More Related Content

PDF

PDF
2 5 2.一般化線形モデル色々_ロジスティック回帰 
PDF

PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM) 
PDF

PPTX

PPTX

PDF
What's hot

PDF

PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章) 
PDF

PDF

PDF

PDF
状態空間モデルの考え方・使い方 - TokyoR #38 
PPTX

PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章 
PDF

PDF

PPTX
rstanで簡単にGLMMができるglmmstan()を作ってみた 
PPTX

PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話) 
PDF

PPTX

PDF

PPTX

PDF
Bayesian Neural Networks : Survey 
PDF

PDF
DARM勉強会第3回 (missing data analysis) Similar to 20180118 一般化線形モデル(glm)

PPTX

PDF

PPTX
Doing Bayesian Data Analysis; Chapter 14 
PDF

PPTX

PPTX

PPTX

PDF
2 5 3.一般化線形モデル色々_Gamma回帰と対数線形モデル 
PDF
MLaPP 9章 「一般化線形モデルと指数型分布族」 
PDF

PDF

PDF
データ解析のための統計モデリング入門3章後半 ![[PRML] パターン認識と機械学習(第1章:序論)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter1-170903070406-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[PRML] パターン認識と機械学習(第1章:序論) 
PDF

PDF

PPTX
(実験心理学徒だけど)一般化線形混合モデルを使ってみた 
PDF
データ解析のための統計モデリング入門 6.5章 後半 
PDF

PDF

PDF
More from Masakazu Shinoda

PDF
Ml desginpattern 16_stateless_serving_function_21210511 
PDF
Ml desginpattern 12_checkpoints_21210427 
PPTX

PPTX

PDF

PDF
Network weight saving_20190123 
PDF
Batch normalization effectiveness_20190206 
PDF
Perception distortion-tradeoff 20181128 
PDF
20180118 一般化線形モデル(glm)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
一般化線形モデル - 線形予測子
デザイン行列は0 または 1 のように因子で構成されることも、1.2
や 2.3 などのようにパラメーターの加重として構成されることもで
きる。
-> デザイン行列を因子とするか、加重とするかは解析するデータ
の特徴に合わせて決める必要がある。
同じデータに対して、どんな結果を期待したいかによってもデザイ
ン行列の作り方が異なってくる。
-> どんな結果を期待しているのかを予め決定した上で実験を行う
べき。
- 22.
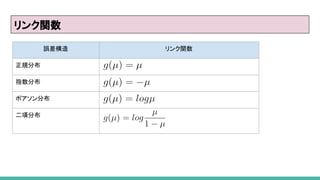
リンク関数
従属変数が正規分布に従わないとき、E[Y] = Xβの式でモデル化
すると、正確さが失われる。
-> そこで、従属変数をある関数 G で変換してから、モデル化する
ことで、モデルの正確さが向上する。
G(E[Y]) = Xβ
関数 G はリンク関数と呼ばれている。
一般に、誤差構造が決まれば、リンク関数も自動的に決まること
が多い。
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
AICは予測の良さを重視
モデル選択基準に AIC(Akaike's informationcriterion)を考え
る。AICはモデルの当てはまりの良さ(goodness of fit)ではなく予
測の良さ(goodness of prediction)を重視するモデル選択基準。
パラメータ数kとすると
AIC= -2{(最大対数尤度)-(最尤推定したパラメータ数)}
= -2(log L^* - k)
= D+2k →AICが最小のモデルが良いモデル。
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
RのGLM用関数
glm(モデル式, family =目的変数の分布, data = データフレーム)
リンク関数も指定する場合
glm(モデル式, family = 目的変数の分布(link = リンク関数), data = データフレーム)
glm() デフォルトで組み込まれている一般化線形モデルの関数
glmnet() パッケージ{glmnet}に含まれるElastic Net(Ridge+Lasso)を実装
した一般化線形モデル
- 40.
- 41.
- 42.
- 43.








![何を拡張するのか
拡張ポイント1:観測値の分散
正規分布の必要はなく、指数分布族に従えば良い。
(ポアソン分布,二項分布,ガンマ分布など)
拡張ポイント2:線形でなく、線形を関数で処理する
期待値 ( ) に関して ( ) = ( b)
( )は指数関数やロジスティック関数などの「単調関数」
( )の逆関数をリンク関数と呼ぶ。
これを と記すと [E(y)] = b
期待値 ( ) をリンク関数で変換したものが線形関数。](https://image.slidesharecdn.com/20180118glm-180115101834/85/20180118-glm-11-320.jpg)










![リンク関数
従属変数が正規分布に従わないとき、E[Y] = Xβ の式でモデル化
すると、正確さが失われる。
-> そこで、従属変数をある関数 G で変換してから、モデル化する
ことで、モデルの正確さが向上する。
G(E[Y]) = Xβ
関数 G はリンク関数と呼ばれている。
一般に、誤差構造が決まれば、リンク関数も自動的に決まること
が多い。](https://image.slidesharecdn.com/20180118glm-180115101834/85/20180118-glm-22-320.jpg)