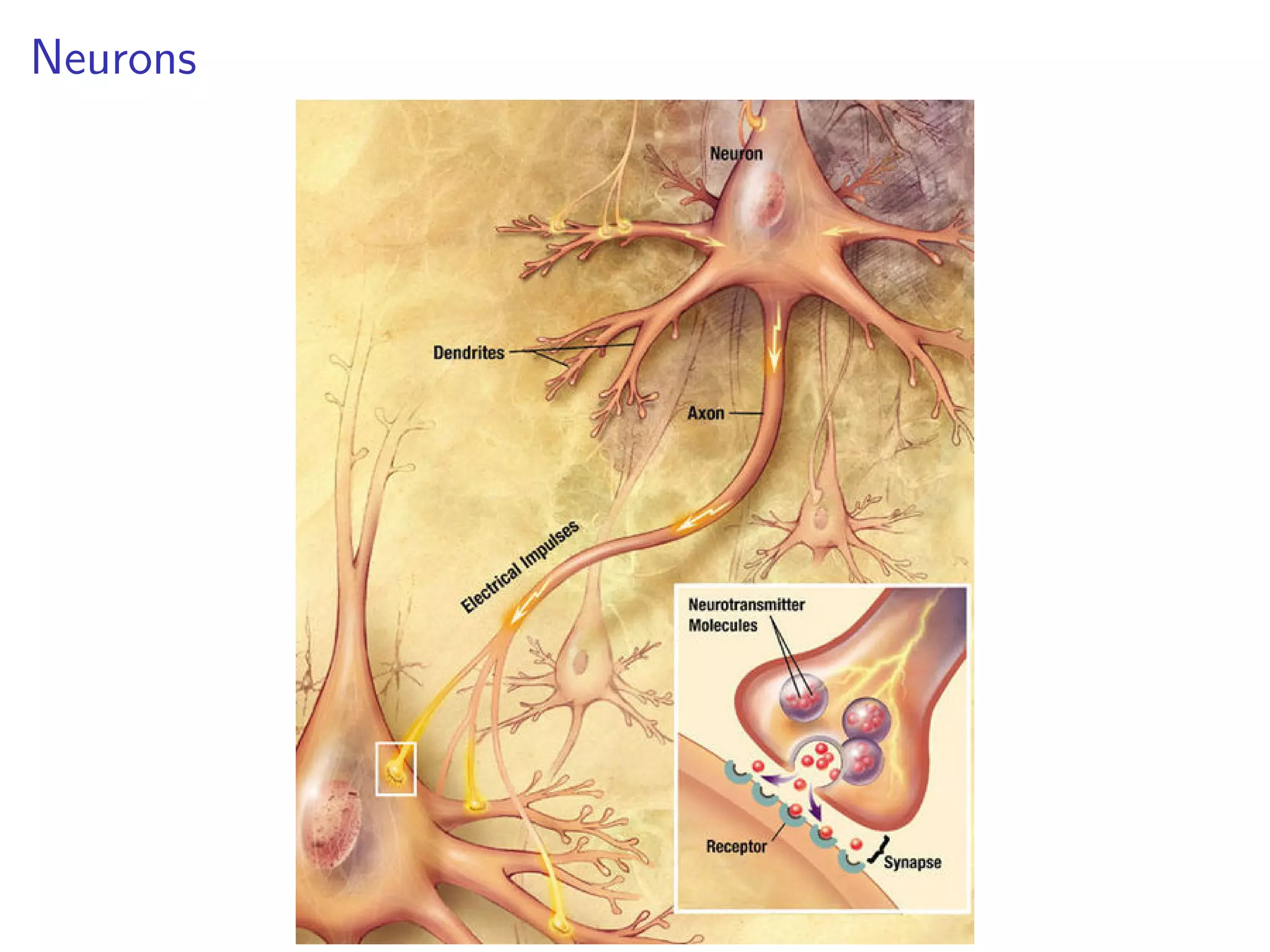
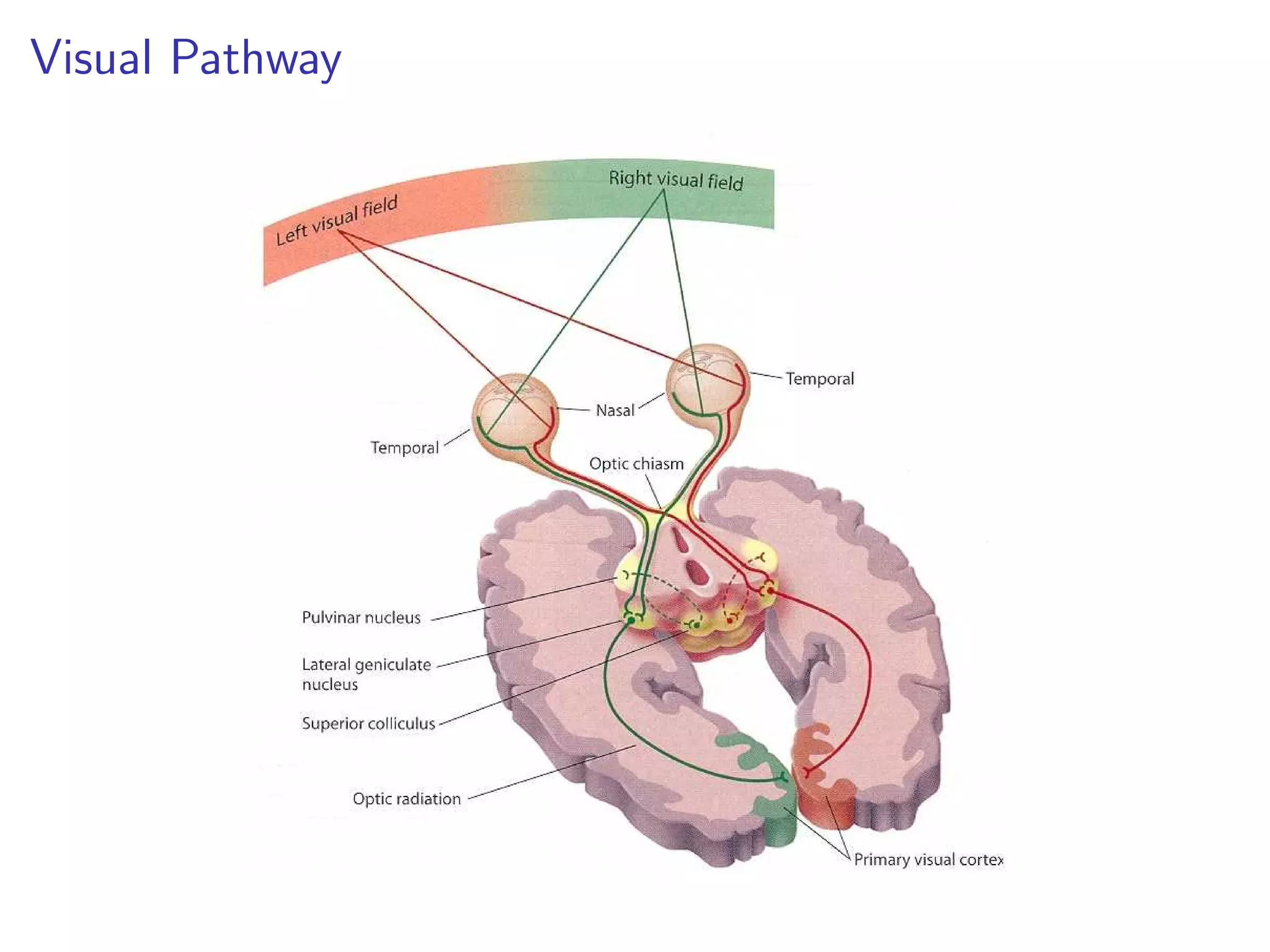
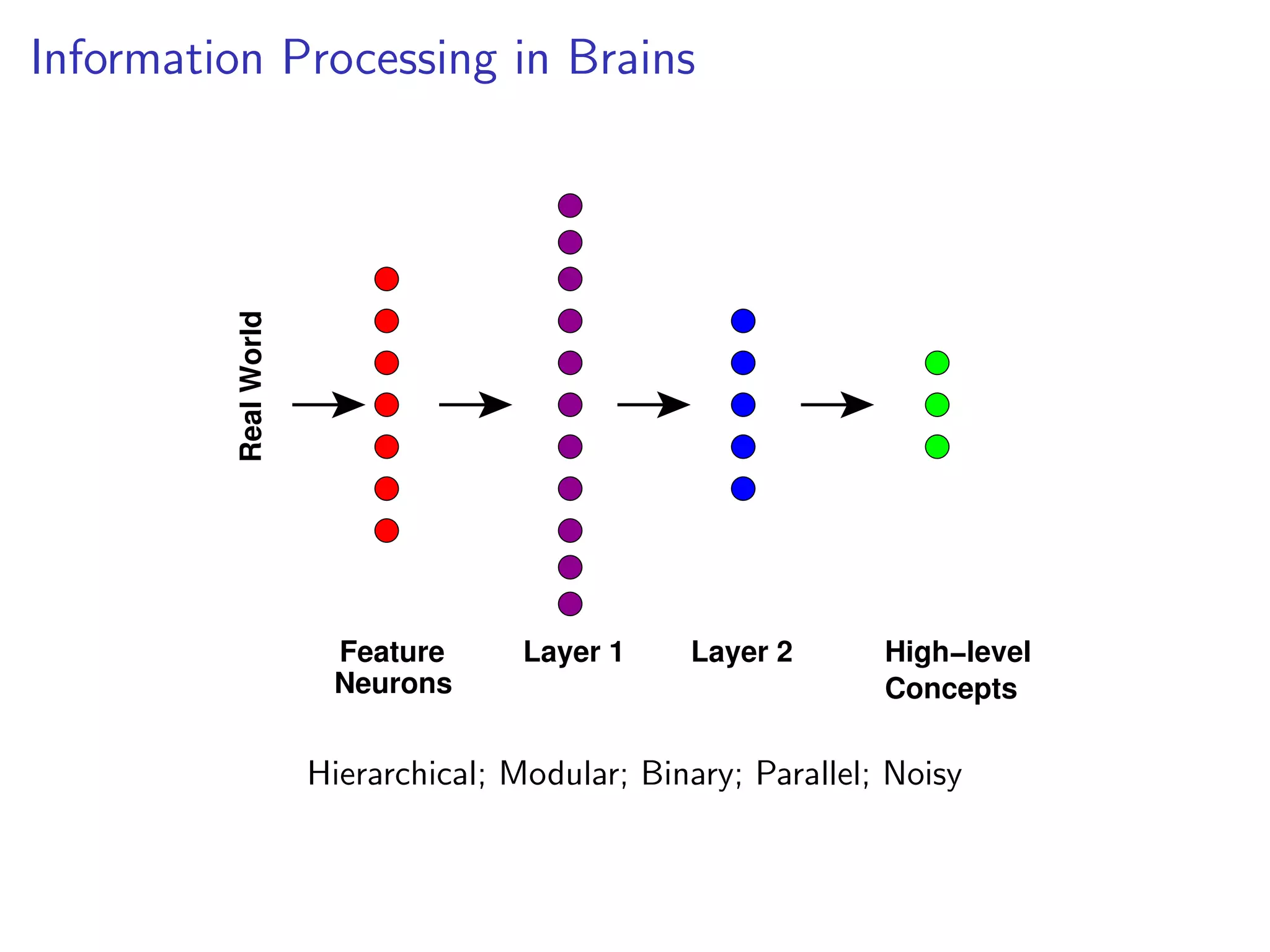
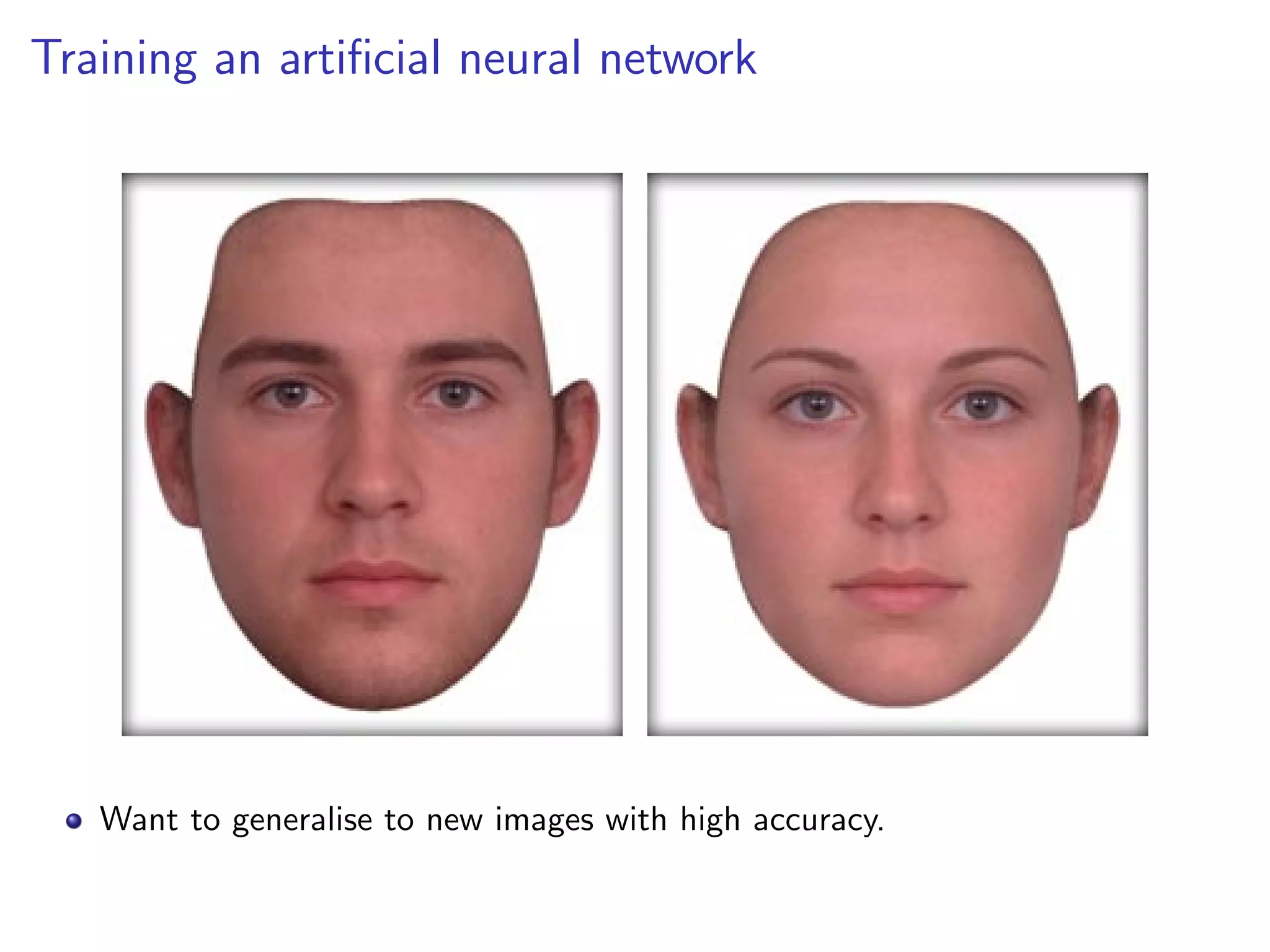
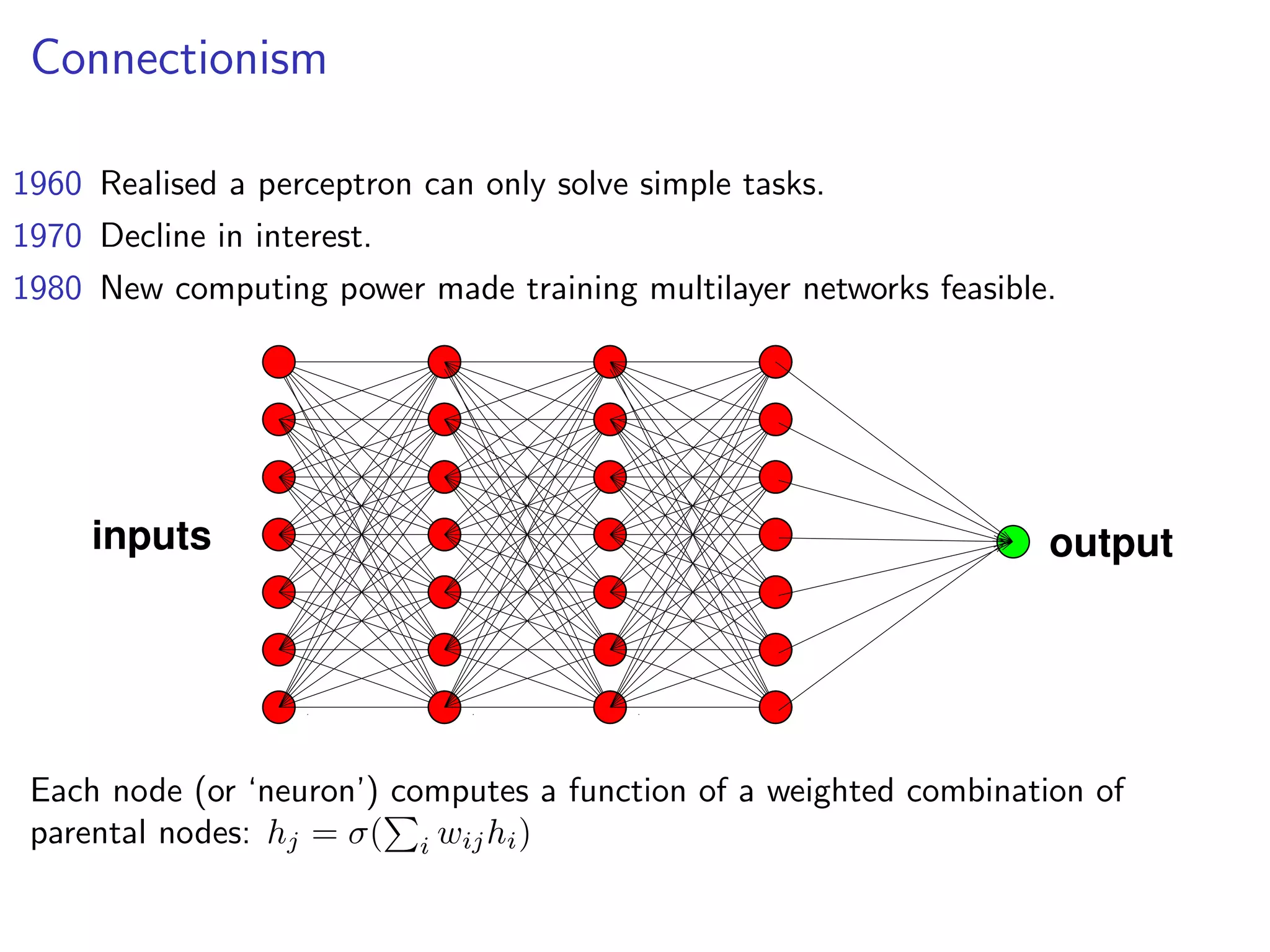
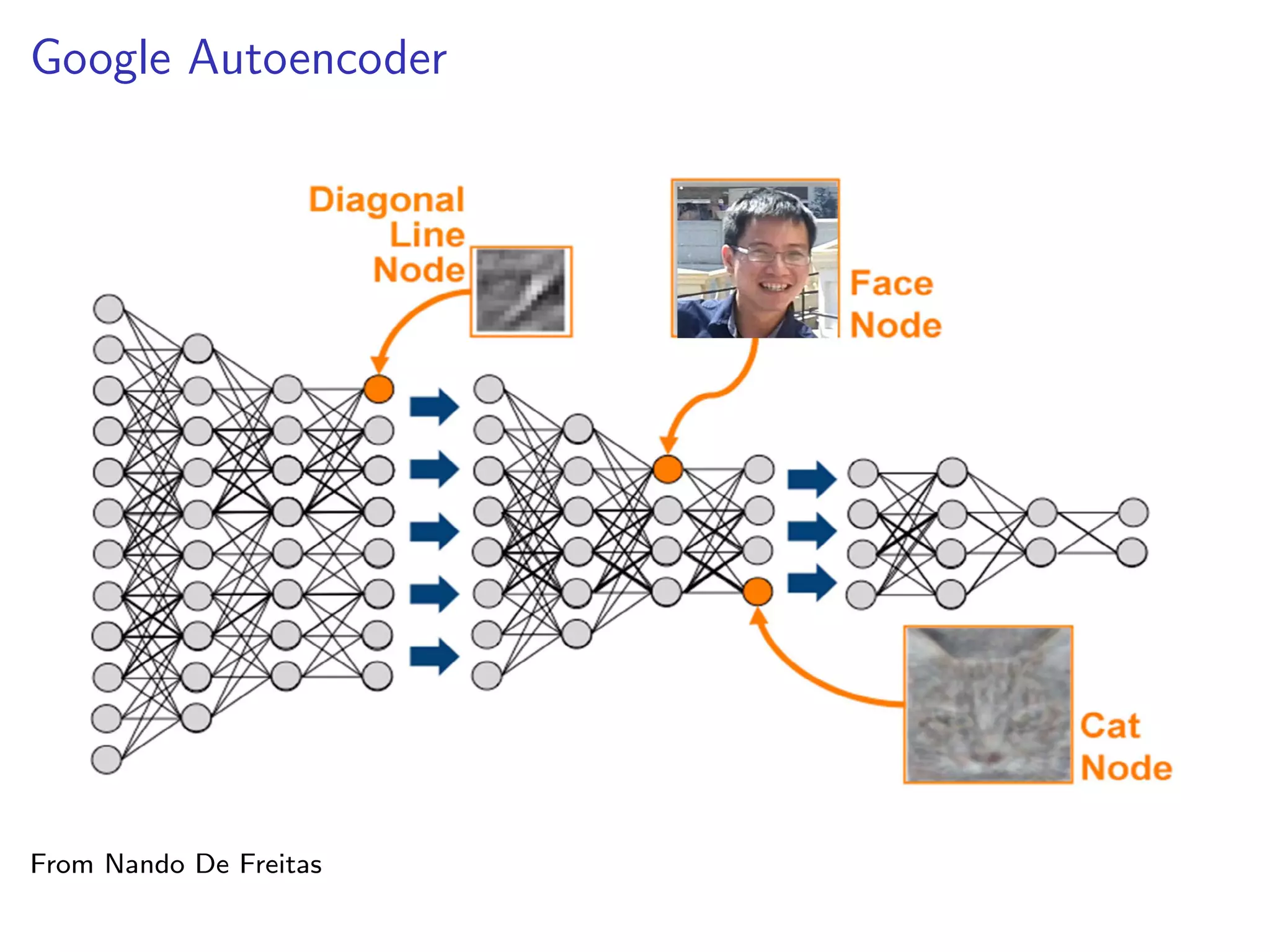
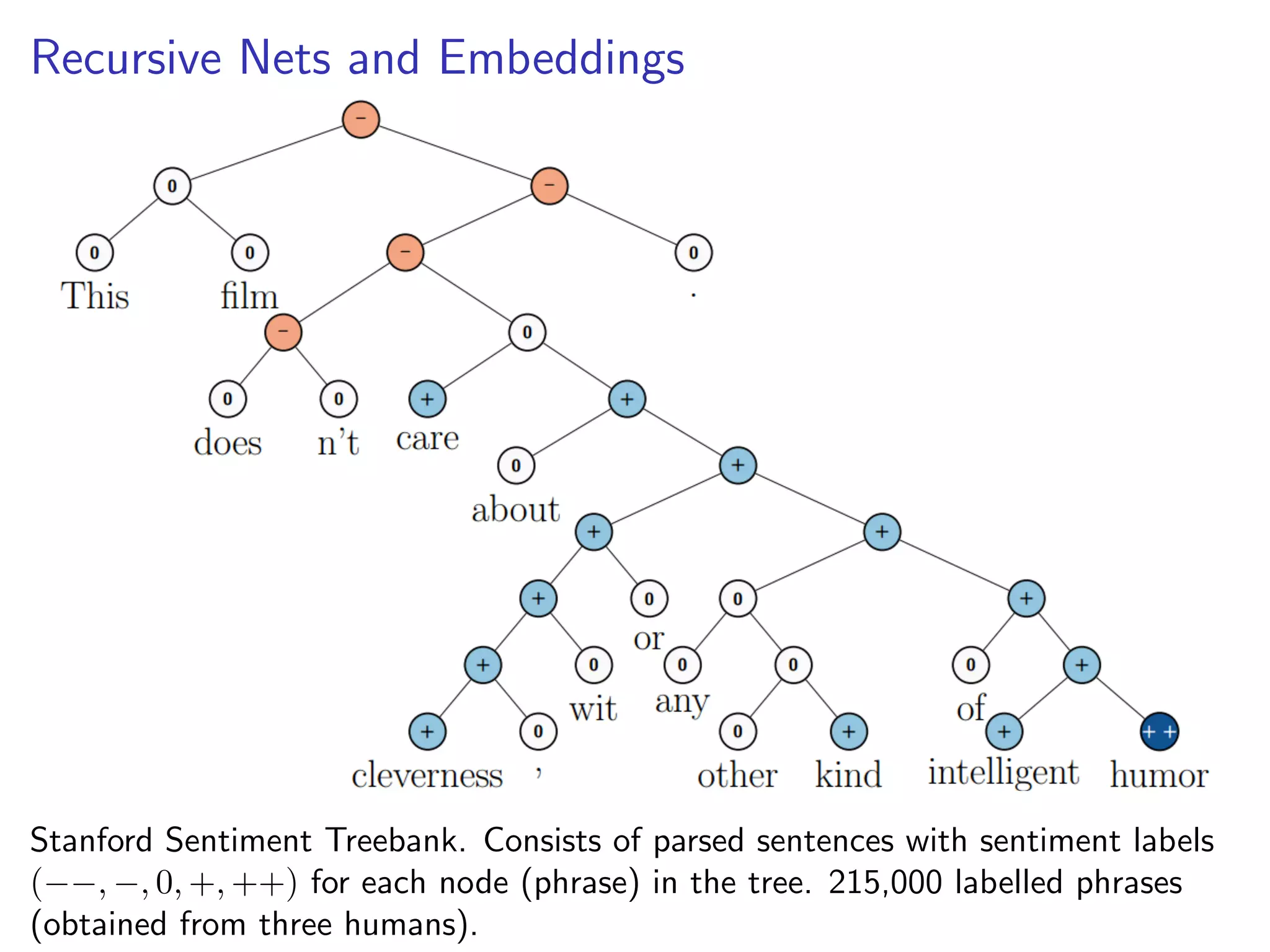
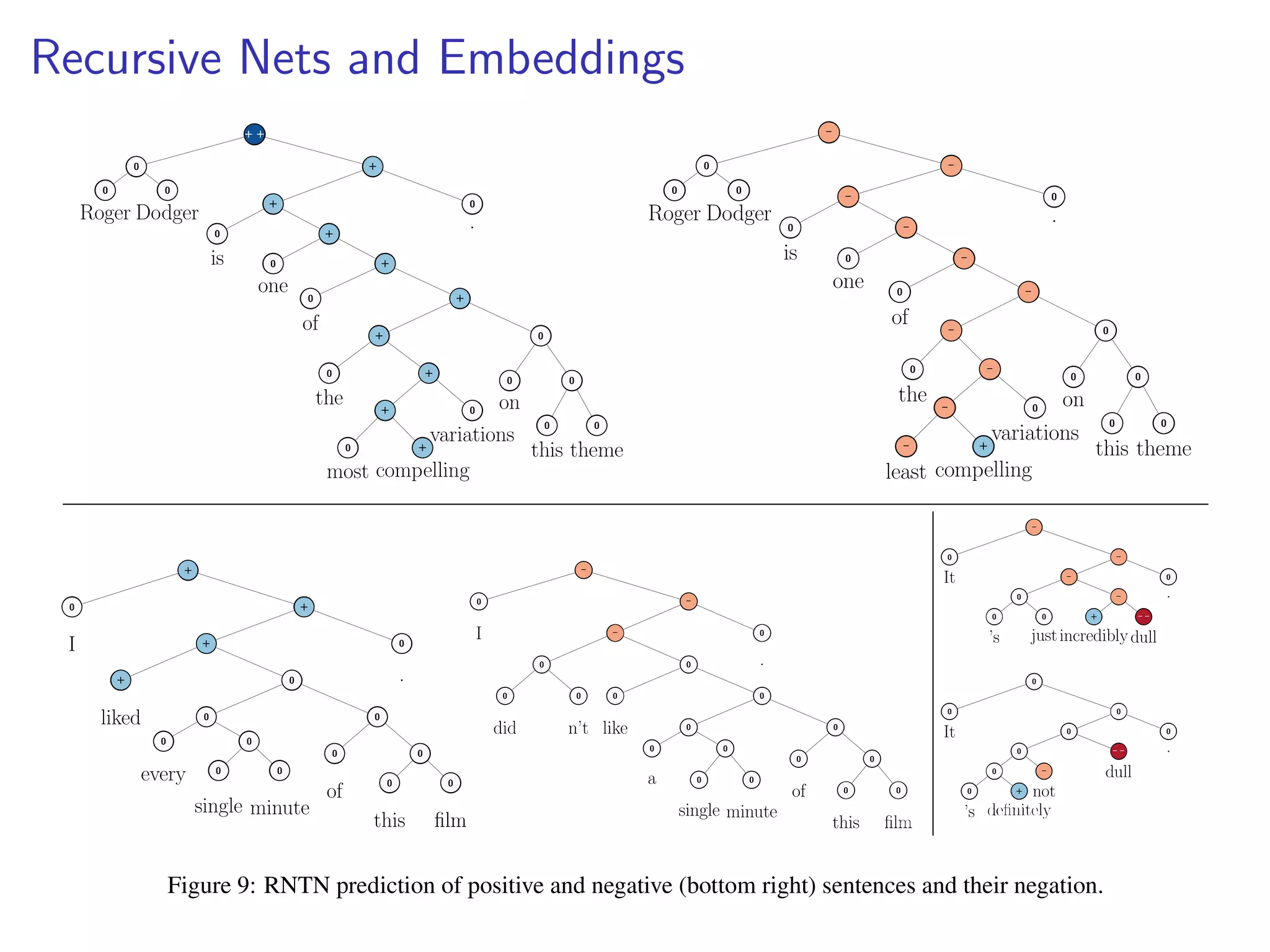
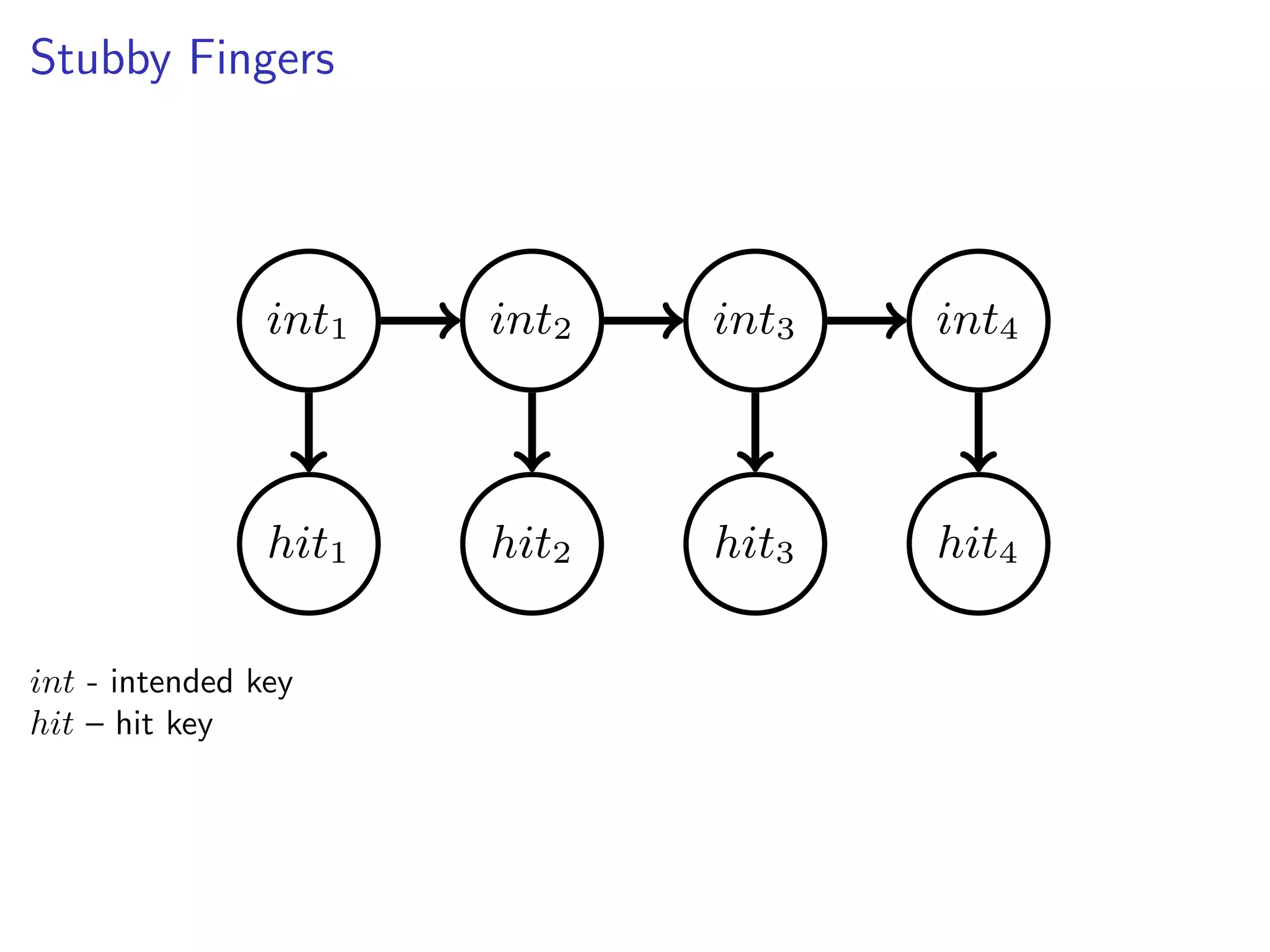
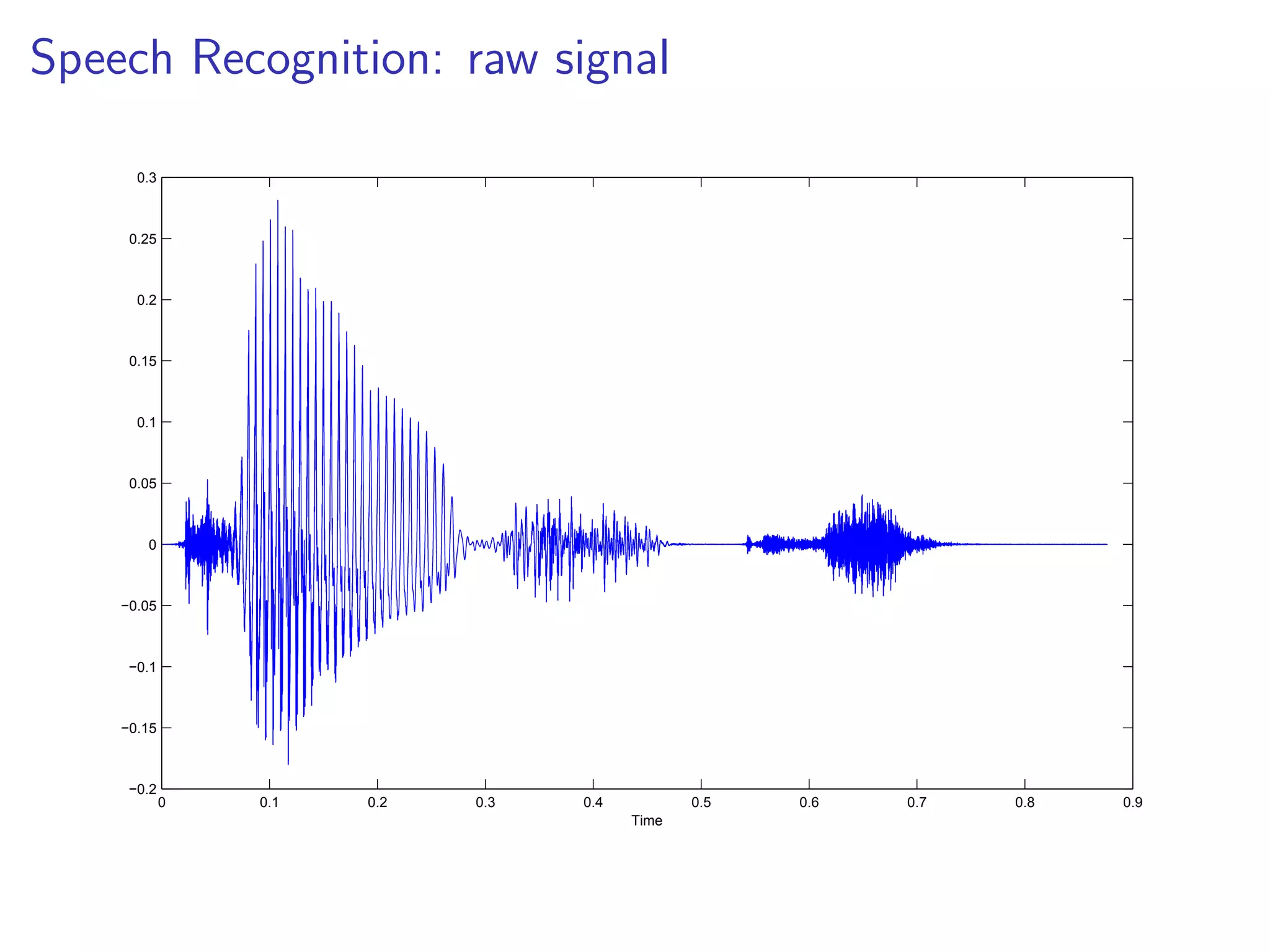
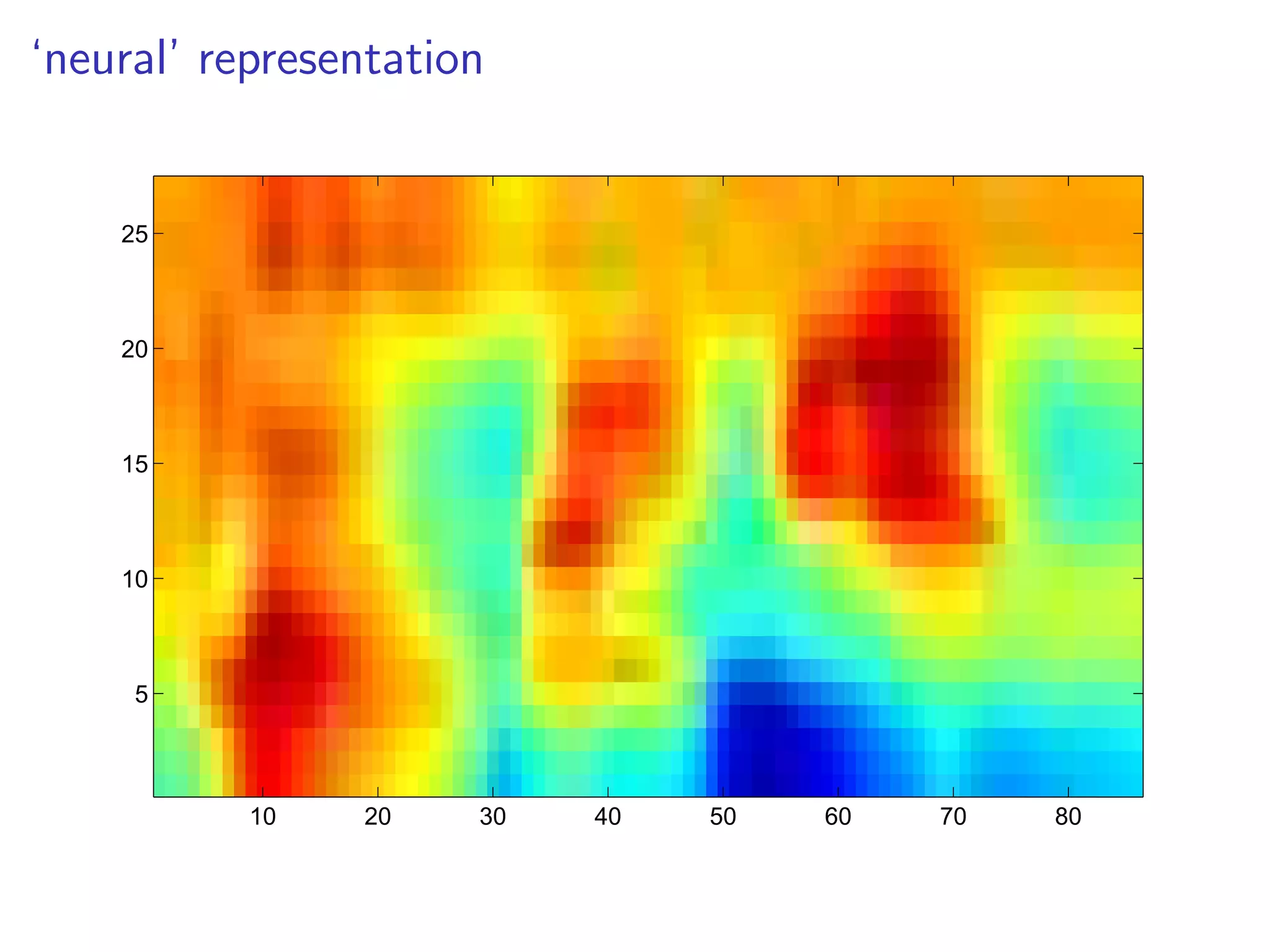
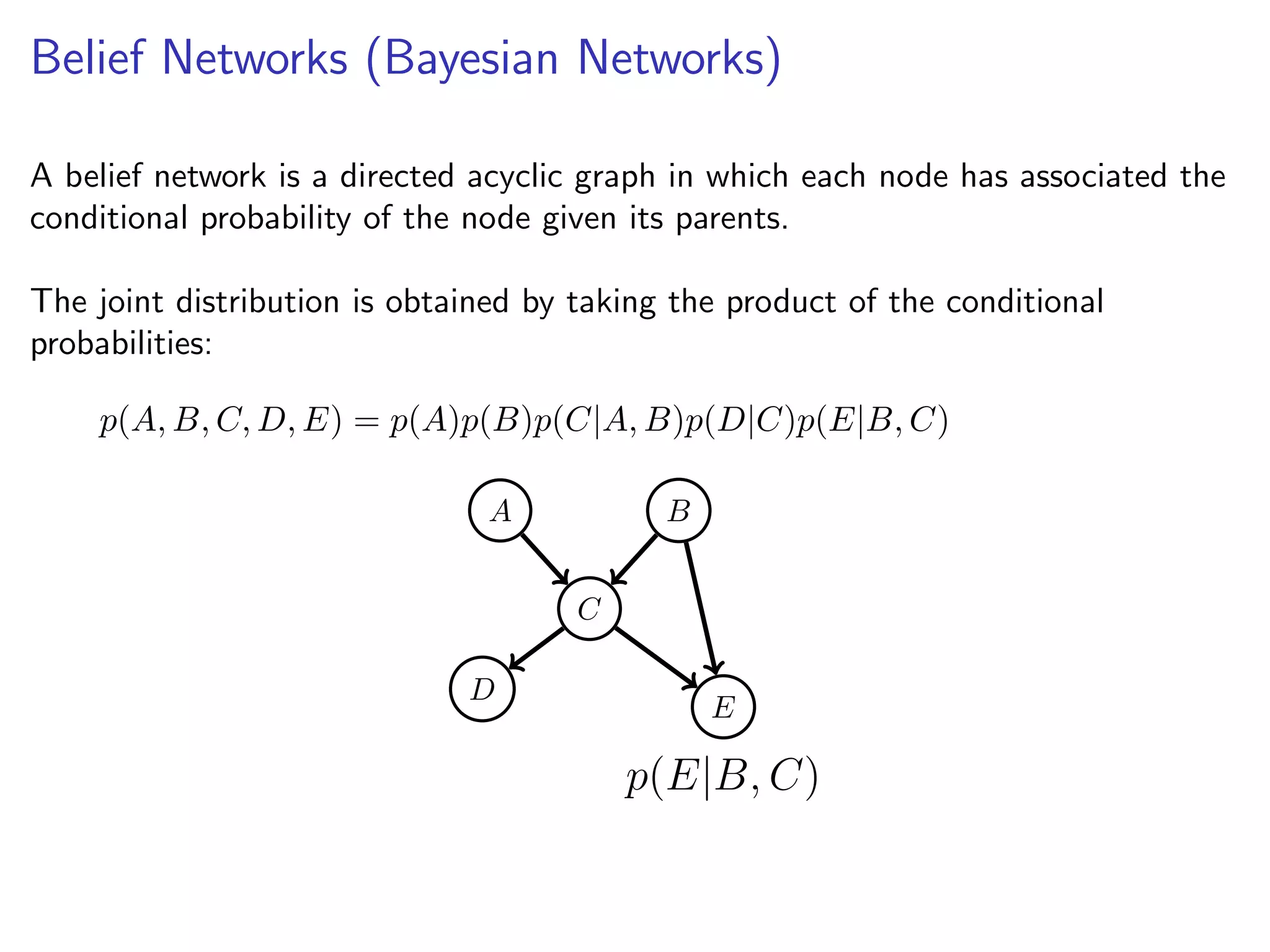
This document discusses the history and recent developments in artificial intelligence and deep learning. It covers early work in neural networks from the 1950s through the 1990s, including perceptrons, autoencoders, and connectionism. More recent progress is attributed to greater computing power, larger datasets, and the development of automatic differentiation techniques. Applications discussed include computer vision, natural language processing using word embeddings, and recurrent neural networks for tasks like handwriting generation.

















































































![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)


![[PR12] intro. to gans jaejun yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12intro-170416162251-thumbnail.jpg?width=640&height=640&fit=bounds)
















![[PR12] Spectral Normalization for Generative Adversarial Networks](https://cdn.slidesharecdn.com/ss_thumbnails/pr12spectralnormalizationforgans-180513142600-thumbnail.jpg?width=640&height=640&fit=bounds)











































