした英語教育は日本で実現可能か—大学におけるライティング授業の事例—
by
Ken Urano
英語オーラル系授業の教室外活動での PoodLLの利用
by
Ken Urano
目的に応じたLMSプラットフォームの選択と利用: 何ができるかではなく何をすべきかを考える
by
Ken Urano
英語教育研究における追試(replication)の必要性
by
Ken Urano
大学の英語ライティング授業における TBLTの導入
by
Ken Urano
Input, interaction, and the roles of Japanese teachers of English: A second l...
by
Ken Urano
英語教育実践と研究の接点 ―研究の在り方と手法―
by
Ken Urano
大学でのオーラル系授業における Glexa の導入
by
Ken Urano
Roles of assistant language teachers and Japanese teachers of English for a s...
by
Ken Urano
有意性と効果量について しっかり考えてみよう
1.
有意性と効果量について しっかり考えてみよう 浦野 研 (北海学園大学) email: urano@hgu.jp /
twitter: @uranoken 外国語教育メディア学会第53回 全国研究大会 2013.08.07. 本日の資料はこちら http://bit.ly/let2013ws 1
2.
本日の資料はウェブで公開しています。 http://bit.ly/let2013ws Or... 2
3.
おことわり 3
4.
•僕は数学が苦手です •でもがんばります •数式が少しだけ出てきます •数学が苦手な方もがんばりましょう 4
5.
さて本題 5
6.
目 標 •効果量と有意性について、その関係と違 いを理解すること •効果量の種類と数値の意味について(な んとなく)把握すること •効果量を計算できるようになること 6
7.
手を挙げて教えてください •効果量を学会発表や論文で報告したこと がある人 •統計ソフトで η2, ω2
などの数値を見た ことがある人 •「え?効果量?なにそれ?」な人 7
8.
有意性と効果量 8
9.
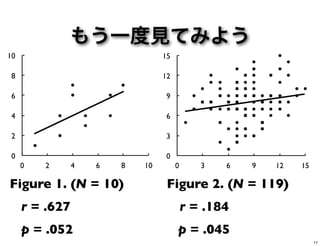
0! 2! 4! 6! 8! 10! 0! 2! 4!
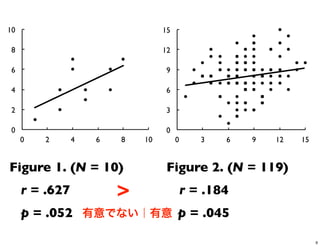
6! 8! 10! 0! 3! 6! 9! 12! 15! 0! 3! 6! 9! 12! 15! Figure 1. (N = 10) Figure 2. (N = 119) r = .627 r = .184 p = .052 p = .045 > 有意でない|有意 9
10.
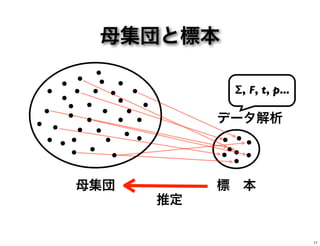
「(統計的)有意」とは •標本(サンプル)から母集団を推定する •標本で観察される差・関係が、母集団には 存在しない確率、つまり偶然の結果である 確率(p 値)を計算する •p 値が基準値(臨界値)以下であれば「有 意」である(偶然でない)と判断する 10
11.
母集団と標本 母集団 標 本 推定 データ解析 Σ, F,
t, p... 11
12.
標本誤差 •ある標本で得られた代表値(e.g., 平 均)と母集団の代表値との差 12
13.
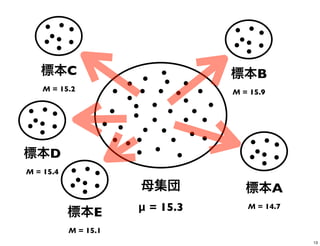
母集団 μ = 15.3 標本A M
= 14.7 標本B M = 15.9 標本C M = 15.2 標本D M = 15.4 標本E M = 15.1 13
14.
標本誤差 •標本のサイズが大きければ大きいほど、 標本誤差は小さくなる •つまり推定の精度が高くなる 14
15.
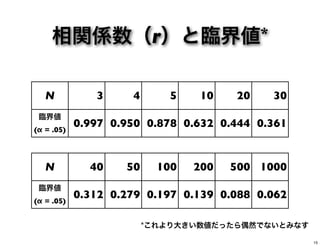
相関係数(r)と臨界値* N 3 4
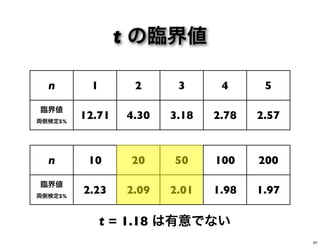
5 10 20 30 臨界値 (α = .05) 0.997 0.950 0.878 0.632 0.444 0.361 N 40 50 100 200 500 1000 臨界値 (α = .05) 0.312 0.279 0.197 0.139 0.088 0.062 *これより大きい数値だったら偶然でないとみなす 15
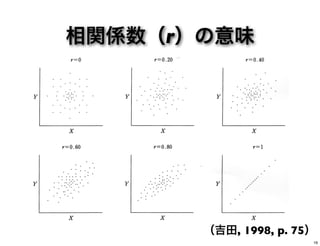
16.
相関係数(r)の意味 (吉田, 1998, p.
75) 16
17.
0! 2! 4! 6! 8! 10! 0! 2! 4!
6! 8! 10! 0! 3! 6! 9! 12! 15! 0! 3! 6! 9! 12! 15! Figure 1. (N = 10) Figure 2. (N = 119) r = .627 r = .184 p = .052 p = .045 もう一度見てみよう 17
18.
有意性検定と標本サイズ 有意な差(または、有意な相関)が得られやすい研究をするための きわめて有効な方法があります。それは、とにかく多くのデータを 集めることです。なぜならば...統計的検定の結果はデータ数が 多いほど有意になりやすいからです。そのため、データ数を増やし さえすれば、きわめて小さな差でも “(統計的には)有意である” という結果になる可能性が高まります。例えば、N =
1000 の場合 には、r = 0.062 というきわめて小さな相関係数(すなわち、非常 に弱い関係)でも有意になります...。このように、統計的推定 には、“データ数という、研究者が任意に決められる要因によって 結果が左右されてしまう” という根本的な問題があります。(吉田, 1998, p. 232; 下線は浦野による) 18
19.
どうする? 19
20.
•差や関係を表す、標本サイズに依存しな い指標がほしい •それが効果量 •実は相関係数 r も効果量の指標です(後 述) 20
21.
効果量の種類 21
22.
大きく分けて2つ •差の大きさを表す指標(d 族) •関係の強さを表す指標(r 族) 22
23.
差の大きさを表す指標 23
24.
とあるテストの結果 52 79 59 55 61
61 76 89 45 51 68 71 63 63 69 41 43 41 51 83 36 93 51 47 39 37 71 52 26 41 70 57 38 64 58 76 48 43 28 90 54 58 58 38 38 38 42 43 47 58 78 60 68 48 40 45 50 24 68 36 Group A Group B どちらの方ができがよい? 24
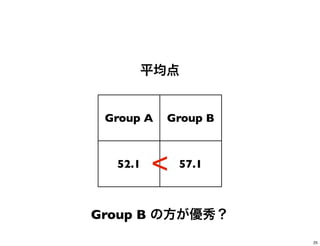
25.
平均点 Group A Group
B 52.1 57.1 Group B の方が優秀? < 25
26.
ちょっと待って! 26
27.
もう少し見てみよう 27
28.
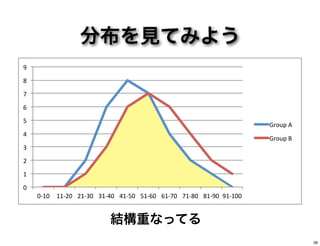
分布を見てみよう 結構重なってる 0" 1" 2" 3" 4" 5" 6" 7" 8" 9" 0,10" 11,20" 21,30"
31,40" 41,50" 51,60" 61,70" 71,80" 81,90" 91,100" Group"A" Group"B" 28
29.
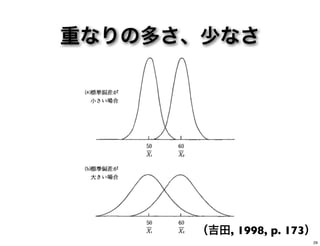
重なりの多さ、少なさ (吉田, 1998, p.
173) 29
30.
重なりの多さ、少なさ 差は同じ (吉田, 1998, p.
173) 30
31.
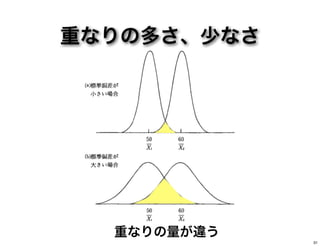
重なりの多さ、少なさ 重なりの量が違う 31
32.
言えそうなこと 重なりが少ない方が差が大きそう 32
33.
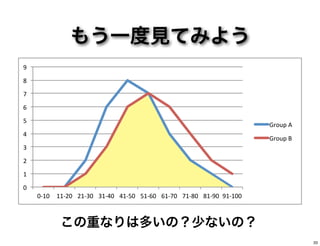
もう一度見てみよう 0" 1" 2" 3" 4" 5" 6" 7" 8" 9" 0,10" 11,20" 21,30"
31,40" 41,50" 51,60" 61,70" 71,80" 81,90" 91,100" Group"A" Group"B" この重なりは多いの?少ないの? 33
34.
指標が欲しい 34
35.
効果量 Cohen’s d 35
36.
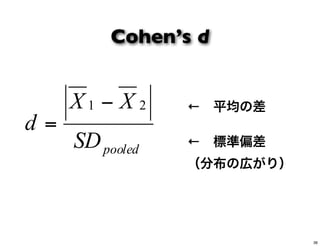
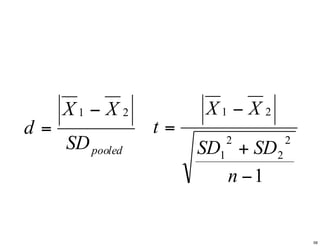
Cohen’s d pooledSD XX d 21 − = ← 平均の差 ← 標準偏差 (分布の広がり) 36
37.
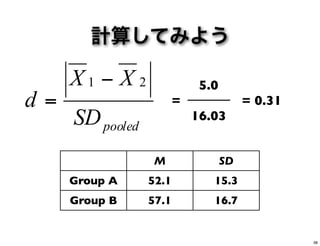
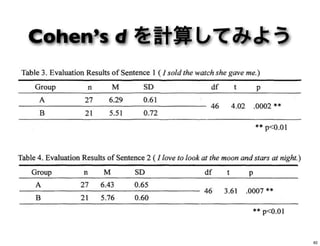
計算してみよう M SD Group A
52.1 15.3 Group B 57.1 16.7 pooledSD XX d 21 − = | 52.1-57.1| = (15.3 + 16.7) / 2* *n が異なるとき、SDpooled の計算はもう少し複雑になります 37
38.
計算してみよう pooledSD XX d 21 − = =
0.31 5.0 = 16.03 M SD Group A 52.1 15.3 Group B 57.1 16.7 38
39.
効果量 d と分布の重なり d
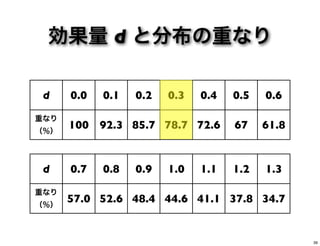
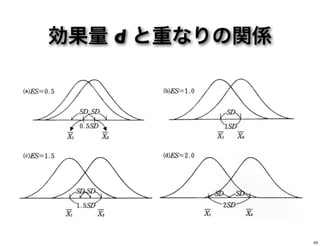
0.0 0.1 0.2 0.3 0.4 0.5 0.6 重なり (%) 100 92.3 85.7 78.7 72.6 67 61.8 d 0.7 0.8 0.9 1.0 1.1 1.2 1.3 重なり (%) 57.0 52.6 48.4 44.6 41.1 37.8 34.7 39
40.
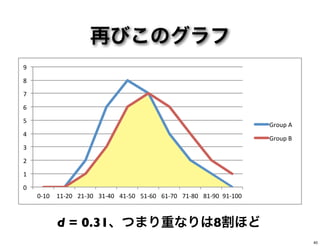
再びこのグラフ 0" 1" 2" 3" 4" 5" 6" 7" 8" 9" 0,10" 11,20" 21,30"
31,40" 41,50" 51,60" 61,70" 71,80" 81,90" 91,100" Group"A" Group"B" d = 0.31、つまり重なりは8割ほど 40
41.
つまり 41
42.
Group AとGroup Bは 平均点に5点差があるけど 全体の8割は重なっている 42
43.
効果量 d と重なりの関係 43
44.
d 値が大きくなるには pooledSD XX d 21 − = ← 小さい方が良い ← 大きい方が良い 44
45.
効果量の解釈 45
46.
Cohen (1969) •small: d
= 0.2, overlap: 85.7% •e.g., 15歳と16歳の女子の身長差 •medium: d = 0.5, overlap: 67.0% •e.g., 14歳と18歳の女子の身長差 •large: d = 0.8, overlap: 52.6% •e.g., 大学新入生とPhD取得者のIQ差 46
47.
ただし 47
48.
•このような指標はあくまで目安 •実際の解釈は研究者自身の責任で 48
49.
効果量と有意性 49
50.
重なりの多さはわかったけど、 この差は偶然? 50
51.
観察された差が偶然である可能性(確率)を 計算しよう 51
52.
t 検定 52
53.
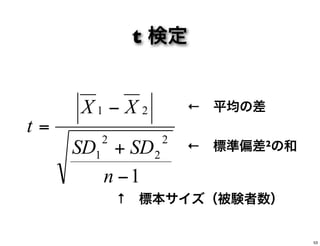
← 平均の差 ← 標準偏差2の和 1 2 2 2 1 21 − + − = n SDSD XX t ↑ 標本サイズ(被験者数) t 検定 53
54.
これさっき見た? 54
55.
Cohen’s d pooledSD XX d 21 − = ← 平均の差 ← 標準偏差 (分布の広がり) これに
n を足すと t っぽい! 55
56.
pooledSD XX d 21 − = 1 2 2 2 1 21 − + − = n SDSD XX t 56
57.
t 値が大きくなるには ← 大きい方が良い ← 小さい方が良い 1 2 2 2 1 21 − + − = n SDSD XX t ↑ 大きいほうが良い 57
58.
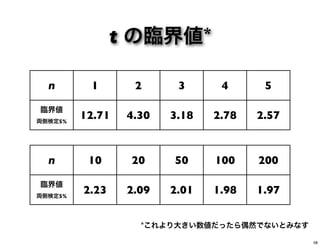
t の臨界値* n 1
2 3 4 5 臨界値 両側検定5% 12.71 4.30 3.18 2.78 2.57 n 10 20 50 100 200 臨界値 両側検定5% 2.23 2.09 2.01 1.98 1.97 *これより大きい数値だったら偶然でないとみなす 58
59.
計算してみよう M SD Group A
52.1 15.3 Group B 57.1 16.7 1 2 2 2 1 21 − + − = n SDSD XX t *n が異なるときの計算はもう少し複雑になります * | 52.1-57.1| = √(15.32 + 16.72) / (30 - 1) 59
60.
計算してみよう M SD Group A
52.1 15.3 Group B 57.1 16.7 5 = 4.21 1 2 2 2 1 21 − + − = n SDSD XX t *n が異なるときの計算はもう少し複雑になります * = 1.18 60
61.
t の臨界値 n 1
2 3 4 5 臨界値 両側検定5% 12.71 4.30 3.18 2.78 2.57 n 10 20 50 100 200 臨界値 両側検定5% 2.23 2.09 2.01 1.98 1.97 t = 1.18 は有意でない 61
62.
ここまでのまとめ 62
63.
•効果量 Cohen’s d •2つのグループ間の差を標準化したもの •t
検定 •効果量に標本誤差の影響を加味して、その差が 偶然観察される確率を示したもの •検定統計量 = 効果の大きさ x 標本の大きさ (南風原, 2002, p. 163) 63
64.
•Cohen’s d の仲間: •Hedges’
g •分母に母集団の標準偏差を使う •Glass’ ⊿ •分母に統制群の標準偏差を使う 64
65.
関係の強さを表す指標 65
66.
•変数間の関係の大きさを表す •最大: 1.0 •最小: 0 •ピアソンの積率相関係数
r •r2 (分散説明率) 66
67.
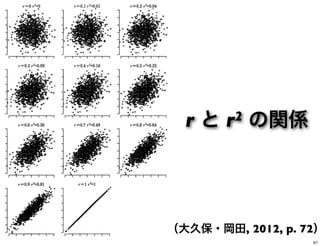
(大久保・岡田, 2012, p.
72) r と r2 の関係 67
68.
分散分析の場合 68
69.
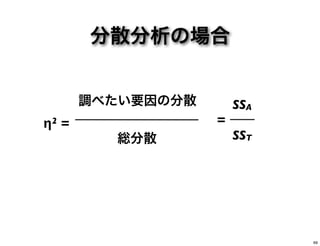
分散分析の場合 調べたい要因の分散 η2 = 総分散 SSA = SST 69
70.
SS df MS
F p η2 A 847.609 2 423.805 0.955 .389 .022 Error 37259.655 84 443.567 Total 38107.264 one-way ANOVA MacR に付属のデータを使って MacR で計算 / = / = 70
71.
SS df MS
F p η2 A 847.609 2 423.805 0.955 .389 .022 Error 37259.655 84 443.567 Total 38107.264 one-way ANOVA / = ↑ 標本サイズが大きいと F 値が大きくなる 71
72.
SS df MS
F p η2 A 847.609 2 423.805 0.955 .389 .022 Error 37259.655 84 443.567 Total 38107.264 one-way ANOVA + = η2 = SSA / SST = 847.609 / 38107.264 = .022 72
73.
効果量の解釈 73
74.
水本・竹内 (2008) •small: η2
= .01 •medium: η2 = .06 •large: η2 = .14 •このような指標はあくまで目安 •実際の解釈は研究者自身の責任で ただし 74
75.
ここまでのまとめ 75
76.
•r 族の効果量 •変数間の関係の強さを数値で示したもの •最大で 1.0、最小で
0 •分散分析で使う η2 は r2 と似た感じ •F と η2 の違いは標本サイズを考慮するかどうか •検定統計量 = 効果の大きさ x 標本の大きさ (南風原, 2002, p. 163) 76
77.
•η2 の仲間: •partial η2 •分母に
SSA + SSE を使う •ω2 •母分散推定のためのバイアスを取り除 いたもの 77
78.
さて 78
79.
計算してみましょうか 79
80.
効果量の計算のシート http://www.mizumot.com/stats/effectsize.xls 80
81.
Language Education &
Technology, 46, 41–60 (2009) 81
82.
Cohen’s d を計算してみよう 82
83.
Language Education &
Technology, 42, 111–118 (2005) 83
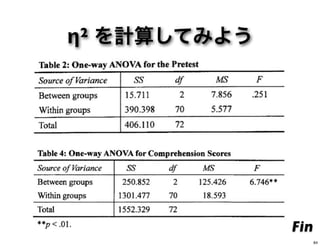
84.
η2 を計算してみよう Fin 84
Download